DELTA: Decoupling Long-Tailed Online Continual Learning
2404.04476
0
0
Abstract
A significant challenge in achieving ubiquitous Artificial Intelligence is the limited ability of models to rapidly learn new information in real-world scenarios where data follows long-tailed distributions, all while avoiding forgetting previously acquired knowledge. In this work, we study the under-explored problem of Long-Tailed Online Continual Learning (LTOCL), which aims to learn new tasks from sequentially arriving class-imbalanced data streams. Each data is observed only once for training without knowing the task data distribution. We present DELTA, a decoupled learning approach designed to enhance learning representations and address the substantial imbalance in LTOCL. We enhance the learning process by adapting supervised contrastive learning to attract similar samples and repel dissimilar (out-of-class) samples. Further, by balancing gradients during training using an equalization loss, DELTA significantly enhances learning outcomes and successfully mitigates catastrophic forgetting. Through extensive evaluation, we demonstrate that DELTA improves the capacity for incremental learning, surpassing existing OCL methods. Our results suggest considerable promise for applying OCL in real-world applications.
Create account to get full access
Overview
- Presents a new approach called DELTA (Decoupled Long-Tailed Adaptation) for tackling the challenge of online continual learning on long-tailed data distributions
- Addresses the problem of models forgetting previous knowledge as they learn new tasks in a sequential manner
- Proposes a decoupled architecture that separates feature learning from classification to improve performance on long-tailed datasets
Plain English Explanation
The paper introduces a new technique called DELTA that aims to help AI models learn continuously over time without forgetting what they've learned before. This is a common problem in continual learning, where models are trained on a sequence of tasks and tend to forget earlier knowledge as they learn new things.
The key insight of DELTA is to decouple the feature learning and classification components of the model. This allows the feature extractor to focus on learning general, transferable representations, while the classifier adapts to handle the shifting data distribution, including long-tailed class imbalances.
By separating these concerns, DELTA is better able to retain knowledge from past tasks while still adapting to new data. This contrasts with typical continual learning approaches, where the model's parameters are updated holistically, leading to catastrophic forgetting.
The authors demonstrate DELTA's effectiveness on several standard continual learning benchmarks, showing significant improvements over existing methods, especially on datasets with long-tailed class distributions. This suggests DELTA could be a useful tool for building continual learning systems that can adapt to new information over time without losing crucial prior knowledge.
Technical Explanation
The core idea behind DELTA is to decouple the feature learning and classification components of the model. The feature extractor is trained to learn general, transferable representations, while the classifier is responsible for adapting to the changing data distribution, including any long-tailed class imbalances.
This decoupled architecture contrasts with typical continual learning approaches, where the model's parameters are updated holistically. In these cases, learning new tasks can lead to catastrophic forgetting of previous knowledge.
In DELTA, the feature extractor is trained using knowledge distillation, where the model is encouraged to maintain its previous representations. The classifier, on the other hand, is updated using a combination of gradient descent and class-balanced sampling to address the long-tailed distribution.
The authors evaluate DELTA on several standard continual learning benchmarks, including Split CIFAR-100 and Split miniImageNet. They show that DELTA significantly outperforms existing continual learning methods, especially on datasets with long-tailed class distributions. This demonstrates the effectiveness of the decoupled architecture in retaining knowledge from past tasks while adapting to new information.
Critical Analysis
The DELTA approach represents an interesting and promising direction for addressing the challenges of online continual learning, particularly on datasets with long-tailed class distributions. By decoupling feature learning and classification, the model is able to maintain general, transferable representations while adapting the classifier to handle the shifting data.
One potential limitation of the DELTA approach is that it may require more computational resources than some other continual learning methods, as it involves training and maintaining separate components. The authors acknowledge this in the paper and suggest that future work could explore ways to further optimize the architecture.
Additionally, the evaluation in the paper is primarily focused on image classification tasks. It would be valuable to see how DELTA performs on a wider range of continual learning problems, such as reinforcement learning or long-tailed anomaly detection, to assess its broader applicability.
