Model Interpretation and Explainability: Towards Creating Transparency in Prediction Models
2405.20794
0
0
📈
Abstract
Explainable AI (XAI) has a counterpart in analytical modeling which we refer to as model explainability. We tackle the issue of model explainability in the context of prediction models. We analyze a dataset of loans from a credit card company and apply three stages: execute and compare four different prediction methods, apply the best known explainability techniques in the current literature to the model training sets to identify feature importance (FI) (static case), and finally to cross-check whether the FI set holds up under what if prediction scenarios for continuous and categorical variables (dynamic case). We found inconsistency in FI identification between the static and dynamic cases. We summarize the state of the art in model explainability and suggest further research to advance the field.
Create account to get full access
Overview
- The paper explores the issue of model explainability in the context of prediction models, using a dataset of loans from a credit card company.
- The researchers executed and compared four different prediction methods, applied explainability techniques to the model training sets to identify feature importance (FI) in a static case, and then cross-checked the FI set under "what-if" prediction scenarios for continuous and categorical variables (dynamic case).
- The researchers found inconsistencies in FI identification between the static and dynamic cases, and summarized the state of the art in model explainability while suggesting further research to advance the field.
Plain English Explanation
When machine learning models make predictions, it's important to understand how they arrive at those predictions. This is known as model explainability. The researchers in this paper looked at this issue in the context of loan prediction models.
They started by testing several different machine learning models on a dataset of credit card loans to see which ones performed the best. Then, they applied techniques like T-Explainer, Unified Explanations, and Causal-LIME to understand which features of the loan data were most important in driving the predictions.
However, they found that the importance of these features changed when they started making "what-if" changes to the loan data, either by adjusting continuous variables (like income) or switching categorical variables (like employment status). This suggested that the initial feature importance rankings weren't as reliable as they had hoped.
The researchers concluded that more work is needed to develop robust and reliable methods for explaining how machine learning models make their predictions, especially when dealing with complex, real-world datasets. They pointed to some promising recent research like Explainable AI for Wildfire Prediction and Counterfactual Explanations as potential ways to address these challenges.
Technical Explanation
The researchers used a dataset of loans from a credit card company to explore the issue of model explainability. They first executed and compared the performance of four different prediction models: logistic regression, decision trees, random forests, and gradient boosting. They then applied state-of-the-art explainability techniques to these models to identify the most important features driving the predictions.
Specifically, they used methods like T-Explainer, Unified Explanations, and Causal-LIME to determine feature importance (FI) in a "static" case, where the model was simply applied to the original training data.
However, the researchers then went a step further and looked at "dynamic" cases, where they made changes to both continuous and categorical variables in the loan data and observed how the FI rankings changed. They found significant inconsistencies between the static and dynamic analyses, suggesting that the initial FI rankings were not as reliable as they had hoped.
Critical Analysis
The researchers acknowledge several key limitations in their work. First, they only explored a single dataset, so it's unclear how generalizable their findings are to other prediction problems. Additionally, they only used a limited set of explainability techniques, and it's possible that other methods could yield different insights.
Furthermore, the researchers don't delve deeply into the reasons why the FI rankings changed so much between the static and dynamic analyses. More investigation is needed to understand the underlying factors driving these inconsistencies, which could provide important clues for improving model explainability.
It's also worth noting that the researchers' focus is primarily on statistical model interpretability, rather than the deeper philosophical and ethical questions surrounding the use of AI systems. Issues like algorithmic bias, transparency, and accountability are also crucial considerations when deploying AI-powered decision-making systems.
Conclusion
This paper highlights the ongoing challenges in making machine learning models more transparent and explainable. While techniques like T-Explainer, Unified Explanations, and Causal-LIME can provide valuable insights, the researchers found that these methods may not be as reliable as previously thought, especially when dealing with complex, real-world datasets.
Further research is needed to develop more robust and comprehensive approaches to model explainability, particularly in areas like Explainable AI for Wildfire Prediction and Counterfactual Explanations. By improving our ability to understand and validate the decision-making processes of AI systems, we can build more trustworthy and accountable technologies that better serve the needs of society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Privacy Implications of Explainable AI in Data-Driven Systems
