MorphText: Deep Morphology Regularized Arbitrary-shape Scene Text Detection

0

Sign in to get full access
Overview
- Introduces a new method called "MorphText" for accurate detection of arbitrary-shaped scene text
- Addresses limitations of traditional "bottom-up" text detection approaches
- Proposes a deep learning architecture that leverages morphological information to improve text segmentation
- Demonstrates state-of-the-art performance on standard scene text detection benchmarks
Plain English Explanation
<a href="https://aimodels.fyi/papers/arxiv/whats-wrong-bottom-up-methods-arbitrary-shape">Traditional "bottom-up" methods</a> for scene text detection often struggle with text that has irregular or complex shapes. The MorphText approach aims to overcome these limitations by incorporating a deep learning architecture that takes into account the morphological structure of text.
The key insight is that text characters and words have inherent geometric and topological properties that can provide valuable cues for accurate segmentation. By <a href="https://aimodels.fyi/papers/arxiv/labeled-morphological-segmentation-semi-markov-models">modeling these morphological features</a>, the MorphText model is better able to distinguish text from non-text elements in challenging real-world scenes.
The architecture leverages a combination of convolutional neural networks and attention-based mechanisms to jointly learn visual features and morphological regularities. This allows the model to adaptively capture the diverse shapes and layouts of text encountered in natural images, leading to significant performance gains compared to previous methods.
Technical Explanation
The MorphText model consists of several key components:
- Backbone Network: A convolutional neural network (CNN) that extracts visual features from the input image.
- Morphological Attention: An attention-based module that learns to focus on the morphological structure of text, extracting cues about character and word shapes.
- Text Segmentation: A segmentation head that combines the visual and morphological features to produce accurate text proposals, even for arbitrarily-shaped text.
The model is trained end-to-end using a multi-task loss that encourages the network to learn robust text representations and accurately delineate text regions. Experiments on standard scene text detection benchmarks, such as <a href="https://aimodels.fyi/papers/arxiv/seeing-text-dark-algorithm-benchmark">SCUT-CTW1500</a> and <a href="https://aimodels.fyi/papers/arxiv/dlora-trocr-mixed-text-mode-optical-character">Total-Text</a>, demonstrate that MorphText achieves state-of-the-art performance, outperforming previous methods by a significant margin.
Critical Analysis
The MorphText approach represents an important advance in scene text detection, particularly for handling arbitrary-shaped text. By incorporating morphological information, the model is able to better capture the diverse visual characteristics of text in natural images.
However, the paper does not discuss the computational complexity or inference speed of the MorphText model, which could be a practical concern for real-world applications. Additionally, the generalization of the approach to languages with different writing systems or scripts is not explicitly addressed.
Further research could explore ways to make the model more efficient or investigate its performance in multilingual settings. Integrating the MorphText approach with other text understanding tasks, such as <a href="https://aimodels.fyi/papers/arxiv/texture-aware-shape-guided-transformer-sequential-deepfake">text recognition</a> or <a href="https://aimodels.fyi/papers/arxiv/seeing-text-dark-algorithm-benchmark">text spotting</a>, could also be a promising direction for future work.
Conclusion
The MorphText method represents an important step forward in scene text detection, addressing key limitations of traditional approaches. By leveraging morphological information, the model is able to accurately segment text with complex and arbitrary shapes, outperforming state-of-the-art methods on standard benchmarks.
This research highlights the potential of incorporating structural and geometric cues into deep learning architectures for computer vision tasks. The insights gained from this work could also be applicable to other domains where the inherent properties of the target objects play a crucial role in detection and segmentation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MorphText: Deep Morphology Regularized Arbitrary-shape Scene Text Detection
Chengpei Xu, Wenjing Jia, Ruomei Wang, Xiaonan Luo, Xiangjian He
Bottom-up text detection methods play an important role in arbitrary-shape scene text detection but there are two restrictions preventing them from achieving their great potential, i.e., 1) the accumulation of false text segment detections, which affects subsequent processing, and 2) the difficulty of building reliable connections between text segments. Targeting these two problems, we propose a novel approach, named ``MorphText, to capture the regularity of texts by embedding deep morphology for arbitrary-shape text detection. Towards this end, two deep morphological modules are designed to regularize text segments and determine the linkage between them. First, a Deep Morphological Opening (DMOP) module is constructed to remove false text segment detections generated in the feature extraction process. Then, a Deep Morphological Closing (DMCL) module is proposed to allow text instances of various shapes to stretch their morphology along their most significant orientation while deriving their connections. Extensive experiments conducted on four challenging benchmark datasets (CTW1500, Total-Text, MSRA-TD500 and ICDAR2017) demonstrate that our proposed MorphText outperforms both top-down and bottom-up state-of-the-art arbitrary-shape scene text detection approaches.
