Model Reconstruction Using Counterfactual Explanations: Mitigating the Decision Boundary Shift
2405.05369
0
0
Abstract
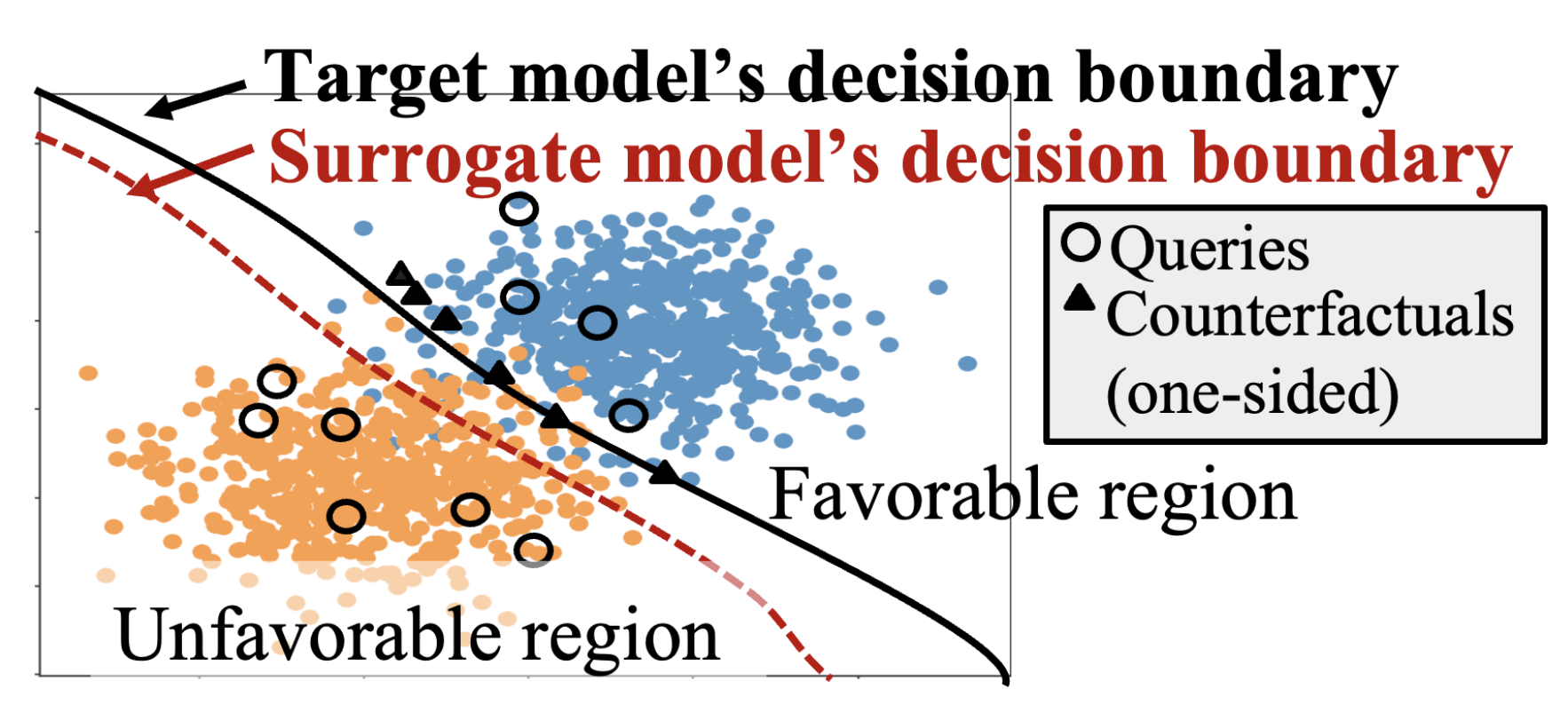
Counterfactual explanations find ways of achieving a favorable model outcome with minimum input perturbation. However, counterfactual explanations can also be exploited to steal the model by strategically training a surrogate model to give similar predictions as the original (target) model. In this work, we investigate model extraction by specifically leveraging the fact that the counterfactual explanations also lie quite close to the decision boundary. We propose a novel strategy for model extraction that we call Counterfactual Clamping Attack (CCA) which trains a surrogate model using a unique loss function that treats counterfactuals differently than ordinary instances. Our approach also alleviates the related problem of decision boundary shift that arises in existing model extraction attacks which treat counterfactuals as ordinary instances. We also derive novel mathematical relationships between the error in model approximation and the number of queries using polytope theory. Experimental results demonstrate that our strategy provides improved fidelity between the target and surrogate model predictions on several real world datasets.