Fatima Ezzeddine
0
0
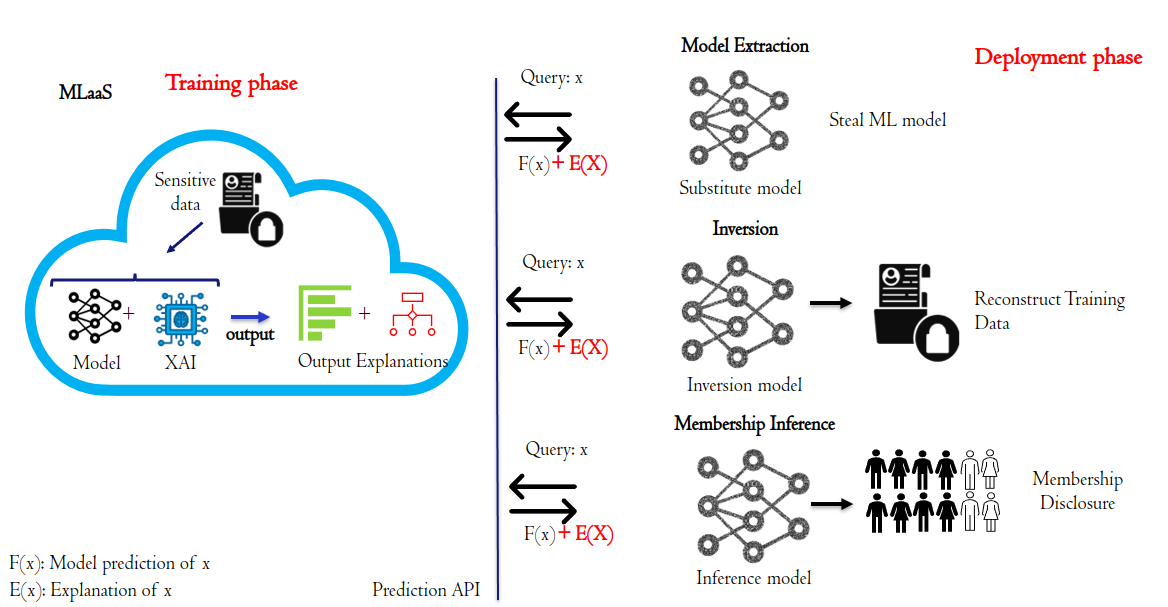
Machine learning (ML) models, demonstrably powerful, suffer from a lack of interpretability. The absence of transparency, often referred to as the black box nature of ML models, undermines trust and urges the need for efforts to enhance their explainability. Explainable AI (XAI) techniques address this challenge by providing frameworks and methods to explain the internal decision-making processes of these complex models. Techniques like Counterfactual Explanations (CF) and Feature Importance play a crucial role in achieving this goal. Furthermore, high-quality and diverse data remains the foundational element for robust and trustworthy ML applications. In many applications, the data used to train ML and XAI explainers contain sensitive information. In this context, numerous privacy-preserving techniques can be employed to safeguard sensitive information in the data, such as differential privacy. Subsequently, a conflict between XAI and privacy solutions emerges due to their opposing goals. Since XAI techniques provide reasoning for the model behavior, they reveal information relative to ML models, such as their decision boundaries, the values of features, or the gradients of deep learning models when explanations are exposed to a third entity. Attackers can initiate privacy breaching attacks using these explanations, to perform model extraction, inference, and membership attacks. This dilemma underscores the challenge of finding the right equilibrium between understanding ML decision-making and safeguarding privacy.
6/26/2024
📉
T-Explainer: A Model-Agnostic Explainability Framework Based on Gradients
Evandro S. Ortigossa, F'abio F. Dias, Brian Barr, Claudio T. Silva, Luis Gustavo Nonato
0
0
The development of machine learning applications has increased significantly in recent years, motivated by the remarkable ability of learning-powered systems to discover and generalize intricate patterns hidden in massive datasets. Modern learning models, while powerful, often exhibit a level of complexity that renders them opaque black boxes, resulting in a notable lack of transparency that hinders our ability to decipher their decision-making processes. Opacity challenges the interpretability and practical application of machine learning, especially in critical domains where understanding the underlying reasons is essential for informed decision-making. Explainable Artificial Intelligence (XAI) rises to meet that challenge, unraveling the complexity of black boxes by providing elucidating explanations. Among the various XAI approaches, feature attribution/importance XAI stands out for its capacity to delineate the significance of input features in the prediction process. However, most existing attribution methods have limitations, such as instability, when divergent explanations may result from similar or even the same instance. In this work, we introduce T-Explainer, a novel local additive attribution explainer based on Taylor expansion endowed with desirable properties, such as local accuracy and consistency, while stable over multiple runs. We demonstrate T-Explainer's effectiveness through benchmark experiments with well-known attribution methods. In addition, T-Explainer is developed as a comprehensive XAI framework comprising quantitative metrics to assess and visualize attribution explanations.
4/26/2024

Unified Explanations in Machine Learning Models: A Perturbation Approach
Jacob Dineen, Don Kridel, Daniel Dolk, David Castillo
0
0
A high-velocity paradigm shift towards Explainable Artificial Intelligence (XAI) has emerged in recent years. Highly complex Machine Learning (ML) models have flourished in many tasks of intelligence, and the questions have started to shift away from traditional metrics of validity towards something deeper: What is this model telling me about my data, and how is it arriving at these conclusions? Inconsistencies between XAI and modeling techniques can have the undesirable effect of casting doubt upon the efficacy of these explainability approaches. To address these problems, we propose a systematic, perturbation-based analysis against a popular, model-agnostic method in XAI, SHapley Additive exPlanations (Shap). We devise algorithms to generate relative feature importance in settings of dynamic inference amongst a suite of popular machine learning and deep learning methods, and metrics that allow us to quantify how well explanations generated under the static case hold. We propose a taxonomy for feature importance methodology, measure alignment, and observe quantifiable similarity amongst explanation models across several datasets.
5/31/2024
🗣️
Causality-Aware Local Interpretable Model-Agnostic Explanations
Martina Cinquini, Riccardo Guidotti
0
0
A main drawback of eXplainable Artificial Intelligence (XAI) approaches is the feature independence assumption, hindering the study of potential variable dependencies. This leads to approximating black box behaviors by analyzing the effects on randomly generated feature values that may rarely occur in the original samples. This paper addresses this issue by integrating causal knowledge in an XAI method to enhance transparency and enable users to assess the quality of the generated explanations. Specifically, we propose a novel extension to a widely used local and model-agnostic explainer, which encodes explicit causal relationships within the data surrounding the instance being explained. Extensive experiments show that our approach overcomes the original method in terms of faithfully replicating the black-box model's mechanism and the consistency and reliability of the generated explanations.
4/16/2024