Read more4/29/2024
🔎
0
What's Wrong with the Bottom-up Methods in Arbitrary-shape Scene Text Detection
Chengpei Xu, Wenjing Jia, Tingcheng Cui, Ruomei Wang, Yuan-fang Zhang, Xiangjian He
The latest trend in the bottom-up perspective for arbitrary-shape scene text detection is to reason the links between text segments using Graph Convolutional Network (GCN). Notwithstanding, the performance of the best performing bottom-up method is still inferior to that of the best performing top-down method even with the help of GCN. We argue that this is not mainly caused by the limited feature capturing ability of the text proposal backbone or GCN, but by their failure to make a full use of visual-relational features for suppressing false detection, as well as the sub-optimal route-finding mechanism used for grouping text segments. In this paper, we revitalize the classic text detection frameworks by aggregating the visual-relational features of text with two effective false positive/negative suppression mechanisms. First, dense overlapping text segments depicting the `characterness' and `streamline' of text are generated for further relational reasoning and weakly supervised segment classification. Here, relational graph features are used for suppressing false positives/negatives. Then, to fuse the relational features with visual features, a Location-Aware Transfer (LAT) module is designed to transfer text's relational features into visual compatible features with a Fuse Decoding (FD) module to enhance the representation of text regions for the second step suppression. Finally, a novel multiple-text-map-aware contour-approximation strategy is developed, instead of the widely-used route-finding process. Experiments conducted on five benchmark datasets, i.e., CTW1500, Total-Text, ICDAR2015, MSRA-TD500, and MLT2017 demonstrate that our method outperforms the state-of-the-art performance when being embedded in a classic text detection framework, which revitalises the superb strength of the bottom-up methods.
Read more4/23/2024

0
DNTextSpotter: Arbitrary-Shaped Scene Text Spotting via Improved Denoising Training
Yu Xie, Qian Qiao, Jun Gao, Tianxiang Wu, Shaoyao Huang, Jiaqing Fan, Ziqiang Cao, Zili Wang, Yue Zhang, Jielei Zhang, Huyang Sun
More and more end-to-end text spotting methods based on Transformer architecture have demonstrated superior performance. These methods utilize a bipartite graph matching algorithm to perform one-to-one optimal matching between predicted objects and actual objects. However, the instability of bipartite graph matching can lead to inconsistent optimization targets, thereby affecting the training performance of the model. Existing literature applies denoising training to solve the problem of bipartite graph matching instability in object detection tasks. Unfortunately, this denoising training method cannot be directly applied to text spotting tasks, as these tasks need to perform irregular shape detection tasks and more complex text recognition tasks than classification. To address this issue, we propose a novel denoising training method (DNTextSpotter) for arbitrary-shaped text spotting. Specifically, we decompose the queries of the denoising part into noised positional queries and noised content queries. We use the four Bezier control points of the Bezier center curve to generate the noised positional queries. For the noised content queries, considering that the output of the text in a fixed positional order is not conducive to aligning position with content, we employ a masked character sliding method to initialize noised content queries, thereby assisting in the alignment of text content and position. To improve the model's perception of the background, we further utilize an additional loss function for background characters classification in the denoising training part.Although DNTextSpotter is conceptually simple, it outperforms the state-of-the-art methods on four benchmarks (Total-Text, SCUT-CTW1500, ICDAR15, and Inverse-Text), especially yielding an improvement of 11.3% against the best approach in Inverse-Text dataset.