Create account to get full access
Model Reconstruction Using Counterfactual Explanations: Mitigating the Decision Boundary Shift
Overview
- The paper explores how to mitigate the decision boundary shift when using counterfactual explanations to reconstruct machine learning models.
- Counterfactual explanations are a popular method for explaining the decisions of black-box models, but can lead to inaccurate model reconstruction.
- The authors propose a new approach called CREX that incorporates cardinality constraints to address this issue and improve the fidelity of reconstructed models.
Plain English Explanation
Imagine you have a complex machine learning model that makes important decisions, like whether to approve a loan application. You want to understand how the model works so you can verify it's making fair and accurate decisions. One way to do this is using counterfactual explanations. These explanations show what changes you could make to the input data to get a different decision from the model.
However, the paper explains that using counterfactual explanations to reconstruct the original model can be problematic. The reconstructed model may not accurately match the original, a phenomenon called the "decision boundary shift." This means the reconstructed model may behave differently than the original in important ways.
To address this, the authors propose a new technique called CREX that incorporates additional constraints, based on the cardinality or number of changes required to get a different prediction. This helps ensure the reconstructed model more closely matches the original, even in complex, high-dimensional settings.
Technical Explanation
The paper presents a new technique called CREX (Counterfactual Reconstruction with cardinality Constraints) to mitigate the decision boundary shift when reconstructing machine learning models using counterfactual explanations.
Counterfactual explanations are a popular method for explaining the decisions of black-box models. They identify the minimal changes that could be made to an input to change the model's prediction. However, the authors show that using counterfactual explanations to reconstruct the original model can lead to inaccuracies, as the reconstructed model's decision boundary may not align with the true underlying model.
To address this, CREX incorporates cardinality constraints into the reconstruction process. This ensures the counterfactual explanations generated during reconstruction satisfy constraints on the number of feature changes required. The authors demonstrate that CREX can significantly improve the fidelity of the reconstructed model, even in high-dimensional settings.
The paper also includes an extensive experimental evaluation, comparing CREX to existing model extraction techniques on both synthetic and real-world datasets. The results show CREX outperforms alternative approaches in terms of reconstruction accuracy, particularly when the original model has a complex decision boundary.
Critical Analysis
The paper makes a valuable contribution by addressing an important limitation of using counterfactual explanations for model reconstruction. The authors clearly identify the decision boundary shift problem and propose a well-designed solution in CREX.
One potential area for further research is exploring the impact of the choice of cardinality constraint on the reconstructed model's fidelity. The paper shows that CREX is effective, but it would be helpful to understand how different cardinality thresholds or constraints affect the tradeoffs between reconstruction accuracy and other factors, such as computation time.
Additionally, the paper focuses on model reconstruction in a supervised learning setting. It would be interesting to see if the CREX approach could be extended to other machine learning tasks, such as unsupervised learning or time-series forecasting, where counterfactual explanations could also be valuable for understanding model behavior.
Overall, the paper presents a well-designed and thorough solution to an important problem in the field of interpretable machine learning. The CREX approach offers a promising way to improve the fidelity of model reconstructions using counterfactual explanations.
Conclusion
This paper addresses a key challenge in using counterfactual explanations to reconstruct machine learning models: the decision boundary shift. The authors propose a new technique called CREX that incorporates cardinality constraints to mitigate this issue and improve the fidelity of the reconstructed models.
The CREX approach represents an important advancement in the field of interpretable machine learning, as it enables more accurate and trustworthy model explanations. This has significant implications for critical applications where model transparency and accountability are essential, such as financial lending, healthcare, and criminal justice.
