Multimodal Cross-Task Interaction for Survival Analysis in Whole Slide Pathological Images

0

Sign in to get full access
Overview
- This paper proposes a multimodal deep learning framework for survival analysis on whole slide pathological images.
- The framework combines text, image, and genomic data to jointly learn representations and make survival predictions.
- The authors introduce a novel Transport-Guided Attention (TGA) module to enable cross-modal interaction and information sharing.
- They evaluate their approach on multiple cancer datasets and demonstrate improved performance over unimodal and other baseline methods.
Plain English Explanation
The paper presents a new way to analyze medical images, like those taken during cancer biopsies, to predict how long a patient might survive. Typically, doctors would look at these images and try to make a prediction, but this can be quite difficult and subjective.
The researchers developed a machine learning model that can combine information from the medical images, along with text data about the patient's condition and genomic data about the tumor's genetic makeup. By bringing all of these different types of data together, the model can learn more comprehensive representations of the disease and make more accurate survival predictions.
A key innovation is the Transport-Guided Attention module, which allows the model to dynamically focus on the most relevant parts of the image, text, and genomic data when making its predictions. This helps the model capture the complex interactions between the different data modalities.
The researchers tested their approach on several cancer datasets and found that it outperformed other methods that only used a single type of data. This suggests that integrating multiple data sources can provide a more complete picture of a patient's condition and lead to better clinical decision-making.
Technical Explanation
The authors propose a Multimodal Cross-Task Interaction for Survival Analysis in Whole Slide Pathological Images. Their framework combines text, image, and genomic data to jointly learn representations and make survival predictions.
A key component is the Transport-Guided Attention (TGA) module, which enables cross-modal interaction and information sharing. TGA dynamically attends to the most relevant parts of the input modalities when making survival predictions.
The overall architecture consists of modality-specific encoders that map the input data into a shared latent space. The TGA module then fuses the encoded representations and passes them through a survival prediction head.
The authors evaluate their approach on multiple cancer datasets, including TCGA and PAIP 2019. They demonstrate improved performance over unimodal baselines and other multimodal methods, highlighting the benefits of their cross-modal interaction approach.
Critical Analysis
The paper provides a compelling approach to integrating multiple data modalities for survival analysis in cancer. The authors' use of the Transport-Guided Attention module is a novel and promising technique for enabling effective cross-modal interaction.
However, the paper does not fully address some potential limitations and areas for further research. For example, the model's performance may be sensitive to the quality and availability of the input data, particularly the genomic data. Handling missing or noisy data could be an important consideration for real-world deployment.
Additionally, the interpretability of the model's predictions is not thoroughly explored. Understanding how the different data modalities contribute to the survival predictions could be valuable for clinicians to trust and act on the model's outputs.
Further research could also investigate the generalization of the approach to other types of medical images and tasks beyond survival analysis, such as disease diagnosis or prognosis.
Conclusion
This paper presents a novel multimodal deep learning framework for survival analysis on whole slide pathological images. By combining text, image, and genomic data, the model can learn more comprehensive representations of the disease and make more accurate survival predictions.
The key innovation is the Transport-Guided Attention module, which enables effective cross-modal interaction and information sharing. The empirical results demonstrate the benefits of this approach compared to unimodal and other multimodal methods.
While the paper shows promising results, further research is needed to address potential limitations, such as data quality and model interpretability. Expanding the approach to other medical tasks could also broaden its impact and applicability in the field of computational pathology and oncology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multimodal Cross-Task Interaction for Survival Analysis in Whole Slide Pathological Images
Songhan Jiang, Zhengyu Gan, Linghan Cai, Yifeng Wang, Yongbing Zhang
Survival prediction, utilizing pathological images and genomic profiles, is increasingly important in cancer analysis and prognosis. Despite significant progress, precise survival analysis still faces two main challenges: (1) The massive pixels contained in whole slide images (WSIs) complicate the process of pathological images, making it difficult to generate an effective representation of the tumor microenvironment (TME). (2) Existing multimodal methods often rely on alignment strategies to integrate complementary information, which may lead to information loss due to the inherent heterogeneity between pathology and genes. In this paper, we propose a Multimodal Cross-Task Interaction (MCTI) framework to explore the intrinsic correlations between subtype classification and survival analysis tasks. Specifically, to capture TME-related features in WSIs, we leverage the subtype classification task to mine tumor regions. Simultaneously, multi-head attention mechanisms are applied in genomic feature extraction, adaptively performing genes grouping to obtain task-related genomic embedding. With the joint representation of pathological images and genomic data, we further introduce a Transport-Guided Attention (TGA) module that uses optimal transport theory to model the correlation between subtype classification and survival analysis tasks, effectively transferring potential information. Extensive experiments demonstrate the superiority of our approaches, with MCTI outperforming state-of-the-art frameworks on three public benchmarks. href{https://github.com/jsh0792/MCTI}{https://github.com/jsh0792/MCTI}.
