Animate3D: Animating Any 3D Model with Multi-view Video Diffusion

0
Sign in to get full access
Overview
- This paper presents a novel method called Animate3D for animating any 3D model using multi-view video diffusion.
- The approach leverages recent advancements in diffusion models and multi-view video generation to create high-quality, dynamic 3D animations from a single 3D model and a set of reference videos.
- The system can animate a wide variety of 3D objects, including rigid, articulated, and deformable models, without requiring any additional annotations or prior animation data.
Plain English Explanation
The researchers have developed a new technique called Animate3D that can breathe life into any 3D model by animating it using a set of reference videos. This is done by combining the power of diffusion models, which are a type of machine learning model, and the ability to generate multi-view videos.
Diffusion models are a powerful tool for generating realistic images, videos, and even 3D content. In this case, the researchers used diffusion models to analyze the motion and deformation patterns in the reference videos. They then applied these learned patterns to the 3D model, effectively "animating" it and bringing it to life.
The key advantage of this approach is that it doesn't require any additional information or data beyond the 3D model and the reference videos. This means that even simple 3D objects, like a chair or a vase, can be animated in a very natural and realistic way, without the need for extensive manual work or specialized animation skills.
The researchers tested their Animate3D system on a wide range of 3D models, including rigid, articulated, and deformable objects, and the results look very promising. The animations generated by the system appear smooth and believable, capturing the nuances of the reference videos.
This work is an exciting development in the field of 3D animation, as it has the potential to democratize the creation of dynamic 3D content. By making it easier to animate 3D models, the Animate3D system could empower a wide range of users, from designers and artists to educators and hobbyists, to bring their 3D creations to life in a more accessible and efficient way.
Technical Explanation
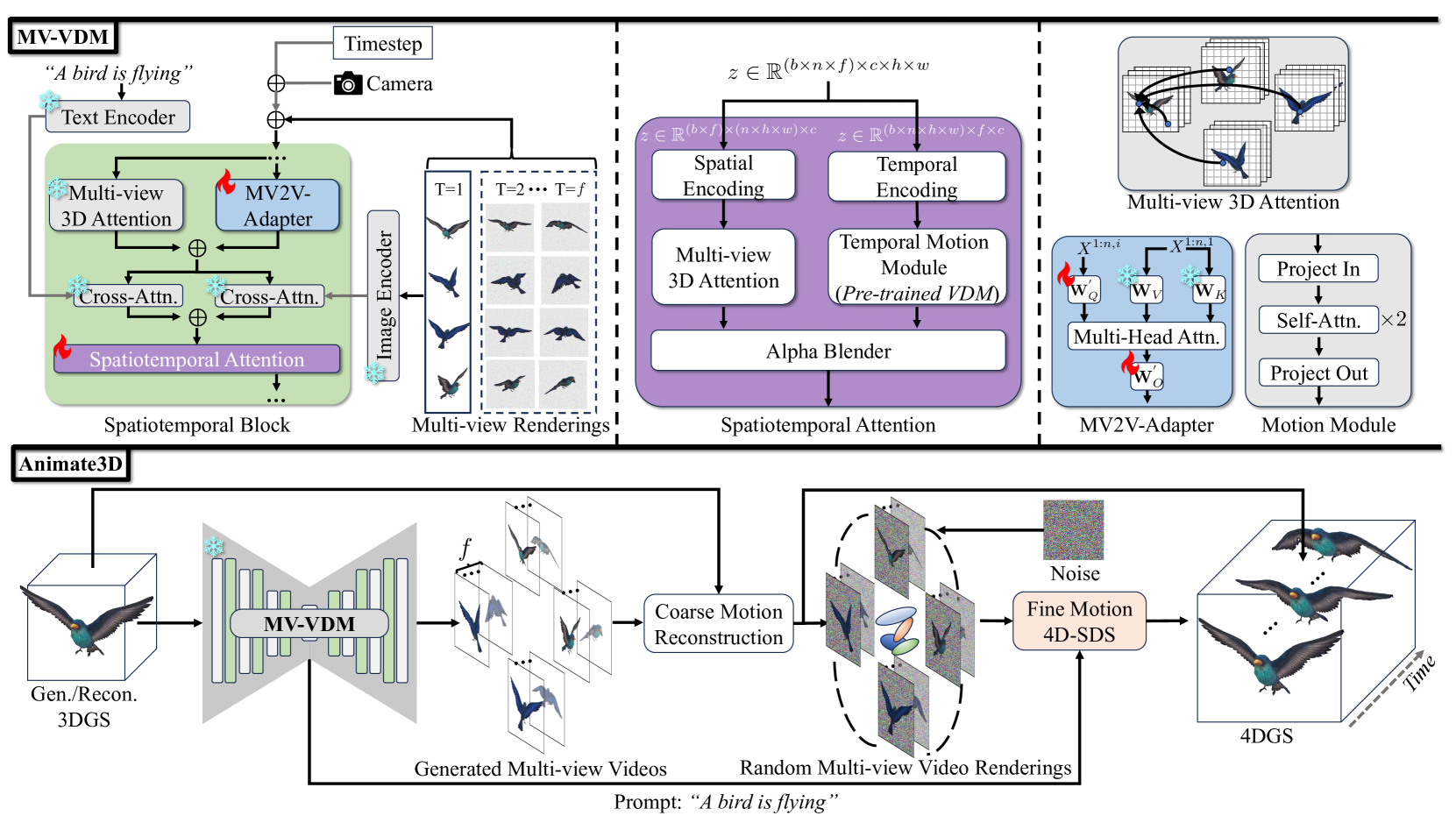
The core of the Animate3D system is a multi-view video diffusion model that learns to generate dynamic 3D content from a single 3D model and a set of reference videos. This model builds upon recent advancements in the field of diffusion models, which have shown impressive results in generating high-quality images, videos, and 3D content.
