MoSca: Dynamic Gaussian Fusion from Casual Videos via 4D Motion Scaffolds
2405.17421
0
0
Abstract
We introduce 4D Motion Scaffolds (MoSca), a neural information processing system designed to reconstruct and synthesize novel views of dynamic scenes from monocular videos captured casually in the wild. To address such a challenging and ill-posed inverse problem, we leverage prior knowledge from foundational vision models, lift the video data to a novel Motion Scaffold (MoSca) representation, which compactly and smoothly encodes the underlying motions / deformations. The scene geometry and appearance are then disentangled from the deformation field, and are encoded by globally fusing the Gaussians anchored onto the MoSca and optimized via Gaussian Splatting. Additionally, camera poses can be seamlessly initialized and refined during the dynamic rendering process, without the need for other pose estimation tools. Experiments demonstrate state-of-the-art performance on dynamic rendering benchmarks.
Create account to get full access
Overview
- This paper introduces MoSca, a novel method for generating dynamic 3D reconstructions from casual video inputs.
- The key idea is to use a 4D motion scaffold, a sparse set of keypoints that capture the dynamic geometry of the scene, as the basis for fusing multiple Gaussian distributions into a consistent 3D representation.
- The proposed approach can handle complex, non-rigid motions and produce high-quality 4D reconstructions from low-quality video inputs.
Plain English Explanation
MoSca is a new technique that can create detailed 3D models from casual, everyday video recordings. Rather than trying to reconstruct the entire 3D scene at every frame, the method focuses on capturing the key movements and deformations using a sparse set of 3D points, called a "4D motion scaffold."
This motion scaffold acts as a lightweight structural framework that guides the fusion of multiple Gaussian distributions, which represent the 3D shape at each frame. By using this sparse representation, MoSca is able to handle complex, non-rigid motions that would be difficult to model using traditional 3D reconstruction approaches.
The end result is a high-quality 4D reconstruction - a 3D model that evolves dynamically over time - created from low-quality video inputs. This could be useful for a variety of applications, such as 3D animation, virtual reality, or even computational photography.
Technical Explanation
The core of the MoSca approach is the 4D motion scaffold, which captures the dynamic geometry of the scene. This sparse set of 3D keypoints is estimated from the input video and used to guide the fusion of multiple Gaussian distributions into a coherent 3D representation.
The authors propose a sparse-to-dense optimization to efficiently propagate the motion scaffold information and fuse the Gaussian distributions, resulting in a temporally consistent 4D reconstruction. This allows MoSca to handle complex, non-rigid motions that would be challenging for traditional 3D reconstruction methods.
The authors demonstrate the effectiveness of MoSca on a variety of casual video inputs, showing that it can produce high-quality 4D reconstructions even from low-quality source material. This represents an important advance in the field of video-to-3D generation.
Critical Analysis
The MoSca approach shows promising results, but the authors acknowledge several limitations. The 4D motion scaffold is still a sparse representation, which means that fine-grained details may not be captured accurately. Additionally, the method relies on accurate keypoint estimation, which could be challenging in certain scenarios, such as occlusions or fast motions.
Another potential issue is the computational complexity of the optimization process, which could limit the scalability of the approach for very long or high-resolution videos. The authors mention plans to explore more efficient optimization strategies to address this concern.
Overall, MoSca represents an interesting and innovative approach to 4D reconstruction from casual video inputs. While it has some limitations, the core ideas and the demonstrated results suggest that this could be a fruitful direction for further research and development in the field of 3D computer vision and graphics.
Conclusion
The MoSca method introduced in this paper offers a novel way to generate high-quality 4D reconstructions from low-quality video inputs. By using a sparse 4D motion scaffold to guide the fusion of Gaussian distributions, the approach can handle complex, non-rigid motions and produce temporally consistent 3D models.