Overall, the DELTA approach represents an exciting step forward in the field of continual learning, particularly for real-world scenarios with non-uniform data distributions. As the authors note, further research is needed to fully understand the strengths and limitations of this decoupled architecture, but the promising results suggest it could be a valuable tool for building more adaptable and robust AI systems.
Conclusion
The DELTA (Decoupled Long-Tailed Adaptation) approach presented in this paper offers a novel solution to the challenge of online continual learning on long-tailed data distributions. By decoupling the feature learning and classification components of the model, DELTA is able to maintain general, transferable representations while adapting the classifier to handle the shifting data.
The authors demonstrate the effectiveness of this approach on several standard continual learning benchmarks, showing significant improvements over existing methods, especially on datasets with long-tailed class distributions. This suggests DELTA could be a valuable tool for building continual learning systems that can adapt to new information over time without catastrophically forgetting previous knowledge.
While the DELTA approach shows promise, further research is needed to explore its performance on a wider range of continual learning tasks and to optimize the computational efficiency of the decoupled architecture. Nevertheless, this work represents an important step forward in addressing the critical challenge of enabling AI systems to learn continuously in real-world, non-uniform environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
✨
Continual Learning of Numerous Tasks from Long-tail Distributions
Liwei Kang, Wee Sun Lee
0
0
Continual learning, an important aspect of artificial intelligence and machine learning research, focuses on developing models that learn and adapt to new tasks while retaining previously acquired knowledge. Existing continual learning algorithms usually involve a small number of tasks with uniform sizes and may not accurately represent real-world learning