The researchers' key innovation is the integration of multi-view video generation capabilities into the diffusion model. This allows the system to synthesize video sequences from multiple camera perspectives, which is crucial for creating realistic 3D animations. The model learns to capture the intricate motion and deformation patterns present in the reference videos and applies them to the target 3D model.
To achieve this, the Animate3D system employs a novel architecture that consists of several key components. First, it takes the 3D model and the reference videos as input and encodes them into a shared latent representation. This representation is then used by the diffusion model to generate the animated 3D content.
The researchers also introduce several technical innovations, such as multi-view consistency constraints and a hierarchical training strategy, to ensure that the generated animations are both visually coherent and faithful to the original 3D model. These enhancements help to overcome challenges related to the complexity of 3D animation and the inherent difficulties in modeling multi-view video data.
Through extensive experiments, the researchers demonstrate the versatility and effectiveness of the Animate3D system. They show that it can handle a wide range of 3D models, from rigid to articulated and deformable, and generate high-quality animations that closely match the reference videos. The system also exhibits impressive generalization capabilities, allowing it to animate 3D models that were not included in the training data.
Critical Analysis
The Animate3D system represents an exciting advancement in the field of 3D animation, as it addresses several key limitations of traditional animation workflows. By leveraging the power of diffusion models and multi-view video synthesis, the researchers have developed a novel approach that can generate dynamic 3D content from a single 3D model and a set of reference videos.
One of the notable strengths of the Animate3D system is its versatility. The researchers have demonstrated that the system can handle a wide range of 3D models, including rigid, articulated, and deformable objects, without requiring any prior animation data or annotations. This is a significant improvement over traditional animation techniques, which often rely on extensive manual work or specialized domain knowledge.
However, the paper also acknowledges some limitations and areas for further research. For instance, the system may struggle to capture highly complex or subtle deformation patterns, particularly for highly articulated or organic 3D models. Additionally, the quality of the generated animations may be influenced by the diversity and quality of the reference videos used during training.
Another potential avenue for improvement could be the incorporation of additional constraints or guidance mechanisms to better preserve the original 3D model's structure and proportions during the animation process. This could help to ensure that the generated animations remain faithful to the source material and avoid unintended distortions or artifacts.
Despite these minor limitations, the Animate3D system represents an important step forward in the field of 3D animation. By leveraging the power of diffusion models and multi-view video synthesis, the researchers have opened up new possibilities for the creation of dynamic 3D content, with potential applications in areas such as visual effects, game development, and interactive media.
Conclusion
The Animate3D system presented in this paper is a significant advancement in the field of 3D animation. By combining the capabilities of diffusion models and multi-view video generation, the researchers have developed a novel approach that can breathe life into any 3D model using a set of reference videos.
The key innovation of the Animate3D system is its ability to capture the intricate motion and deformation patterns present in the reference videos and apply them to the target 3D model, without requiring any additional annotations or prior animation data. This versatility and accessibility make the system a powerful tool for a wide range of users, from designers and artists to educators and hobbyists.
