MonoCoder: Domain-Specific Code Language Model for HPC Codes and Tasks

0

Sign in to get full access
Overview
- This research explores the potential of domain-specific code language models for high-performance computing (HPC) codes and tasks.
- The work was supported by various organizations, including the Israeli Council for Higher Education, Intel Corporation, and the Lynn and William Frankel Center for Computer Science.
- Computational support was provided by HPE HPC & AI Cloud, Intel Developer Cloud, and the NegevHPC project.
Plain English Explanation
In this research, the authors investigate how specialized language models can be used to work with complex computer programs, particularly those used in high-performance computing (HPC). HPC is a field that deals with building and using powerful computers to solve large, complex problems that require a lot of processing power, such as weather forecasting, simulations of physical systems, and data analysis.
The researchers developed a new type of language model that is tailored to understand and work with HPC code, which can be quite different from the types of text that typical language models are trained on. This specialized model can be used for tasks like generating new HPC code, translating code between different programming languages, and helping programmers understand and debug existing HPC code.
The key idea is that by training a language model on a large amount of HPC code, it can learn the unique patterns and structures of this type of code, allowing it to work with it more effectively than a general-purpose language model. This could be particularly useful for tasks like automating the creation of HPC code or assisting human programmers who work on complex HPC projects.
Technical Explanation
The research paper explores the potential of domain-specific code language models for high-performance computing (HPC) codes and tasks. The authors developed specialized language models that are trained on large datasets of HPC code, allowing them to better understand and work with this type of complex, technical content compared to general-purpose language models.
The researchers investigated several use cases for these domain-specific code language models in the context of HPC, including code generation, code translation, and code understanding. For example, they showed how these models could be used to automatically generate new HPC code or translate existing code between different programming languages, which could save time and effort for HPC programmers.
The paper also discusses the architectural considerations and training approaches used to develop these specialized language models. This includes techniques like fine-tuning general-purpose language models on HPC code datasets and pre-training models from scratch on HPC-specific corpora.
The authors conducted extensive experiments to evaluate the performance of their domain-specific code language models on a variety of HPC-related tasks and benchmarks. The results demonstrate the significant potential of this approach, with the specialized models outperforming general-purpose language models in many cases.
Critical Analysis
The research presented in this paper highlights the promising potential of domain-specific code language models for HPC applications. By tailoring language models to the unique characteristics of HPC code, the researchers were able to demonstrate substantial performance gains compared to more general-purpose approaches.
One potential limitation mentioned in the paper is the availability and quality of HPC code datasets used for training these specialized models. The authors noted that expanding and improving these datasets could further enhance the capabilities of their domain-specific language models.
Additionally, the paper does not extensively explore the limitations or potential downsides of this approach. For example, it would be valuable to understand the computational and memory requirements of these specialized models, as well as any biases or shortcomings they may exhibit compared to human HPC experts.
Further research could also investigate the generalizability of these domain-specific code language models beyond the HPC domain, and explore their applicability to other specialized programming languages or application areas.
Conclusion
This research demonstrates the promising potential of domain-specific code language models for high-performance computing (HPC) codes and tasks. By tailoring language models to the unique characteristics of HPC code, the authors were able to create specialized models that outperform general-purpose approaches in a variety of HPC-related applications, such as code generation, translation, and understanding.
The findings of this work suggest that the development of domain-specific code language models could have significant implications for the productivity and efficiency of HPC programmers and researchers, potentially accelerating the development of complex, high-performance computational systems. As the field of HPC continues to evolve, this type of specialized AI-powered tooling could become an increasingly valuable asset for the HPC community.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MonoCoder: Domain-Specific Code Language Model for HPC Codes and Tasks
Tal Kadosh, Niranjan Hasabnis, Vy A. Vo, Nadav Schneider, Neva Krien, Mihai Capota, Abdul Wasay, Nesreen Ahmed, Ted Willke, Guy Tamir, Yuval Pinter, Timothy Mattson, Gal Oren
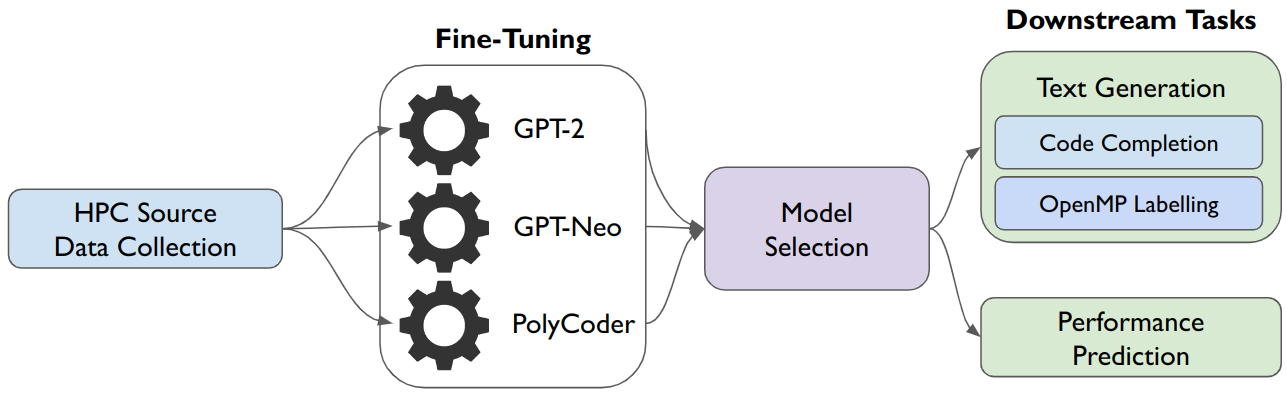
With easier access to powerful compute resources, there is a growing trend in AI for software development to develop large language models (LLMs) to address a variety of programming tasks. Even LLMs applied to tasks from the high-performance computing (HPC) domain are huge in size and demand expensive compute resources for training. This is partly because LLMs for HPC tasks are obtained by finetuning existing LLMs that support several natural and/or programming languages. We found this design choice confusing - why do we need LLMs trained on natural languages and programming languages unrelated to HPC for HPC-specific tasks? In this line of work, we aim to question choices made by existing LLMs by developing smaller language models (LMs) for specific domains - we call them domain-specific LMs. Specifically, we start with HPC as a domain and build an HPC-specific LM, named MonoCoder, which is orders of magnitude smaller than existing LMs but delivers better performance on non-HPC and HPC codes. Specifically, we pre-trained MonoCoder on an HPC-specific dataset (named HPCorpus) of C and C++ programs mined from GitHub. We evaluated the performance of MonoCoder against state-of-the-art multi-lingual LLMs. Results demonstrate that MonoCoder, although much smaller than existing LMs, outperforms other LLMs on normalized-perplexity tests (in relation to model size) while also delivering competing CodeBLEU scores for high-performance and parallel code generations. In other words, results suggest that MonoCoder understands HPC code better than state-of-the-art LLMs.
Read more9/23/2024
0
HPC-Coder: Modeling Parallel Programs using Large Language Models
Daniel Nichols, Aniruddha Marathe, Harshitha Menon, Todd Gamblin, Abhinav Bhatele
Parallel programs in high performance computing (HPC) continue to grow in complexity and scale in the exascale era. The diversity in hardware and parallel programming models make developing, optimizing, and maintaining parallel software even more burdensome for developers. One way to alleviate some of these burdens is with automated development and analysis tools. Such tools can perform complex and/or remedial tasks for developers that increase their productivity and decrease the chance for error. Until recently, such tools for code development and performance analysis have been limited in the complexity of tasks they can perform, especially for parallel programs. However, with recent advancements in language modeling, and the availability of large amounts of open-source code related data, these tools have started to utilize predictive language models to automate more complex tasks. In this paper, we show how large language models (LLMs) can be applied to tasks specific to high performance and scientific codes. We introduce a new dataset of HPC and scientific codes and use it to fine-tune several pre-trained models. We compare several pre-trained LLMs on HPC-related tasks and introduce a new model, HPC-Coder, fine-tuned on parallel codes. In our experiments, we show that this model can auto-complete HPC functions where generic models cannot, decorate for loops with OpenMP pragmas, and model performance changes in scientific application repositories as well as programming competition solutions.
Read more5/15/2024