By continuing to develop techniques like CREX, researchers can help unlock the full potential of machine learning while ensuring these powerful models remain interpretable and aligned with human values. This is a crucial step towards building AI systems that are both highly capable and deeply trustworthy.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
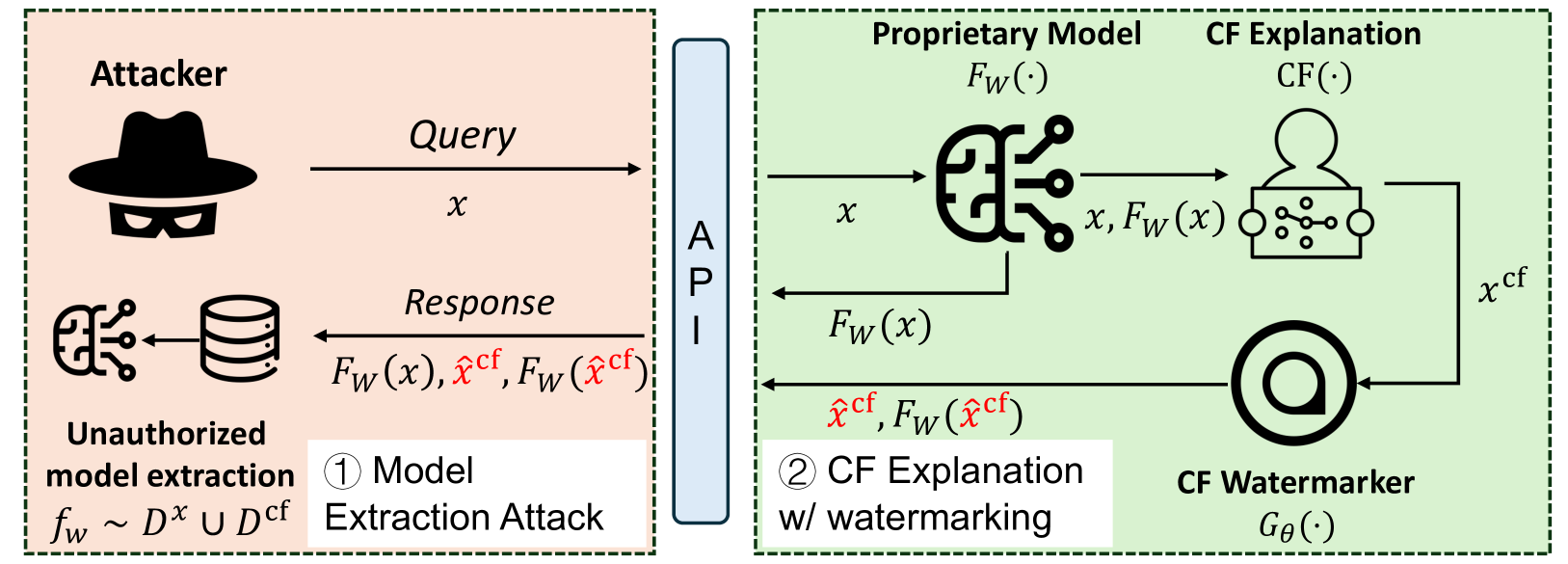
Watermarking Counterfactual Explanations
Hangzhi Guo, Amulya Yadav
0
0
The field of Explainable Artificial Intelligence (XAI) focuses on techniques for providing explanations to end-users about the decision-making processes that underlie modern-day machine learning (ML) models. Within the vast universe of XAI techniques, counterfactual (CF) explanations are often preferred by end-users as they help explain the predictions of ML models by providing an easy-to-understand & actionable recourse (or contrastive) case to individual end-users who are adversely impacted by predicted outcomes. However, recent studies have shown significant security concerns with using CF explanations in real-world applications; in particular, malicious adversaries can exploit CF explanations to perform query-efficient model extraction attacks on proprietary ML models. In this paper, we propose a model-agnostic watermarking framework (for adding watermarks to CF explanations) that can be leveraged to detect unauthorized model extraction attacks (which rely on the watermarked CF explanations). Our novel framework solves a bi-level optimization problem to embed an indistinguishable watermark into the generated CF explanation such that any future model extraction attacks that rely on these watermarked CF explanations can be detected using a null hypothesis significance testing (NHST) scheme, while ensuring that these embedded watermarks do not compromise the quality of the generated CF explanations. We evaluate this framework's performance across a diverse set of real-world datasets, CF explanation methods, and model extraction techniques, and show that our watermarking detection system can be used to accurately identify extracted ML models that are trained using the watermarked CF explanations. Our work paves the way for the secure adoption of CF explanations in real-world applications.