While the paper acknowledges some limitations and areas for further research, the overall quality and generalization capabilities of the Animate3D system are impressive. As the field of 3D animation continues to evolve, this work represents an important step towards democratizing the creation of dynamic 3D content and empowering a broader audience to bring their digital creations to life.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Animate3D: Animating Any 3D Model with Multi-view Video Diffusion
Yanqin Jiang, Chaohui Yu, Chenjie Cao, Fan Wang, Weiming Hu, Jin Gao
Recent advances in 4D generation mainly focus on generating 4D content by distilling pre-trained text or single-view image-conditioned models. It is inconvenient for them to take advantage of various off-the-shelf 3D assets with multi-view attributes, and their results suffer from spatiotemporal inconsistency owing to the inherent ambiguity in the supervision signals. In this work, we present Animate3D, a novel framework for animating any static 3D model. The core idea is two-fold: 1) We propose a novel multi-view video diffusion model (MV-VDM) conditioned on multi-view renderings of the static 3D object, which is trained on our presented large-scale multi-view video dataset (MV-Video). 2) Based on MV-VDM, we introduce a framework combining reconstruction and 4D Score Distillation Sampling (4D-SDS) to leverage the multi-view video diffusion priors for animating 3D objects. Specifically, for MV-VDM, we design a new spatiotemporal attention module to enhance spatial and temporal consistency by integrating 3D and video diffusion models. Additionally, we leverage the static 3D model's multi-view renderings as conditions to preserve its identity. For animating 3D models, an effective two-stage pipeline is proposed: we first reconstruct motions directly from generated multi-view videos, followed by the introduced 4D-SDS to refine both appearance and motion. Benefiting from accurate motion learning, we could achieve straightforward mesh animation. Qualitative and quantitative experiments demonstrate that Animate3D significantly outperforms previous approaches. Data, code, and models will be open-released.
Read more9/10/2024
0
Vid3D: Synthesis of Dynamic 3D Scenes using 2D Video Diffusion
Rishab Parthasarathy, Zachary Ankner, Aaron Gokaslan
A recent frontier in computer vision has been the task of 3D video generation, which consists of generating a time-varying 3D representation of a scene. To generate dynamic 3D scenes, current methods explicitly model 3D temporal dynamics by jointly optimizing for consistency across both time and views of the scene. In this paper, we instead investigate whether it is necessary to explicitly enforce multiview consistency over time, as current approaches do, or if it is sufficient for a model to generate 3D representations of each timestep independently. We hence propose a model, Vid3D, that leverages 2D video diffusion to generate 3D videos by first generating a 2D seed of the video's temporal dynamics and then independently generating a 3D representation for each timestep in the seed video. We evaluate Vid3D against two state-of-the-art 3D video generation methods and find that Vid3D is achieves comparable results despite not explicitly modeling 3D temporal dynamics. We further ablate how the quality of Vid3D depends on the number of views generated per frame. While we observe some degradation with fewer views, performance degradation remains minor. Our results thus suggest that 3D temporal knowledge may not be necessary to generate high-quality dynamic 3D scenes, potentially enabling simpler generative algorithms for this task.
Read more8/1/2024

0
SV4D: Dynamic 3D Content Generation with Multi-Frame and Multi-View Consistency
Yiming Xie, Chun-Han Yao, Vikram Voleti, Huaizu Jiang, Varun Jampani
We present Stable Video 4D (SV4D), a latent video diffusion model for multi-frame and multi-view consistent dynamic 3D content generation. Unlike previous methods that rely on separately trained generative models for video generation and novel view synthesis, we design a unified diffusion model to generate novel view videos of dynamic 3D objects. Specifically, given a monocular reference video, SV4D generates novel views for each video frame that are temporally consistent. We then use the generated novel view videos to optimize an implicit 4D representation (dynamic NeRF) efficiently, without the need for cumbersome SDS-based optimization used in most prior works. To train our unified novel view video generation model, we curated a dynamic 3D object dataset from the existing Objaverse dataset. Extensive experimental results on multiple datasets and user studies demonstrate SV4D's state-of-the-art performance on novel-view video synthesis as well as 4D generation compared to prior works.
Read more7/25/2024

0
VFusion3D: Learning Scalable 3D Generative Models from Video Diffusion Models
Junlin Han, Filippos Kokkinos, Philip Torr
This paper presents a novel method for building scalable 3D generative models utilizing pre-trained video diffusion models. The primary obstacle in developing foundation 3D generative models is the limited availability of 3D data. Unlike images, texts, or videos, 3D data are not readily accessible and are difficult to acquire. This results in a significant disparity in scale compared to the vast quantities of other types of data. To address this issue, we propose using a video diffusion model, trained with extensive volumes of text, images, and videos, as a knowledge source for 3D data. By unlocking its multi-view generative capabilities through fine-tuning, we generate a large-scale synthetic multi-view dataset to train a feed-forward 3D generative model. The proposed model, VFusion3D, trained on nearly 3M synthetic multi-view data, can generate a 3D asset from a single image in seconds and achieves superior performance when compared to current SOTA feed-forward 3D generative models, with users preferring our results over 90% of the time.
Read more7/22/2024