MotionDreamer: Zero-Shot 3D Mesh Animation from Video Diffusion Models

0

Sign in to get full access
Overview
- MotionDreamer is a new method for animating 3D mesh models using video diffusion models.
- It can generate realistic 3D animations from a single input image, without requiring any additional information like motion capture data.
- The key innovation is that MotionDreamer can learn to animate a 3D model in a zero-shot manner, meaning it can be applied to any unseen 3D model.
Plain English Explanation
MotionDreamer is a new way to bring 3D models to life through animation. It works by taking a single image of an object or character and using advanced AI to generate a realistic, animated 3D version of it. This is impressive because normally, animating 3D models requires a lot of additional information, like motion capture data, which can be expensive and time-consuming to obtain.
With MotionDreamer, the AI is able to learn how to animate any 3D model, even ones it's never seen before, just from watching videos. This "zero-shot" capability means the system can be applied flexibly to a wide range of 3D content, without needing to be retrained or customized for each new model.
The end result is natural-looking 3D animations that can be used for all sorts of applications, like visual effects, gaming, and even virtual reality experiences. By making 3D animation more accessible, MotionDreamer has the potential to unlock new creative possibilities and transform how we interact with digital content.
Technical Explanation
MotionDreamer works by leveraging the power of video diffusion models, which have recently emerged as a powerful tool for generating realistic videos from text or image prompts. The key insight behind MotionDreamer is that these diffusion models can also be used to animate 3D mesh models in a zero-shot manner.
The architecture of MotionDreamer consists of three main components:
- A 3D mesh encoder that converts a 3D mesh into a compact latent representation.
- A video diffusion model that is trained on a large corpus of videos to learn how to generate realistic video sequences.
- A 3D mesh decoder that takes the latent representations from the diffusion model and reconstructs the animated 3D mesh.
By combining these components, MotionDreamer can take a single input image of a 3D model and use the video diffusion model to generate an animation sequence that realistically deforms and moves the 3D mesh over time.
The key innovation of MotionDreamer is that the video diffusion model is trained in a way that allows it to be applied to any 3D mesh, without the need for additional training or fine-tuning. This is achieved by training the model on a diverse dataset of 3D mesh animations, so that it learns general principles of how 3D shapes can move and deform.
Critical Analysis
The authors of the MotionDreamer paper acknowledge several limitations and areas for future work. One key limitation is that the current system is limited to generating relatively short animation sequences, on the order of a few seconds. Scaling up to longer, more complex animations remains an open challenge.
Additionally, while MotionDreamer can generate realistic-looking animations, the authors note that the motion quality is not yet on par with animations created using traditional techniques like motion capture. Further research is needed to improve the realism and coherence of the generated motions.
Another area for improvement is the ability to incorporate additional constraints or control over the generated animations. The current system generates animations in a purely generative manner, which may not always align with the intended use case or artistic vision. Allowing users to guide or edit the generated animations could enhance the system's usefulness.
Despite these limitations, MotionDreamer represents a significant advancement in the field of 3D animation, demonstrating the potential of diffusion models to enable new, more accessible ways of creating digital content. As the underlying technologies continue to improve, we can expect to see even more impressive and versatile 3D animation tools emerge in the future.
Conclusion
MotionDreamer is a groundbreaking new method for animating 3D mesh models using video diffusion models. By leveraging the power of these advanced AI systems, MotionDreamer can generate realistic 3D animations from a single input image, without requiring any additional information like motion capture data.
The key innovation of MotionDreamer is its ability to animate any 3D model in a zero-shot manner, meaning it can be applied to unseen models without the need for retraining or customization. This flexible, scalable approach has the potential to transform how 3D animation is created, making it more accessible to a wider range of users and unlocking new creative possibilities.
