MODL: Multilearner Online Deep Learning

0

Sign in to get full access
Overview
- This paper introduces MODL, a novel approach to online deep learning that leverages multiple learners to improve performance and robustness.
- MODL aims to address the challenges of online deep learning, where models must continuously learn from a stream of data without access to the full dataset.
- The key idea behind MODL is to maintain and update multiple neural network models in parallel, each with its own set of parameters, and then combine their predictions to make the final output.
Plain English Explanation
MODL is a new way of doing online deep learning, which means training machine learning models on data as it comes in, rather than all at once. The main problem with online deep learning is that the models can become less accurate over time as they see new data. MODL tries to solve this by having multiple neural network models running at the same time, each with its own set of parameters. As new data comes in, all the models get updated, but in slightly different ways. Then, when making a final prediction, MODL combines the outputs of all the models together, which helps make the predictions more robust and accurate, even as the data changes over time.
The key insight behind MODL is that by having multiple "learners" or models working in parallel, each with its own unique way of updating, the overall system can better adapt to new data and maintain high performance, even in challenging online learning scenarios. This multilearner approach helps address some of the challenges that arise in online deep learning, where models need to continuously learn from a stream of data without access to the full dataset at once.
Technical Explanation
The MODL approach involves maintaining and updating K neural network models in parallel, each with its own set of parameters. At each time step, a mini-batch of data is presented to the system, and all K models are updated using a gradient-based optimization algorithm. However, the updates to each model are perturbed in a unique way, either through the use of different learning rates, momentum values, or other hyperparameters.
The final output of the MODL system is then computed as a weighted average of the outputs from the K models. The weights are determined adaptively based on the recent performance of each model, allowing the system to focus more on the better-performing models over time.
The authors demonstrate the effectiveness of MODL on several online learning benchmarks, showing that it can outperform both single-model online learning approaches as well as existing ensemble methods. They also provide theoretical analysis to characterize the convergence and regret bounds of the MODL algorithm.
Critical Analysis
The MODL paper makes a compelling case for the benefits of using a multilearner approach to online deep learning. By maintaining and updating multiple models in parallel, the system can better adapt to changes in the data distribution and maintain high performance over time.
However, the paper does not address some potential limitations of the MODL approach. For example, the computational and memory overhead of maintaining multiple models may be a concern, especially for large-scale problems. Additionally, the authors do not explore the sensitivity of MODL's performance to the number of models used or the specific hyperparameter perturbation strategies employed.
Furthermore, the paper's theoretical analysis focuses on regret bounds and convergence, but does not provide insights into the generalization capabilities of the MODL approach or its robustness to distribution shifts or adversarial attacks. These are important considerations for real-world deployment of online deep learning systems.
Despite these caveats, the MODL paper represents an important contribution to the field of online deep learning, and the multilearner approach it introduces could be a promising direction for further research and development in this area.
Conclusion
The MODL paper proposes a novel approach to online deep learning that leverages multiple learners to improve performance and robustness. By maintaining and updating multiple neural network models in parallel, each with its own unique perturbations, MODL can better adapt to changes in the data distribution and maintain high accuracy over time.
The key insight behind MODL is that a multilearner strategy can effectively address some of the challenges inherent in online deep learning, where models must continuously learn from a stream of data without access to the full dataset. This gradient-based approach represents an important step forward in the field and could have significant implications for a wide range of real-world applications that require robust, adaptive machine learning models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MODL: Multilearner Online Deep Learning
Antonios Valkanas, Boris N. Oreshkin, Mark Coates
Online deep learning solves the problem of learning from streams of data, reconciling two opposing objectives: learn fast and learn deep. Existing work focuses almost exclusively on exploring pure deep learning solutions, which are much better suited to handle the deep than the fast part of the online learning equation. In our work, we propose a different paradigm, based on a hybrid multilearner approach. First, we develop a fast online logistic regression learner. This learner does not rely on backpropagation. Instead, it uses closed form recursive updates of model parameters, handling the fast learning part of the online learning problem. We then analyze the existing online deep learning theory and show that the widespread ODL approach, currently operating at complexity $O(L^2)$ in terms of the number of layers $L$, can be equivalently implemented in $O(L)$ complexity. This further leads us to the cascaded multilearner design, in which multiple shallow and deep learners are co-trained to solve the online learning problem in a cooperative, synergistic fashion. We show that this approach achieves state-of-the-art results on common online learning datasets, while also being able to handle missing features gracefully. Our code is publicly available at https://github.com/AntonValk/MODL.
Read more5/29/2024

0
Online Cascade Learning for Efficient Inference over Streams
Lunyiu Nie, Zhimin Ding, Erdong Hu, Christopher Jermaine, Swarat Chaudhuri
Large Language Models (LLMs) have a natural role in answering complex queries about data streams, but the high computational cost of LLM inference makes them infeasible in many such tasks. We propose online cascade learning, the first approach to address this challenge. The objective here is to learn a cascade of models, starting with lower-capacity models (such as logistic regression) and ending with a powerful LLM, along with a deferral policy that determines the model to be used on a given input. We formulate the task of learning cascades online as an imitation-learning problem, where smaller models are updated over time imitating the collected LLM demonstrations, and give a no-regret algorithm for the problem. Experimental results across four benchmarks show that our method parallels LLMs in accuracy while cutting down inference costs by as much as 90% with strong robustness against input distribution shifts, underscoring its efficacy and adaptability in stream processing.
Read more6/19/2024

