Unified Explanations in Machine Learning Models: A Perturbation Approach
2405.20200
0
0

Abstract
A high-velocity paradigm shift towards Explainable Artificial Intelligence (XAI) has emerged in recent years. Highly complex Machine Learning (ML) models have flourished in many tasks of intelligence, and the questions have started to shift away from traditional metrics of validity towards something deeper: What is this model telling me about my data, and how is it arriving at these conclusions? Inconsistencies between XAI and modeling techniques can have the undesirable effect of casting doubt upon the efficacy of these explainability approaches. To address these problems, we propose a systematic, perturbation-based analysis against a popular, model-agnostic method in XAI, SHapley Additive exPlanations (Shap). We devise algorithms to generate relative feature importance in settings of dynamic inference amongst a suite of popular machine learning and deep learning methods, and metrics that allow us to quantify how well explanations generated under the static case hold. We propose a taxonomy for feature importance methodology, measure alignment, and observe quantifiable similarity amongst explanation models across several datasets.
Create account to get full access
Overview
- This paper introduces a new approach called "Unified Explanations" for providing interpretable and faithful explanations of machine learning models.
- The approach uses a perturbation-based technique to generate explanations that are consistent across different input samples and model types.
- The proposed method aims to address the limitations of existing local interpretation methods, which can produce explanations that are unstable or inconsistent.
Plain English Explanation
The paper presents a new way to explain machine learning models in a more consistent and reliable manner. Current methods for explaining model decisions can sometimes produce explanations that vary a lot depending on the specific input or model being used.
The authors' "Unified Explanations" approach tries to address this by using a perturbation-based technique to generate explanations. This makes the explanations more stable and consistent across different inputs and model types. The key idea is to perturb or slightly modify the input in a controlled way, and then observe how the model's output changes. This provides insights into which parts of the input are most influential for the model's predictions.
By generating more reliable and interpretable explanations, the authors hope to improve trust and transparency in complex machine learning systems. This could be particularly valuable in high-stakes applications where it's important to understand how a model is making decisions.
Technical Explanation
The paper introduces a new method called "Unified Explanations" for generating interpretable explanations of machine learning model behavior. The core idea is to use a perturbation-based approach to produce explanations that are consistent across different input samples and model types.
The authors first define a perturbation function that can be used to systematically modify the input to a model. They then propose an optimization-based procedure to find the perturbations that maximize the change in the model's output. The resulting perturbations are used to compute feature importance scores, which form the basis of the unified explanations.
Through experiments on various datasets and model architectures, the authors demonstrate that their unified explanations are more stable and consistent compared to explanations generated by local interpretation methods like LIME and SHAP. They also show that the unified explanations are faithful to the underlying model, meaning they accurately reflect the model's decision-making process.
Critical Analysis
The paper makes a compelling case for the need to improve the consistency and reliability of model explanations, which is an important challenge in the field of interpretable machine learning. The proposed unified explanations approach seems promising, as it addresses some of the key limitations of existing local interpretation methods.
However, the paper could have provided more discussion on the potential limitations and caveats of the unified explanations approach. For example, the perturbation-based technique may not work as well for models with highly nonlinear or discontinuous decision boundaries, and the method may be more computationally intensive compared to simpler local explanation methods.
Additionally, the authors could have explored the potential biases or inaccuracies that could arise from the perturbation-based approach, and how these might be mitigated. It would also be valuable to see the unified explanations method applied to a wider range of real-world use cases to better understand its practical implications and limitations.
Overall, the paper makes a valuable contribution to the field of interpretable machine learning, and the unified explanations approach represents an interesting and promising direction for further research and development.
Conclusion
This paper introduces a new method called "Unified Explanations" that aims to generate more consistent and reliable explanations of machine learning model behavior. The key innovation is the use of a perturbation-based technique to compute feature importance scores, which are then used to construct the unified explanations.
The authors demonstrate that their approach produces more stable and faithful explanations compared to existing local interpretation methods. This could improve trust and transparency in complex machine learning systems, particularly in high-stakes applications where it's important to understand how a model is making decisions.
While the paper makes a valuable contribution, there are still some potential limitations and areas for further research. Nonetheless, the unified explanations approach represents an important step forward in the field of interpretable machine learning, and its ideas and techniques could have significant implications for the development of more transparent and trustworthy AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Can you trust your explanations? A robustness test for feature attribution methods
Ilaria Vascotto, Alex Rodriguez, Alessandro Bonaita, Luca Bortolussi
0
0
The increase of legislative concerns towards the usage of Artificial Intelligence (AI) has recently led to a series of regulations striving for a more transparent, trustworthy and accountable AI. Along with these proposals, the field of Explainable AI (XAI) has seen a rapid growth but the usage of its techniques has at times led to unexpected results. The robustness of the approaches is, in fact, a key property often overlooked: it is necessary to evaluate the stability of an explanation (to random and adversarial perturbations) to ensure that the results are trustable. To this end, we propose a test to evaluate the robustness to non-adversarial perturbations and an ensemble approach to analyse more in depth the robustness of XAI methods applied to neural networks and tabular datasets. We will show how leveraging manifold hypothesis and ensemble approaches can be beneficial to an in-depth analysis of the robustness.