0
MoTCoder: Elevating Large Language Models with Modular of Thought for Challenging Programming Tasks
Jingyao Li, Pengguang Chen, Bin Xia, Hong Xu, Jiaya Jia
Large Language Models (LLMs) have showcased impressive capabilities in handling straightforward programming tasks. However, their performance tends to falter when confronted with more challenging programming problems. We observe that conventional models often generate solutions as monolithic code blocks, restricting their effectiveness in tackling intricate questions. To overcome this limitation, we present Modular-of-Thought Coder (MoTCoder). We introduce a pioneering framework for MoT instruction tuning, designed to promote the decomposition of tasks into logical sub-tasks and sub-modules. Our investigations reveal that, through the cultivation and utilization of sub-modules, MoTCoder significantly improves both the modularity and correctness of the generated solutions, leading to substantial relative pass@1 improvements of 12.9% on APPS and 9.43% on CodeContests. Our codes are available at https://github.com/dvlab-research/MoTCoder.
Read more8/23/2024
🛸
0
MPIrigen: MPI Code Generation through Domain-Specific Language Models
Nadav Schneider, Niranjan Hasabnis, Vy A. Vo, Tal Kadosh, Neva Krien, Mihai Capotu{a}, Guy Tamir, Ted Willke, Nesreen Ahmed, Yuval Pinter, Timothy Mattson, Gal Oren
The imperative need to scale computation across numerous nodes highlights the significance of efficient parallel computing, particularly in the realm of Message Passing Interface (MPI) integration. The challenging parallel programming task of generating MPI-based parallel programs has remained unexplored. This study first investigates the performance of state-of-the-art language models in generating MPI-based parallel programs. Findings reveal that widely used models such as GPT-3.5 and PolyCoder (specialized multi-lingual code models) exhibit notable performance degradation, when generating MPI-based programs compared to general-purpose programs. In contrast, domain-specific models such as MonoCoder, which are pretrained on MPI-related programming languages of C and C++, outperform larger models. Subsequently, we introduce a dedicated downstream task of MPI-based program generation by fine-tuning MonoCoder on HPCorpusMPI. We call the resulting model as MPIrigen. We propose an innovative preprocessing for completion only after observing the whole code, thus enabling better completion with a wider context. Comparative analysis against GPT-3.5 zero-shot performance, using a novel HPC-oriented evaluation method, demonstrates that MPIrigen excels in generating accurate MPI functions up to 0.8 accuracy in location and function predictions, and with more than 0.9 accuracy for argument predictions. The success of this tailored solution underscores the importance of domain-specific fine-tuning in optimizing language models for parallel computing code generation, paving the way for a new generation of automatic parallelization tools. The sources of this work are available at our GitHub MPIrigen repository: https://github.com/Scientific-Computing-Lab-NRCN/MPI-rigen
Read more4/24/2024