Model Merging and Safety Alignment: One Bad Model Spoils the Bunch
2406.14563
0
0

Abstract
Merging Large Language Models (LLMs) is a cost-effective technique for combining multiple expert LLMs into a single versatile model, retaining the expertise of the original ones. However, current approaches often overlook the importance of safety alignment during merging, leading to highly misaligned models. This work investigates the effects of model merging on alignment. We evaluate several popular model merging techniques, demonstrating that existing methods do not only transfer domain expertise but also propagate misalignment. We propose a simple two-step approach to address this problem: (i) generating synthetic safety and domain-specific data, and (ii) incorporating these generated data into the optimization process of existing data-aware model merging techniques. This allows us to treat alignment as a skill that can be maximized in the resulting merged LLM. Our experiments illustrate the effectiveness of integrating alignment-related data during merging, resulting in models that excel in both domain expertise and alignment.
Create account to get full access
Overview
- This paper explores the risks of merging multiple machine learning models, particularly in the context of safety-critical systems.
- The authors argue that even a single "bad" model can undermine the safety and reliability of a merged model, leading to unintended and potentially harmful behaviors.
- The paper examines the challenges of ensuring safety alignment across diverse models and proposes strategies for mitigating these risks.
Plain English Explanation
When you combine multiple machine learning models, there's a risk that a single "bad" model can spoil the whole bunch. Even if most of the models are well-behaved and safe, the inclusion of a single problematic model can compromise the safety and reliability of the merged system.
This is a particular concern in safety-critical applications, where the consequences of model failures can be severe. The authors of this paper explore the challenges of ensuring that the combined model remains safe and aligned with intended goals, even when individual components may have flaws or undesirable behaviors.
They propose strategies for mitigating these risks, such as careful vetting of individual models, robust testing procedures, and techniques for aligning the objectives and behaviors of the merged system. By addressing these challenges, the researchers aim to help ensure that model merging can be done safely and reliably, particularly in high-stakes domains.
Technical Explanation
The paper examines the risks associated with merging multiple machine learning models, particularly in the context of safety-critical applications. The authors argue that even a single "bad" model - one that exhibits undesirable or unsafe behaviors - can undermine the safety and reliability of the merged system.
The researchers explore the challenges of ensuring safety alignment across diverse models, which may have been trained on different data, optimized for different objectives, or developed by different teams. They propose strategies for mitigating these risks, including:
- Rigorous vetting and testing of individual models before merging
- Techniques for aligning the objectives and behaviors of the merged system
- Robust monitoring and control mechanisms to detect and respond to safety breaches
The paper also discusses the importance of comprehensive testing and validation procedures to ensure that the combined model behaves as intended, even in edge cases or unexpected situations.
Critical Analysis
The paper raises important concerns about the risks of model merging, particularly in safety-critical domains. The authors make a compelling case that even a single "bad" model can have a disproportionate impact on the safety and reliability of a merged system.
However, the paper could have delved deeper into the specific types of safety issues that can arise, as well as the potential sources of model misalignment. Additionally, the proposed mitigation strategies could be further elaborated, with more details on their implementation and effectiveness.
The paper also does not address the practical challenges of model vetting and alignment, such as the computational and technical resources required, or the challenges of aligning models with diverse architectures and training regimes.
Overall, the paper provides a valuable starting point for understanding the risks of model merging and the importance of safety alignment. However, more research is needed to develop robust and scalable solutions to these challenges, particularly as machine learning systems become increasingly complex and ubiquitous.
Conclusion
This paper highlights the significant risks associated with merging machine learning models, particularly in safety-critical applications. The authors make a strong case that even a single "bad" model can undermine the safety and reliability of a merged system, leading to unintended and potentially harmful behaviors.
By addressing the challenges of ensuring safety alignment across diverse models, the researchers aim to help developers and operators of safety-critical systems mitigate these risks. The proposed strategies, such as rigorous vetting and testing, objective alignment, and robust monitoring, offer promising approaches for enhancing the safety and reliability of model merging.
As machine learning systems become increasingly complex and widely deployed, the insights and recommendations provided in this paper will be crucial for ensuring that the benefits of these technologies are realized while the risks are effectively managed. Continued research and innovation in this area will be essential for building a future where AI systems can be trusted to operate safely and reliably, even in high-stakes environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
Aligners: Decoupling LLMs and Alignment
Lilian Ngweta, Mayank Agarwal, Subha Maity, Alex Gittens, Yuekai Sun, Mikhail Yurochkin
0
0
Large Language Models (LLMs) need to be aligned with human expectations to ensure their safety and utility in most applications. Alignment is challenging, costly, and needs to be repeated for every LLM and alignment criterion. We propose to decouple LLMs and alignment by training aligner models that can be used to align any LLM for a given criteria on an as-needed basis, thus also reducing the potential negative impacts of alignment on performance. Our recipe for training the aligner models solely relies on synthetic data generated with a (prompted) LLM and can be easily adjusted for a variety of alignment criteria. We use the same synthetic data to train inspectors, binary miss-alignment classification models to guide a squad of multiple aligners. Our empirical results demonstrate consistent improvements when applying aligner squad to various LLMs, including chat-aligned models, across several instruction-following and red-teaming datasets.
6/18/2024