6/21/2024
📉
T-Explainer: A Model-Agnostic Explainability Framework Based on Gradients
Evandro S. Ortigossa, F'abio F. Dias, Brian Barr, Claudio T. Silva, Luis Gustavo Nonato
0
0
The development of machine learning applications has increased significantly in recent years, motivated by the remarkable ability of learning-powered systems to discover and generalize intricate patterns hidden in massive datasets. Modern learning models, while powerful, often exhibit a level of complexity that renders them opaque black boxes, resulting in a notable lack of transparency that hinders our ability to decipher their decision-making processes. Opacity challenges the interpretability and practical application of machine learning, especially in critical domains where understanding the underlying reasons is essential for informed decision-making. Explainable Artificial Intelligence (XAI) rises to meet that challenge, unraveling the complexity of black boxes by providing elucidating explanations. Among the various XAI approaches, feature attribution/importance XAI stands out for its capacity to delineate the significance of input features in the prediction process. However, most existing attribution methods have limitations, such as instability, when divergent explanations may result from similar or even the same instance. In this work, we introduce T-Explainer, a novel local additive attribution explainer based on Taylor expansion endowed with desirable properties, such as local accuracy and consistency, while stable over multiple runs. We demonstrate T-Explainer's effectiveness through benchmark experiments with well-known attribution methods. In addition, T-Explainer is developed as a comprehensive XAI framework comprising quantitative metrics to assess and visualize attribution explanations.
4/26/2024
🔄
A Perspective on Explainable Artificial Intelligence Methods: SHAP and LIME
Ahmed Salih, Zahra Raisi-Estabragh, Ilaria Boscolo Galazzo, Petia Radeva, Steffen E. Petersen, Gloria Menegaz, Karim Lekadir
0
0
eXplainable artificial intelligence (XAI) methods have emerged to convert the black box of machine learning (ML) models into a more digestible form. These methods help to communicate how the model works with the aim of making ML models more transparent and increasing the trust of end-users into their output. SHapley Additive exPlanations (SHAP) and Local Interpretable Model Agnostic Explanation (LIME) are two widely used XAI methods, particularly with tabular data. In this perspective piece, we discuss the way the explainability metrics of these two methods are generated and propose a framework for interpretation of their outputs, highlighting their weaknesses and strengths. Specifically, we discuss their outcomes in terms of model-dependency and in the presence of collinearity among the features, relying on a case study from the biomedical domain (classification of individuals with or without myocardial infarction). The results indicate that SHAP and LIME are highly affected by the adopted ML model and feature collinearity, raising a note of caution on their usage and interpretation.
6/18/2024
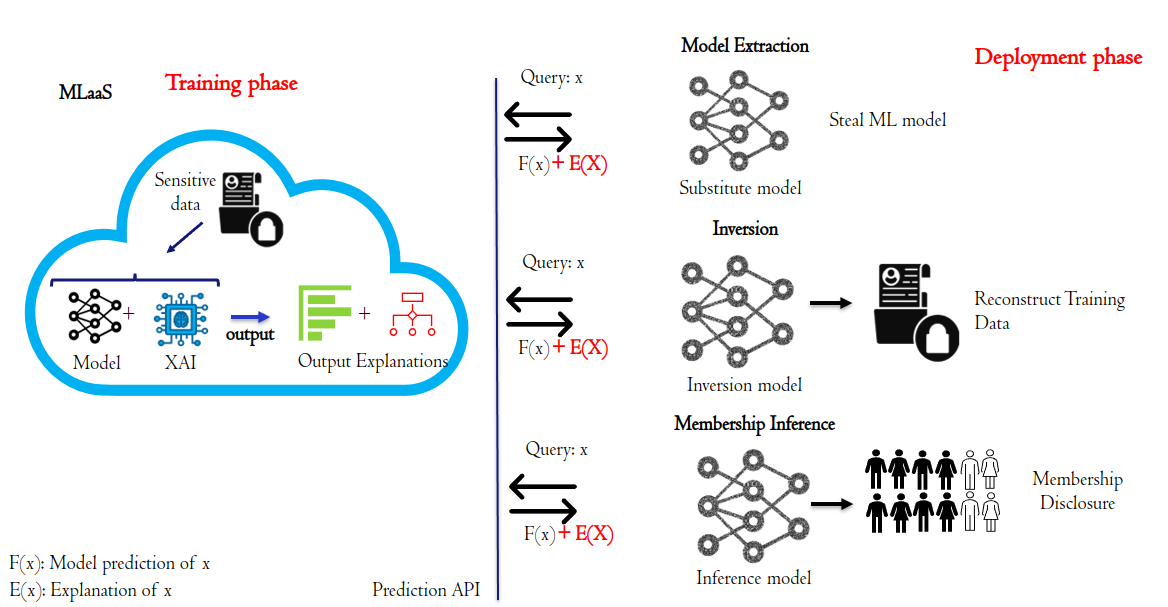
Privacy Implications of Explainable AI in Data-Driven Systems
Fatima Ezzeddine
0
0
Machine learning (ML) models, demonstrably powerful, suffer from a lack of interpretability. The absence of transparency, often referred to as the black box nature of ML models, undermines trust and urges the need for efforts to enhance their explainability. Explainable AI (XAI) techniques address this challenge by providing frameworks and methods to explain the internal decision-making processes of these complex models. Techniques like Counterfactual Explanations (CF) and Feature Importance play a crucial role in achieving this goal. Furthermore, high-quality and diverse data remains the foundational element for robust and trustworthy ML applications. In many applications, the data used to train ML and XAI explainers contain sensitive information. In this context, numerous privacy-preserving techniques can be employed to safeguard sensitive information in the data, such as differential privacy. Subsequently, a conflict between XAI and privacy solutions emerges due to their opposing goals. Since XAI techniques provide reasoning for the model behavior, they reveal information relative to ML models, such as their decision boundaries, the values of features, or the gradients of deep learning models when explanations are exposed to a third entity. Attackers can initiate privacy breaching attacks using these explanations, to perform model extraction, inference, and membership attacks. This dilemma underscores the challenge of finding the right equilibrium between understanding ML decision-making and safeguarding privacy.
6/26/2024