While there are still some limitations to address, such as the length and realism of the generated animations, MotionDreamer represents a significant step forward in the field of 3D animation. As the underlying technologies continue to evolve, we can expect to see even more powerful and versatile tools for bringing digital content to life in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MotionDreamer: Zero-Shot 3D Mesh Animation from Video Diffusion Models
Lukas Uzolas, Elmar Eisemann, Petr Kellnhofer
Animation techniques bring digital 3D worlds and characters to life. However, manual animation is tedious and automated techniques are often specialized to narrow shape classes. In our work, we propose a technique for automatic re-animation of arbitrary 3D shapes based on a motion prior extracted from a video diffusion model. Unlike existing 4D generation methods, we focus solely on the motion, and we leverage an explicit mesh-based representation compatible with existing computer-graphics pipelines. Furthermore, our utilization of diffusion features enhances accuracy of our motion fitting. We analyze efficacy of these features for animation fitting and we experimentally validate our approach for two different diffusion models and four animation models. Finally, we demonstrate that our time-efficient zero-shot method achieves a superior performance re-animating a diverse set of 3D shapes when compared to existing techniques in a user study. The project website is located at https://lukas.uzolas.com/MotionDreamer.
Read more5/31/2024
🛸
0
MotionCraft: Physics-based Zero-Shot Video Generation
Luca Savant Aira, Antonio Montanaro, Emanuele Aiello, Diego Valsesia, Enrico Magli
Generating videos with realistic and physically plausible motion is one of the main recent challenges in computer vision. While diffusion models are achieving compelling results in image generation, video diffusion models are limited by heavy training and huge models, resulting in videos that are still biased to the training dataset. In this work we propose MotionCraft, a new zero-shot video generator to craft physics-based and realistic videos. MotionCraft is able to warp the noise latent space of an image diffusion model, such as Stable Diffusion, by applying an optical flow derived from a physics simulation. We show that warping the noise latent space results in coherent application of the desired motion while allowing the model to generate missing elements consistent with the scene evolution, which would otherwise result in artefacts or missing content if the flow was applied in the pixel space. We compare our method with the state-of-the-art Text2Video-Zero reporting qualitative and quantitative improvements, demonstrating the effectiveness of our approach to generate videos with finely-prescribed complex motion dynamics. Project page: https://mezzelfo.github.io/MotionCraft/
Read more5/24/2024
0
Animate3D: Animating Any 3D Model with Multi-view Video Diffusion