scenarios. In this paper, we investigate the performance of continual learning algorithms with a large number of tasks drawn from a task distribution that is long-tail in terms of task sizes. We design one synthetic dataset and two real-world continual learning datasets to evaluate the performance of existing algorithms in such a setting. Moreover, we study an overlooked factor in continual learning, the optimizer states, e.g. first and second moments in the Adam optimizer, and investigate how it can be used to improve continual learning performance. We propose a method that reuses the optimizer states in Adam by maintaining a weighted average of the second moments from previous tasks. We demonstrate that our method, compatible with most existing continual learning algorithms, effectively reduces forgetting with only a small amount of additional computational or memory costs, and provides further improvements on existing continual learning algorithms, particularly in a long-tail task sequence.
4/4/2024
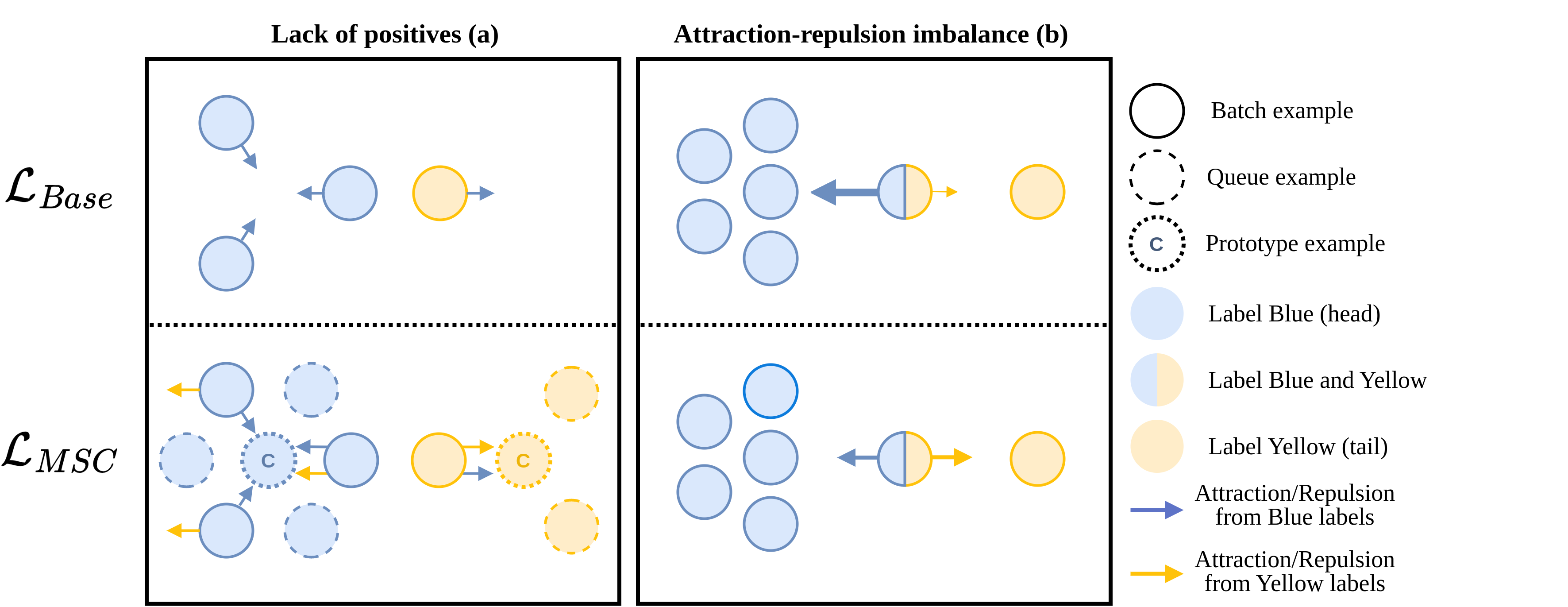
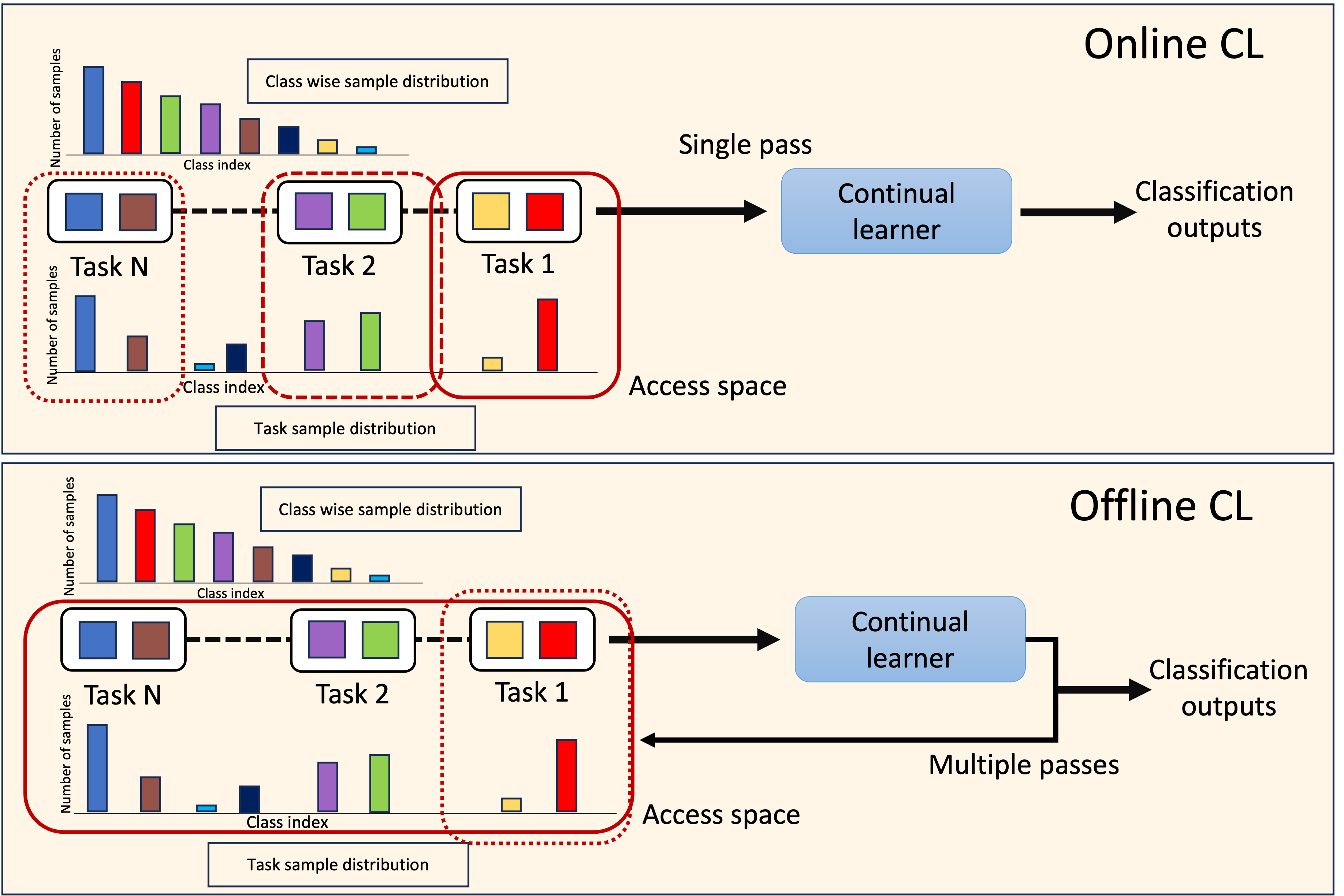
Exploring Contrastive Learning for Long-Tailed Multi-Label Text Classification
Alexandre Audibert, Aur'elien Gauffre, Massih-Reza Amini
0
0
Learning an effective representation in multi-label text classification (MLTC) is a significant challenge in NLP. This challenge arises from the inherent complexity of the task, which is shaped by two key factors: the intricate connections between labels and the widespread long-tailed distribution of the data. To overcome this issue, one potential approach involves integrating supervised contrastive learning with classical supervised loss functions. Although contrastive learning has shown remarkable performance in multi-class classification, its impact in the multi-label framework has not been thoroughly investigated. In this paper, we conduct an in-depth study of supervised contrastive learning and its influence on representation in MLTC context. We emphasize the importance of considering long-tailed data distributions to build a robust representation space, which effectively addresses