This work represents an important step forward in the field of video-to-3D generation, with potential applications in areas such as 3D animation, virtual reality, and computational photography. While the method has some limitations, the core ideas and the demonstrated results suggest that this could be a fruitful direction for further research and development in 3D computer vision and graphics.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

MoDGS: Dynamic Gaussian Splatting from Causually-captured Monocular Videos
Qingming Liu, Yuan Liu, Jiepeng Wang, Xianqiang Lv, Peng Wang, Wenping Wang, Junhui Hou
0
0
In this paper, we propose MoDGS, a new pipeline to render novel-view images in dynamic scenes using only casually captured monocular videos. Previous monocular dynamic NeRF or Gaussian Splatting methods strongly rely on the rapid movement of input cameras to construct multiview consistency but fail to reconstruct dynamic scenes on casually captured input videos whose cameras are static or move slowly. To address this challenging task, MoDGS adopts recent single-view depth estimation methods to guide the learning of the dynamic scene. Then, a novel 3D-aware initialization method is proposed to learn a reasonable deformation field and a new robust depth loss is proposed to guide the learning of dynamic scene geometry. Comprehensive experiments demonstrate that MoDGS is able to render high-quality novel view images of dynamic scenes from just a casually captured monocular video, which outperforms baseline methods by a significant margin.
6/4/2024
SC4D: Sparse-Controlled Video-to-4D Generation and Motion Transfer
Zijie Wu, Chaohui Yu, Yanqin Jiang, Chenjie Cao, Fan Wang, Xiang Bai
0
0
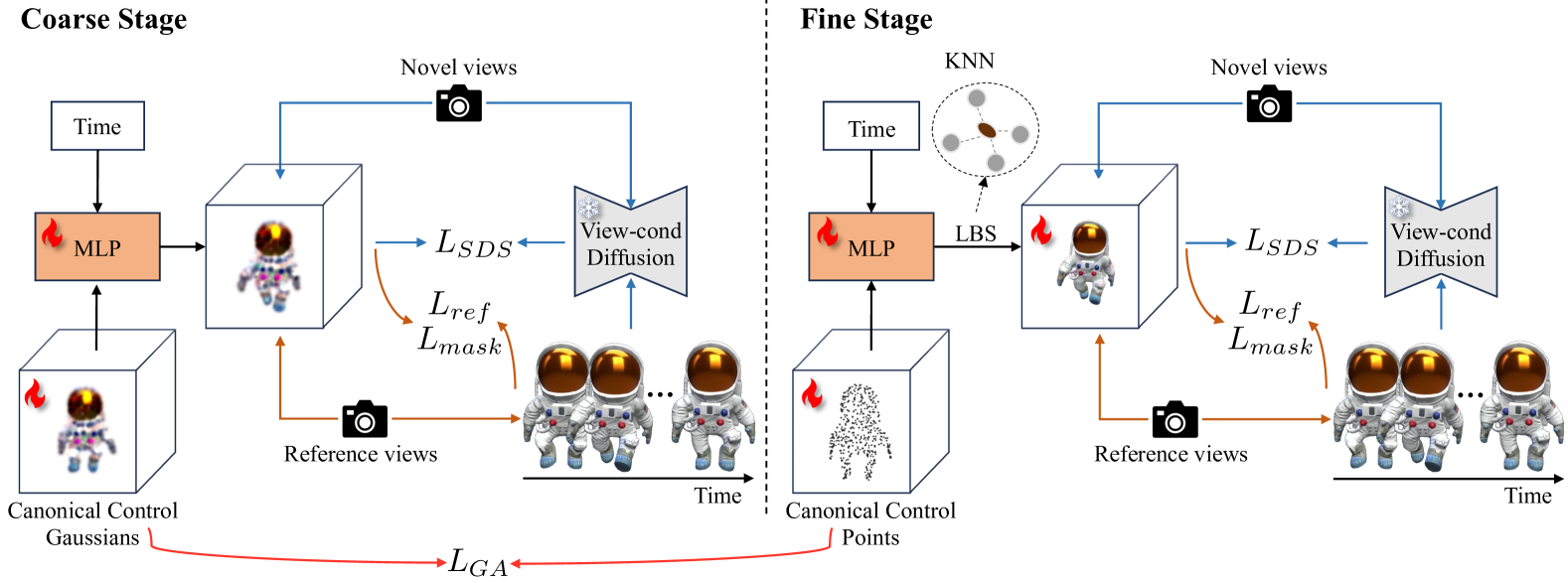
Recent advances in 2D/3D generative models enable the generation of dynamic 3D objects from a single-view video. Existing approaches utilize score distillation sampling to form the dynamic scene as dynamic NeRF or dense 3D Gaussians. However, these methods struggle to strike a balance among reference view alignment, spatio-temporal consistency, and motion fidelity under single-view conditions due to the implicit nature of NeRF or the intricate dense Gaussian motion prediction. To address these issues, this paper proposes an efficient, sparse-controlled video-to-4D framework named SC4D, that decouples motion and appearance to achieve superior video-to-4D generation. Moreover, we introduce Adaptive Gaussian (AG) initialization and Gaussian Alignment (GA) loss to mitigate shape degeneration issue, ensuring the fidelity of the learned motion and shape. Comprehensive experimental results demonstrate that our method surpasses existing methods in both quality and efficiency. In addition, facilitated by the disentangled modeling of motion and appearance of SC4D, we devise a novel application that seamlessly transfers the learned motion onto a diverse array of 4D entities according to textual descriptions.