5/30/2024

Knowledge Distillation-Based Model Extraction Attack using Private Counterfactual Explanations
Fatima Ezzeddine, Omran Ayoub, Silvia Giordano
0
0
In recent years, there has been a notable increase in the deployment of machine learning (ML) models as services (MLaaS) across diverse production software applications. In parallel, explainable AI (XAI) continues to evolve, addressing the necessity for transparency and trustworthiness in ML models. XAI techniques aim to enhance the transparency of ML models by providing insights, in terms of the model's explanations, into their decision-making process. Simultaneously, some MLaaS platforms now offer explanations alongside the ML prediction outputs. This setup has elevated concerns regarding vulnerabilities in MLaaS, particularly in relation to privacy leakage attacks such as model extraction attacks (MEA). This is due to the fact that explanations can unveil insights about the inner workings of the model which could be exploited by malicious users. In this work, we focus on investigating how model explanations, particularly Generative adversarial networks (GANs)-based counterfactual explanations (CFs), can be exploited for performing MEA within the MLaaS platform. We also delve into assessing the effectiveness of incorporating differential privacy (DP) as a mitigation strategy. To this end, we first propose a novel MEA methodology based on Knowledge Distillation (KD) to enhance the efficiency of extracting a substitute model of a target model exploiting CFs. Then, we advise an approach for training CF generators incorporating DP to generate private CFs. We conduct thorough experimental evaluations on real-world datasets and demonstrate that our proposed KD-based MEA can yield a high-fidelity substitute model with reduced queries with respect to baseline approaches. Furthermore, our findings reveal that the inclusion of a privacy layer impacts the performance of the explainer, the quality of CFs, and results in a reduction in the MEA performance.
4/5/2024
📊
Generating Counterfactual Explanations Using Cardinality Constraints
Rub'en Ruiz-Torrubiano
0
0
Providing explanations about how machine learning algorithms work and/or make particular predictions is one of the main tools that can be used to improve their trusworthiness, fairness and robustness. Among the most intuitive type of explanations are counterfactuals, which are examples that differ from a given point only in the prediction target and some set of features, presenting which features need to be changed in the original example to flip the prediction for that example. However, such counterfactuals can have many different features than the original example, making their interpretation difficult. In this paper, we propose to explicitly add a cardinality constraint to counterfactual generation limiting how many features can be different from the original example, thus providing more interpretable and easily understantable counterfactuals.
4/12/2024
🔮
Explaining Text Classifiers with Counterfactual Representations
Pirmin Lemberger, Antoine Saillenfest
0
0
One well motivated explanation method for classifiers leverages counterfactuals which are hypothetical events identical to real observations in all aspects except for one categorical feature. Constructing such counterfactual poses specific challenges for texts, however, as some attribute values may not necessarily align with plausible real-world events. In this paper we propose a simple method for generating counterfactuals by intervening in the space of text representations which bypasses this limitation. We argue that our interventions are minimally disruptive and that they are theoretically sound as they align with counterfactuals as defined in Pearl's causal inference framework. To validate our method, we conducted experiments first on a synthetic dataset and then on a realistic dataset of counterfactuals. This allows for a direct comparison between classifier predictions based on ground truth counterfactuals - obtained through explicit text interventions - and our counterfactuals, derived through interventions in the representation space. Eventually, we study a real world scenario where our counterfactuals can be leveraged both for explaining a classifier and for bias mitigation.
4/30/2024