Read more6/26/2024

0
Multimodal Prototyping for cancer survival prediction
Andrew H. Song, Richard J. Chen, Guillaume Jaume, Anurag J. Vaidya, Alexander S. Baras, Faisal Mahmood
Multimodal survival methods combining gigapixel histology whole-slide images (WSIs) and transcriptomic profiles are particularly promising for patient prognostication and stratification. Current approaches involve tokenizing the WSIs into smaller patches (>10,000 patches) and transcriptomics into gene groups, which are then integrated using a Transformer for predicting outcomes. However, this process generates many tokens, which leads to high memory requirements for computing attention and complicates post-hoc interpretability analyses. Instead, we hypothesize that we can: (1) effectively summarize the morphological content of a WSI by condensing its constituting tokens using morphological prototypes, achieving more than 300x compression; and (2) accurately characterize cellular functions by encoding the transcriptomic profile with biological pathway prototypes, all in an unsupervised fashion. The resulting multimodal tokens are then processed by a fusion network, either with a Transformer or an optimal transport cross-alignment, which now operates with a small and fixed number of tokens without approximations. Extensive evaluation on six cancer types shows that our framework outperforms state-of-the-art methods with much less computation while unlocking new interpretability analyses.
Read more7/2/2024
🔮
0
Modeling Dense Multimodal Interactions Between Biological Pathways and Histology for Survival Prediction
Guillaume Jaume, Anurag Vaidya, Richard Chen, Drew Williamson, Paul Liang, Faisal Mahmood
Integrating whole-slide images (WSIs) and bulk transcriptomics for predicting patient survival can improve our understanding of patient prognosis. However, this multimodal task is particularly challenging due to the different nature of these data: WSIs represent a very high-dimensional spatial description of a tumor, while bulk transcriptomics represent a global description of gene expression levels within that tumor. In this context, our work aims to address two key challenges: (1) how can we tokenize transcriptomics in a semantically meaningful and interpretable way?, and (2) how can we capture dense multimodal interactions between these two modalities? Specifically, we propose to learn biological pathway tokens from transcriptomics that can encode specific cellular functions. Together with histology patch tokens that encode the different morphological patterns in the WSI, we argue that they form appropriate reasoning units for downstream interpretability analyses. We propose fusing both modalities using a memory-efficient multimodal Transformer that can model interactions between pathway and histology patch tokens. Our proposed model, SURVPATH, achieves state-of-the-art performance when evaluated against both unimodal and multimodal baselines on five datasets from The Cancer Genome Atlas. Our interpretability framework identifies key multimodal prognostic factors, and, as such, can provide valuable insights into the interaction between genotype and phenotype, enabling a deeper understanding of the underlying biological mechanisms at play. We make our code public at: https://github.com/ajv012/SurvPath.