4/8/2024
🤷
Dynamic Gaussians Mesh: Consistent Mesh Reconstruction from Monocular Videos
Isabella Liu, Hao Su, Xiaolong Wang
0
0
Modern 3D engines and graphics pipelines require mesh as a memory-efficient representation, which allows efficient rendering, geometry processing, texture editing, and many other downstream operations. However, it is still highly difficult to obtain high-quality mesh in terms of structure and detail from monocular visual observations. The problem becomes even more challenging for dynamic scenes and objects. To this end, we introduce Dynamic Gaussians Mesh (DG-Mesh), a framework to reconstruct a high-fidelity and time-consistent mesh given a single monocular video. Our work leverages the recent advancement in 3D Gaussian Splatting to construct the mesh sequence with temporal consistency from a video. Building on top of this representation, DG-Mesh recovers high-quality meshes from the Gaussian points and can track the mesh vertices over time, which enables applications such as texture editing on dynamic objects. We introduce the Gaussian-Mesh Anchoring, which encourages evenly distributed Gaussians, resulting better mesh reconstruction through mesh-guided densification and pruning on the deformed Gaussians. By applying cycle-consistent deformation between the canonical and the deformed space, we can project the anchored Gaussian back to the canonical space and optimize Gaussians across all time frames. During the evaluation on different datasets, DG-Mesh provides significantly better mesh reconstruction and rendering than baselines. Project page: https://www.liuisabella.com/DG-Mesh/
4/23/2024

New!Dynamic Gaussian Marbles for Novel View Synthesis of Casual Monocular Videos
Colton Stearns, Adam Harley, Mikaela Uy, Florian Dubost, Federico Tombari, Gordon Wetzstein, Leonidas Guibas
0
0
Gaussian splatting has become a popular representation for novel-view synthesis, exhibiting clear strengths in efficiency, photometric quality, and compositional edibility. Following its success, many works have extended Gaussians to 4D, showing that dynamic Gaussians maintain these benefits while also tracking scene geometry far better than alternative representations. Yet, these methods assume dense multi-view videos as supervision, constraining their use to controlled capture settings. In this work, we extend the capability of Gaussian scene representations to casually captured monocular videos. We show that existing 4D Gaussian methods dramatically fail in this setup because the monocular setting is underconstrained. Building off this finding, we propose Dynamic Gaussian Marbles (DGMarbles), consisting of three core modifications that target the difficulties of the monocular setting. First, DGMarbles uses isotropic Gaussian marbles, reducing the degrees of freedom of each Gaussian, and constraining the optimization to focus on motion and appearance over local shape. Second, DGMarbles employs a hierarchical divide-and-conquer learning strategy to guide the optimization towards solutions with coherent motion. Finally, DGMarbles adds image-level and geometry-level priors into the optimization, including a tracking loss that takes advantage of recent progress in point tracking. By constraining the optimization in these ways, DGMarbles learns Gaussian trajectories that enable novel-view rendering and accurately capture the 3D motion of the scene elements. We evaluate on the (monocular) Nvidia Dynamic Scenes dataset and the Dycheck iPhone dataset, and show that DGMarbles significantly outperforms other Gaussian baselines in quality, and is on-par with non-Gaussian representations, all while maintaining the efficiency, compositionality, editability, and tracking benefits of Gaussians.
6/28/2024