SLM as Guardian: Pioneering AI Safety with Small Language Models
Ohjoon Kwon, Donghyeon Jeon, Nayoung Choi, Gyu-Hwung Cho, Changbong Kim, Hyunwoo Lee, Inho Kang, Sun Kim, Taiwoo Park
0
0
Most prior safety research of large language models (LLMs) has focused on enhancing the alignment of LLMs to better suit the safety requirements of humans. However, internalizing such safeguard features into larger models brought challenges of higher training cost and unintended degradation of helpfulness. To overcome such challenges, a modular approach employing a smaller LLM to detect harmful user queries is regarded as a convenient solution in designing LLM-based system with safety requirements. In this paper, we leverage a smaller LLM for both harmful query detection and safeguard response generation. We introduce our safety requirements and the taxonomy of harmfulness categories, and then propose a multi-task learning mechanism fusing the two tasks into a single model. We demonstrate the effectiveness of our approach, providing on par or surpassing harmful query detection and safeguard response performance compared to the publicly available LLMs.
5/31/2024

Robustifying Safety-Aligned Large Language Models through Clean Data Curation
Xiaoqun Liu, Jiacheng Liang, Muchao Ye, Zhaohan Xi
0
0
Large language models (LLMs) are vulnerable when trained on datasets containing harmful content, which leads to potential jailbreaking attacks in two scenarios: the integration of harmful texts within crowdsourced data used for pre-training and direct tampering with LLMs through fine-tuning. In both scenarios, adversaries can compromise the safety alignment of LLMs, exacerbating malfunctions. Motivated by the need to mitigate these adversarial influences, our research aims to enhance safety alignment by either neutralizing the impact of malicious texts in pre-training datasets or increasing the difficulty of jailbreaking during downstream fine-tuning. In this paper, we propose a data curation framework designed to counter adversarial impacts in both scenarios. Our method operates under the assumption that we have no prior knowledge of attack details, focusing solely on curating clean texts. We introduce an iterative process aimed at revising texts to reduce their perplexity as perceived by LLMs, while simultaneously preserving their text quality. By pre-training or fine-tuning LLMs with curated clean texts, we observe a notable improvement in LLM robustness regarding safety alignment against harmful queries. For instance, when pre-training LLMs using a crowdsourced dataset containing 5% harmful instances, adding an equivalent amount of curated texts significantly mitigates the likelihood of providing harmful responses in LLMs and reduces the attack success rate by 71%. Our study represents a significant step towards mitigating the risks associated with training-based jailbreaking and fortifying the secure utilization of LLMs.
6/3/2024
Emulated Disalignment: Safety Alignment for Large Language Models May Backfire!
Zhanhui Zhou, Jie Liu, Zhichen Dong, Jiaheng Liu, Chao Yang, Wanli Ouyang, Yu Qiao
0
0
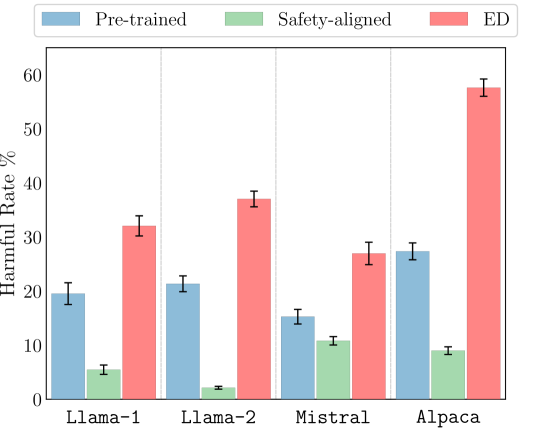
Large language models (LLMs) undergo safety alignment to ensure safe conversations with humans. However, this paper introduces a training-free attack method capable of reversing safety alignment, converting the outcomes of stronger alignment into greater potential for harm by accessing only LLM output token distributions. Specifically, our method achieves this reversal by contrasting the output token distribution of a safety-aligned language model (e.g., Llama-2-chat) against its pre-trained version (e.g., Llama-2), so that the token predictions are shifted towards the opposite direction of safety alignment. We name this method emulated disalignment (ED) because sampling from this contrastive distribution provably emulates the result of fine-tuning to minimize a safety reward. Our experiments with ED across three evaluation datasets and four model families (Llama-1, Llama-2, Mistral, and Alpaca) show that ED doubles the harmfulness of pre-trained models and outperforms strong baselines, achieving the highest harmful rates in 43 out of 48 evaluation subsets by a large margin. Eventually, given ED's reliance on language model output token distributions, which particularly compromises open-source models, our findings highlight the need to reassess the open accessibility of language models, even if they have been safety-aligned. Code is available at https://github.com/ZHZisZZ/emulated-disalignment.
6/7/2024