two critical challenges associated with contrastive learning that we identify: the lack of positives and the attraction-repulsion imbalance. Building on this insight, we introduce a novel contrastive loss function for MLTC. It attains Micro-F1 scores that either match or surpass those obtained with other frequently employed loss functions, and demonstrates a significant improvement in Macro-F1 scores across three multi-label datasets.
4/16/2024

Overcoming Domain Drift in Online Continual Learning
Fan Lyu, Daofeng Liu, Linglan Zhao, Zhang Zhang, Fanhua Shang, Fuyuan Hu, Wei Feng, Liang Wang
0
0
Online Continual Learning (OCL) empowers machine learning models to acquire new knowledge online across a sequence of tasks. However, OCL faces a significant challenge: catastrophic forgetting, wherein the model learned in previous tasks is substantially overwritten upon encountering new tasks, leading to a biased forgetting of prior knowledge. Moreover, the continual doman drift in sequential learning tasks may entail the gradual displacement of the decision boundaries in the learned feature space, rendering the learned knowledge susceptible to forgetting. To address the above problem, in this paper, we propose a novel rehearsal strategy, termed Drift-Reducing Rehearsal (DRR), to anchor the domain of old tasks and reduce the negative transfer effects. First, we propose to select memory for more representative samples guided by constructed centroids in a data stream. Then, to keep the model from domain chaos in drifting, a two-level angular cross-task Contrastive Margin Loss (CML) is proposed, to encourage the intra-class and intra-task compactness, and increase the inter-class and inter-task discrepancy. Finally, to further suppress the continual domain drift, we present an optional Centorid Distillation Loss (CDL) on the rehearsal memory to anchor the knowledge in feature space for each previous old task. Extensive experimental results on four benchmark datasets validate that the proposed DRR can effectively mitigate the continual domain drift and achieve the state-of-the-art (SOTA) performance in OCL.