Read more4/16/2024
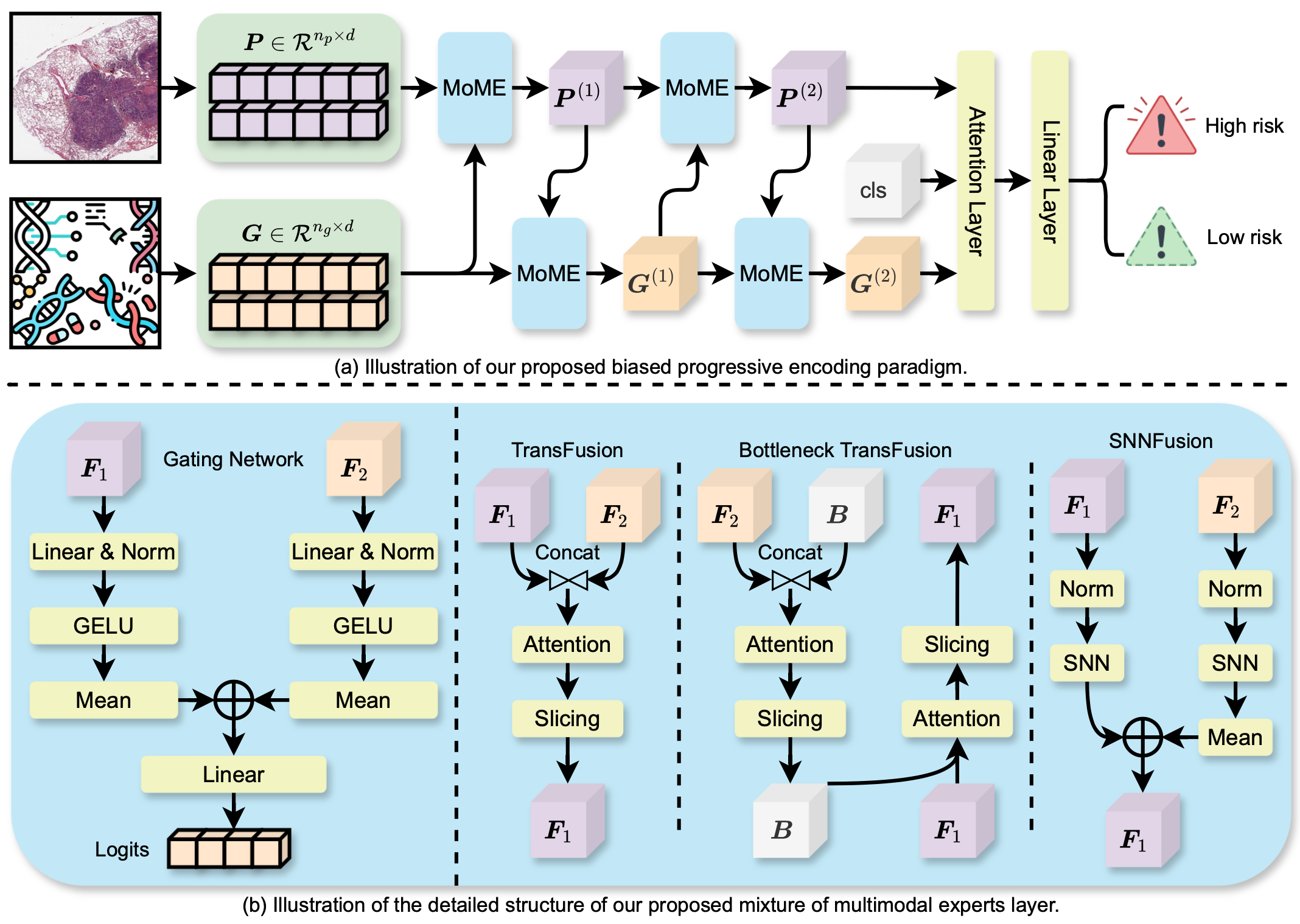
0
MoME: Mixture of Multimodal Experts for Cancer Survival Prediction
Conghao Xiong, Hao Chen, Hao Zheng, Dong Wei, Yefeng Zheng, Joseph J. Y. Sung, Irwin King
Survival analysis, as a challenging task, requires integrating Whole Slide Images (WSIs) and genomic data for comprehensive decision-making. There are two main challenges in this task: significant heterogeneity and complex inter- and intra-modal interactions between the two modalities. Previous approaches utilize co-attention methods, which fuse features from both modalities only once after separate encoding. However, these approaches are insufficient for modeling the complex task due to the heterogeneous nature between the modalities. To address these issues, we propose a Biased Progressive Encoding (BPE) paradigm, performing encoding and fusion simultaneously. This paradigm uses one modality as a reference when encoding the other. It enables deep fusion of the modalities through multiple alternating iterations, progressively reducing the cross-modal disparities and facilitating complementary interactions. Besides modality heterogeneity, survival analysis involves various biomarkers from WSIs, genomics, and their combinations. The critical biomarkers may exist in different modalities under individual variations, necessitating flexible adaptation of the models to specific scenarios. Therefore, we further propose a Mixture of Multimodal Experts (MoME) layer to dynamically selects tailored experts in each stage of the BPE paradigm. Experts incorporate reference information from another modality to varying degrees, enabling a balanced or biased focus on different modalities during the encoding process. Extensive experimental results demonstrate the superior performance of our method on various datasets, including TCGA-BLCA, TCGA-UCEC and TCGA-LUAD. Codes are available at https://github.com/BearCleverProud/MoME.
Read more6/17/2024