Yanqin Jiang, Chaohui Yu, Chenjie Cao, Fan Wang, Weiming Hu, Jin Gao
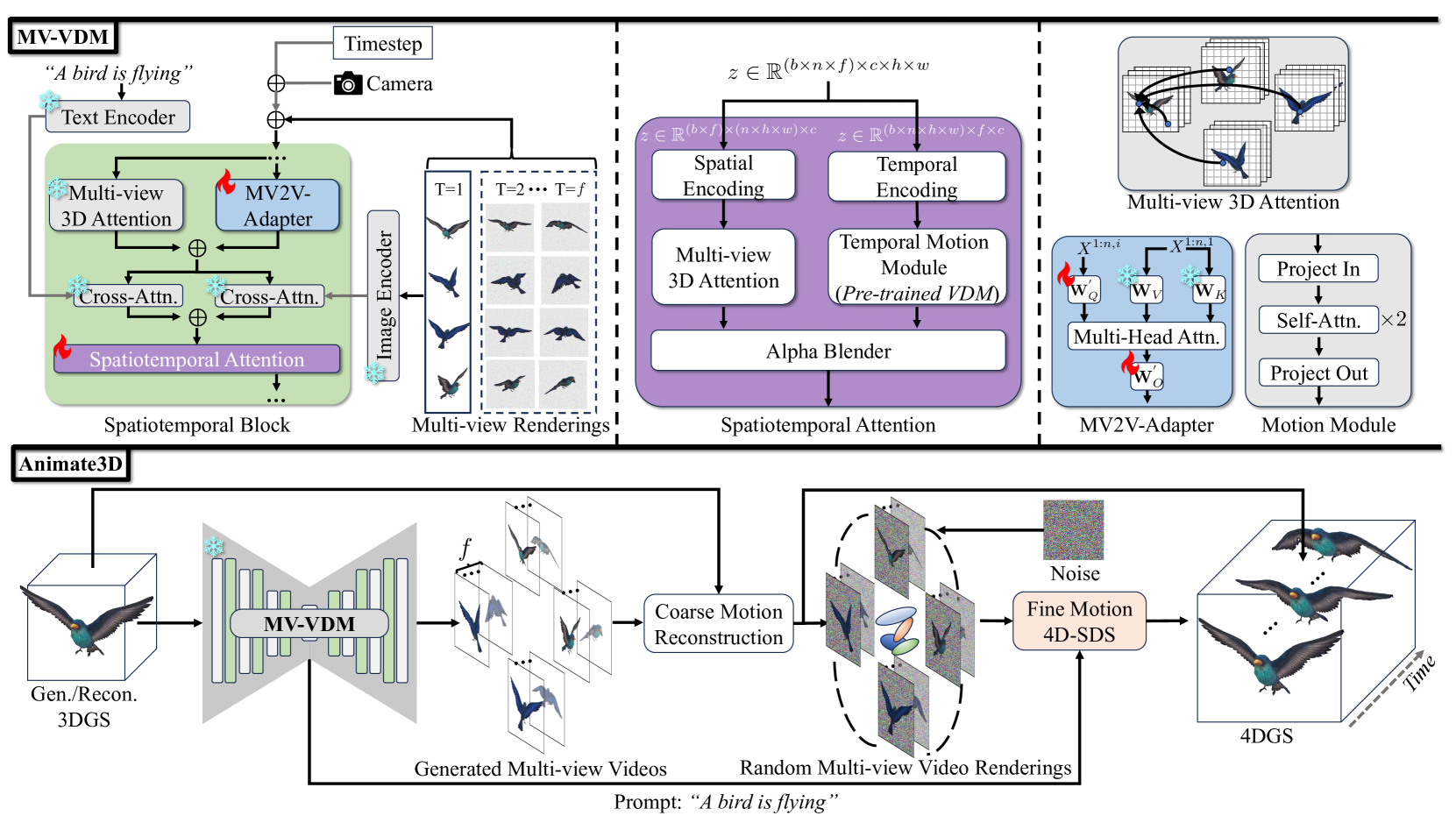
Recent advances in 4D generation mainly focus on generating 4D content by distilling pre-trained text or single-view image-conditioned models. It is inconvenient for them to take advantage of various off-the-shelf 3D assets with multi-view attributes, and their results suffer from spatiotemporal inconsistency owing to the inherent ambiguity in the supervision signals. In this work, we present Animate3D, a novel framework for animating any static 3D model. The core idea is two-fold: 1) We propose a novel multi-view video diffusion model (MV-VDM) conditioned on multi-view renderings of the static 3D object, which is trained on our presented large-scale multi-view video dataset (MV-Video). 2) Based on MV-VDM, we introduce a framework combining reconstruction and 4D Score Distillation Sampling (4D-SDS) to leverage the multi-view video diffusion priors for animating 3D objects. Specifically, for MV-VDM, we design a new spatiotemporal attention module to enhance spatial and temporal consistency by integrating 3D and video diffusion models. Additionally, we leverage the static 3D model's multi-view renderings as conditions to preserve its identity. For animating 3D models, an effective two-stage pipeline is proposed: we first reconstruct motions directly from generated multi-view videos, followed by the introduced 4D-SDS to refine both appearance and motion. Benefiting from accurate motion learning, we could achieve straightforward mesh animation. Qualitative and quantitative experiments demonstrate that Animate3D significantly outperforms previous approaches. Data, code, and models will be open-released.
Read more9/10/2024

0
LatentMan: Generating Consistent Animated Characters using Image Diffusion Models
Abdelrahman Eldesokey, Peter Wonka
We propose a zero-shot approach for generating consistent videos of animated characters based on Text-to-Image (T2I) diffusion models. Existing Text-to-Video (T2V) methods are expensive to train and require large-scale video datasets to produce diverse characters and motions. At the same time, their zero-shot alternatives fail to produce temporally consistent videos with continuous motion. We strive to bridge this gap, and we introduce LatentMan, which leverages existing text-based motion diffusion models to generate diverse continuous motions to guide the T2I model. To boost the temporal consistency, we introduce the Spatial Latent Alignment module that exploits cross-frame dense correspondences that we compute to align the latents of the video frames. Furthermore, we propose Pixel-Wise Guidance to steer the diffusion process in a direction that minimizes visual discrepancies between frames. Our proposed approach outperforms existing zero-shot T2V approaches in generating videos of animated characters in terms of pixel-wise consistency and user preference. Project page https://abdo-eldesokey.github.io/latentman/.
Read more6/4/2024