5/16/2024
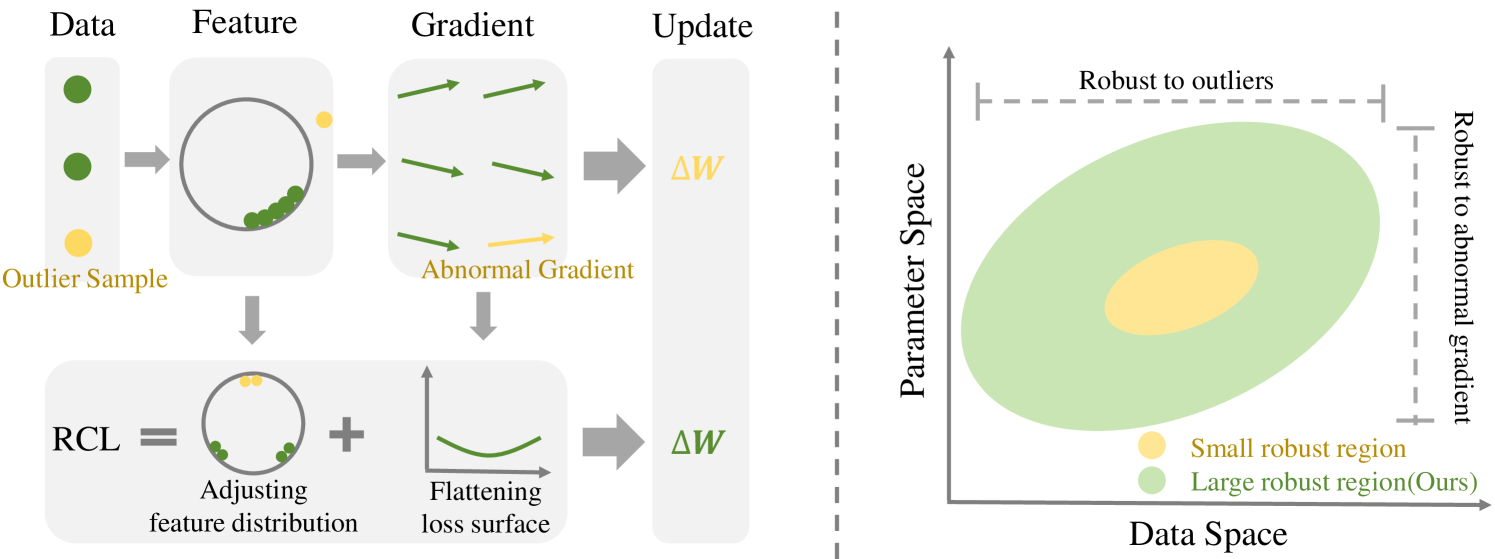
Improving Data-aware and Parameter-aware Robustness for Continual Learning
Hanxi Xiao, Fan Lyu
0
0
The goal of Continual Learning (CL) task is to continuously learn multiple new tasks sequentially while achieving a balance between the plasticity and stability of new and old knowledge. This paper analyzes that this insufficiency arises from the ineffective handling of outliers, leading to abnormal gradients and unexpected model updates. To address this issue, we enhance the data-aware and parameter-aware robustness of CL, proposing a Robust Continual Learning (RCL) method. From the data perspective, we develop a contrastive loss based on the concepts of uniformity and alignment, forming a feature distribution that is more applicable to outliers. From the parameter perspective, we present a forward strategy for worst-case perturbation and apply robust gradient projection to the parameters. The experimental results on three benchmarks show that the proposed method effectively maintains robustness and achieves new state-of-the-art (SOTA) results. The code is available at: https://github.com/HanxiXiao/RCL
5/28/2024