0
A Retrospective of the Tutorial on Opportunities and Challenges of Online Deep Learning
Cedric Kulbach, Lucas Cazzonelli, Hoang-Anh Ngo, Minh-Huong Le-Nguyen, Albert Bifet
Machine learning algorithms have become indispensable in today's world. They support and accelerate the way we make decisions based on the data at hand. This acceleration means that data structures that were valid at one moment could no longer be valid in the future. With these changing data structures, it is necessary to adapt machine learning (ML) systems incrementally to the new data. This is done with the use of online learning or continuous ML technologies. While deep learning technologies have shown exceptional performance on predefined datasets, they have not been widely applied to online, streaming, and continuous learning. In this retrospective of our tutorial titled Opportunities and Challenges of Online Deep Learning held at ECML PKDD 2023, we provide a brief overview of the opportunities but also the potential pitfalls for the application of neural networks in online learning environments using the frameworks River and Deep-River.
Read more5/29/2024
0
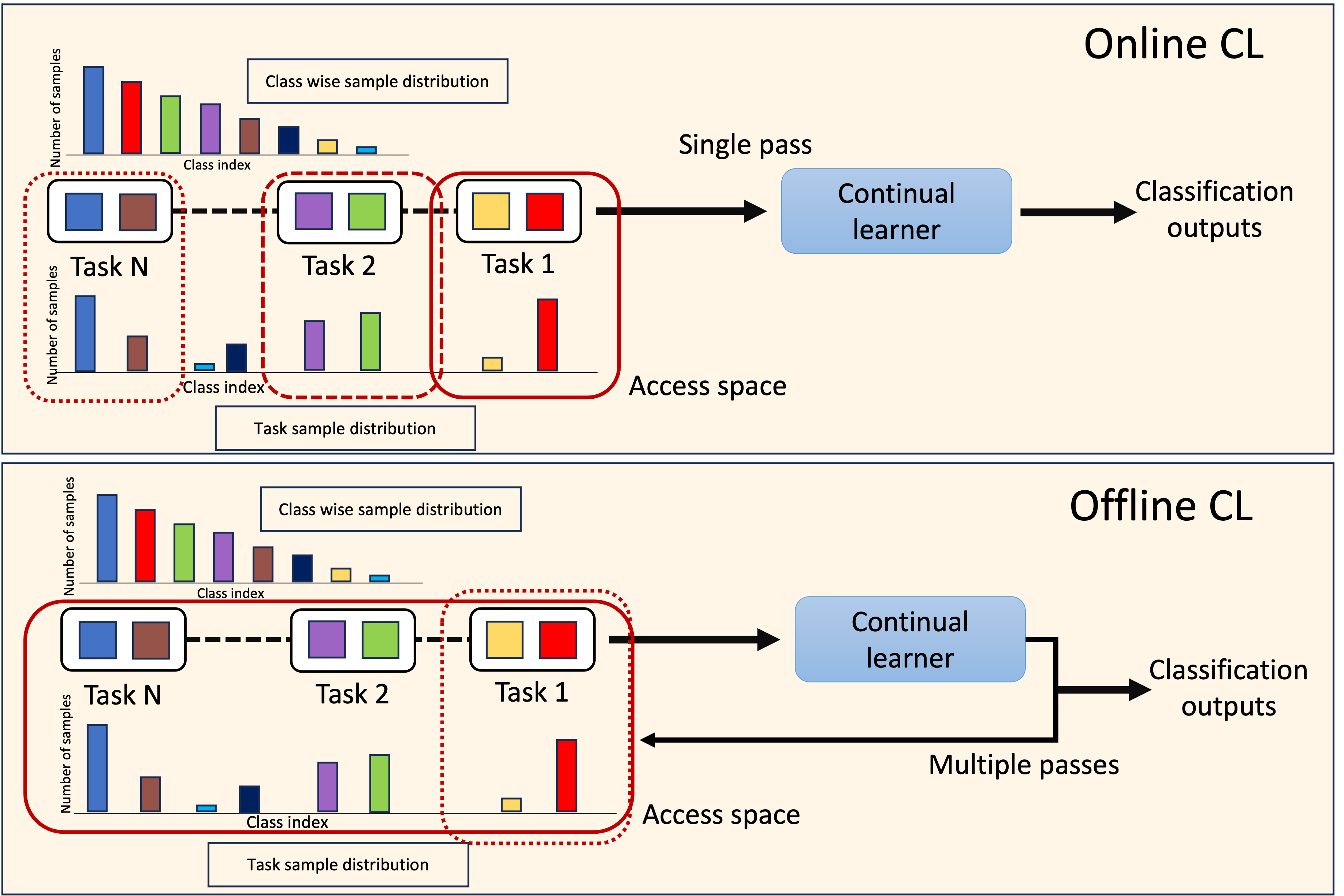
DELTA: Decoupling Long-Tailed Online Continual Learning
Siddeshwar Raghavan, Jiangpeng He, Fengqing Zhu
A significant challenge in achieving ubiquitous Artificial Intelligence is the limited ability of models to rapidly learn new information in real-world scenarios where data follows long-tailed distributions, all while avoiding forgetting previously acquired knowledge. In this work, we study the under-explored problem of Long-Tailed Online Continual Learning (LTOCL), which aims to learn new tasks from sequentially arriving class-imbalanced data streams. Each data is observed only once for training without knowing the task data distribution. We present DELTA, a decoupled learning approach designed to enhance learning representations and address the substantial imbalance in LTOCL. We enhance the learning process by adapting supervised contrastive learning to attract similar samples and repel dissimilar (out-of-class) samples. Further, by balancing gradients during training using an equalization loss, DELTA significantly enhances learning outcomes and successfully mitigates catastrophic forgetting. Through extensive evaluation, we demonstrate that DELTA improves the capacity for incremental learning, surpassing existing OCL methods. Our results suggest considerable promise for applying OCL in real-world applications.
Read more4/9/2024