Read more8/2/2024
0
Unsupervised Morphological Tree Tokenizer
Qingyang Zhu, Xiang Hu, Pengyu Ji, Wei Wu, Kewei Tu
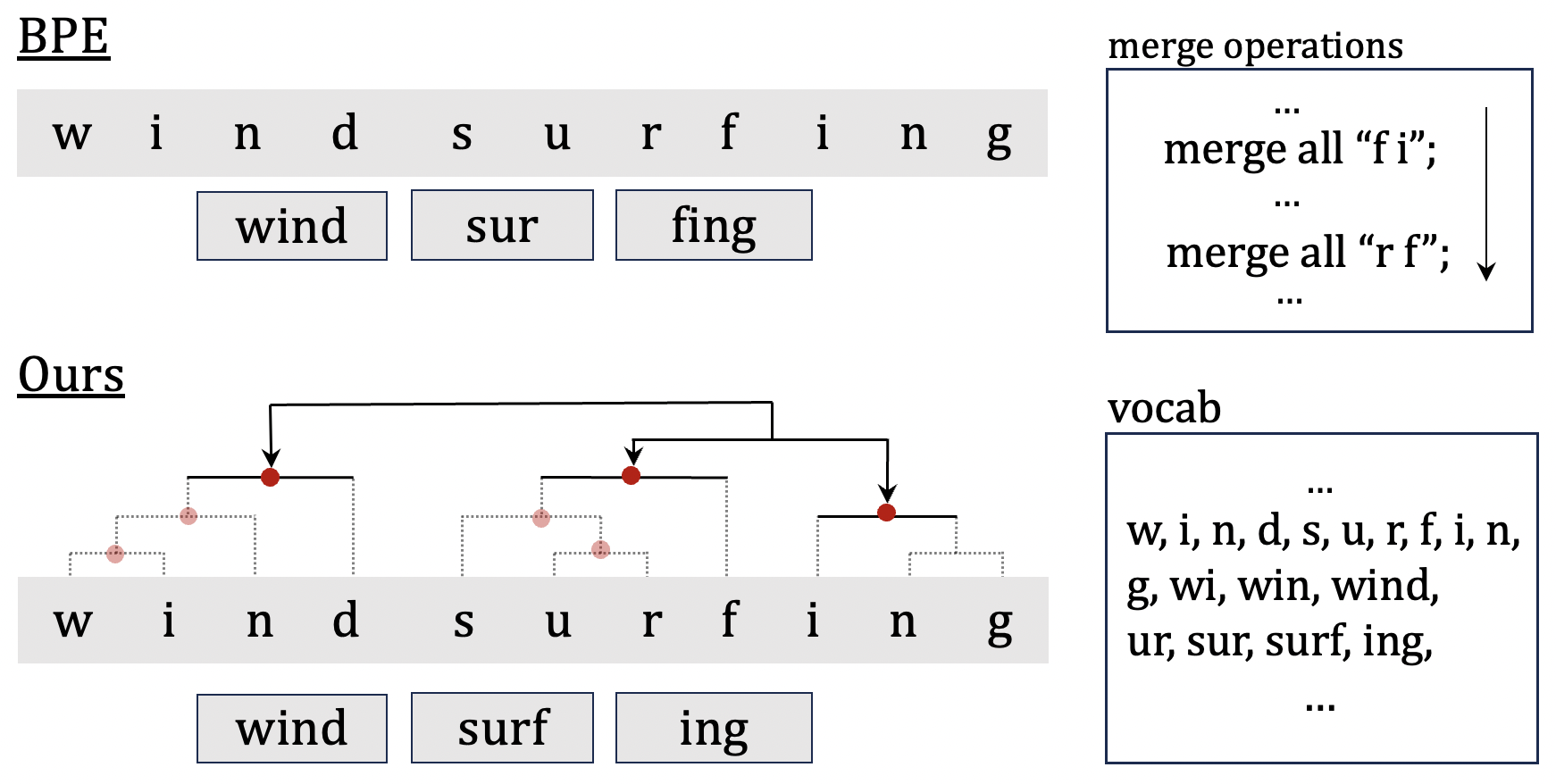
As a cornerstone in language modeling, tokenization involves segmenting text inputs into pre-defined atomic units. Conventional statistical tokenizers often disrupt constituent boundaries within words, thereby corrupting semantic information. To address this drawback, we introduce morphological structure guidance to tokenization and propose a deep model to induce character-level structures of words. Specifically, the deep model jointly encodes internal structures and representations of words with a mechanism named $textit{MorphOverriding}$ to ensure the indecomposability of morphemes. By training the model with self-supervised objectives, our method is capable of inducing character-level structures that align with morphological rules without annotated training data. Based on the induced structures, our algorithm tokenizes words through vocabulary matching in a top-down manner. Empirical results indicate that the proposed method effectively retains complete morphemes and outperforms widely adopted methods such as BPE and WordPiece on both morphological segmentation tasks and language modeling tasks. The code will be released later.
Read more6/24/2024