MoVEInt: Mixture of Variational Experts for Learning Human-Robot Interactions from Demonstrations

0
📈
Sign in to get full access
Overview
- This paper proposes a new model called MoVEInt (Mixture of Variational Experts for learning Human-Robot Interactions) for learning human-robot interaction behaviors from demonstrations.
- The model is based on a mixture of variational experts, where each expert specializes in learning a particular type of interaction behavior.
- The paper demonstrates the effectiveness of MoVEInt on various human-robot interaction tasks, including object handover, collaborative task completion, and social navigation.
Plain English Explanation
The paper introduces a new machine learning model called MoVEInt that can learn how humans and robots should interact with each other by watching demonstrations of those interactions. The key idea is to have multiple "experts" within the model, where each expert specializes in learning a particular type of interaction behavior, such as how to hand over an object or how to work together on a task.
By having these specialized experts, the model can more effectively learn the nuances of different interaction behaviors, rather than trying to learn everything at once. The paper shows that this approach leads to better performance on a variety of human-robot interaction tasks compared to previous methods.
The significance of this work is that it can help robots become better at interacting with humans in natural and intuitive ways, which is crucial for robots to be widely adopted and accepted in our everyday lives. By learning from demonstrations, the robots can pick up on the subtle social cues and conventions that humans use when interacting with each other, which can make the interactions feel more seamless and comfortable.
Technical Explanation
The MoVEInt: Mixture of Variational Experts for Learning Human-Robot Interactions from Demonstrations paper proposes a new model architecture called MoVEInt that uses a mixture of variational experts to learn human-robot interaction behaviors from demonstrations.
The model is based on the Mixture of Experts approach, where multiple specialized "experts" are trained to handle different aspects of a task. In the case of MoVEInt, each expert is responsible for learning a particular type of interaction behavior, such as object handover, collaborative task completion, or social navigation.
The experts are implemented using a variational autoencoder (VAE) like in this paper, which allows the model to learn a compact, low-dimensional representation of the interaction behaviors from the demonstration data. The mixture component then learns to select the appropriate expert for a given interaction scenario.
The paper evaluates MoVEInt on several human-robot interaction tasks, including object handover, collaborative task completion, and social navigation. The results show that MoVEInt outperforms previous methods such as this one in terms of generating natural and appropriate interaction behaviors, as well as adapting to new situations like in this work.
Critical Analysis
The MoVEInt paper presents a promising approach for learning human-robot interaction behaviors from demonstrations. The use of a mixture of specialized experts is an effective way to capture the diversity of interaction behaviors, and the variational autoencoder architecture allows the model to learn compact and flexible representations.
However, the paper does not extensively discuss the limitations of the approach. For example, it's unclear how the model would scale to learning from a very large and diverse set of demonstration data, or how it would handle novel interaction scenarios that are significantly different from the training data.
Additionally, the paper does not provide much insight into the interpretability of the learned experts and their internal representations. Understanding the reasoning behind the model's behavior is important for building trust and acceptance of these systems in real-world applications.
Further research could explore ways to make the MoVEInt model more robust, scalable, and interpretable, as well as investigate its performance in more complex and realistic human-robot interaction scenarios.
Conclusion
The MoVEInt paper presents a novel approach for learning human-robot interaction behaviors from demonstrations, using a mixture of variational experts to capture the diversity of interaction patterns. The results demonstrate the effectiveness of this method on various tasks, suggesting its potential to enable more natural and intuitive interactions between humans and robots.
As robots become more ubiquitous in our daily lives, developing such interaction learning capabilities will be crucial for their widespread adoption and acceptance. The MoVEInt model represents an important step in this direction, and the insights from this paper can inform future research on improving the flexibility, robustness, and interpretability of human-robot interaction systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
0
MoVEInt: Mixture of Variational Experts for Learning Human-Robot Interactions from Demonstrations
Vignesh Prasad, Alap Kshirsagar, Dorothea Koert, Ruth Stock-Homburg, Jan Peters, Georgia Chalvatzaki
Shared dynamics models are important for capturing the complexity and variability inherent in Human-Robot Interaction (HRI). Therefore, learning such shared dynamics models can enhance coordination and adaptability to enable successful reactive interactions with a human partner. In this work, we propose a novel approach for learning a shared latent space representation for HRIs from demonstrations in a Mixture of Experts fashion for reactively generating robot actions from human observations. We train a Variational Autoencoder (VAE) to learn robot motions regularized using an informative latent space prior that captures the multimodality of the human observations via a Mixture Density Network (MDN). We show how our formulation derives from a Gaussian Mixture Regression formulation that is typically used approaches for learning HRI from demonstrations such as using an HMM/GMM for learning a joint distribution over the actions of the human and the robot. We further incorporate an additional regularization to prevent mode collapse, a common phenomenon when using latent space mixture models with VAEs. We find that our approach of using an informative MDN prior from human observations for a VAE generates more accurate robot motions compared to previous HMM-based or recurrent approaches of learning shared latent representations, which we validate on various HRI datasets involving interactions such as handshakes, fistbumps, waving, and handovers. Further experiments in a real-world human-to-robot handover scenario show the efficacy of our approach for generating successful interactions with four different human interaction partners.
Read more7/11/2024
🤷
0
ImitationNet: Unsupervised Human-to-Robot Motion Retargeting via Shared Latent Space
Yashuai Yan, Esteve Valls Mascaro, Dongheui Lee
This paper introduces a novel deep-learning approach for human-to-robot motion retargeting, enabling robots to mimic human poses accurately. Contrary to prior deep-learning-based works, our method does not require paired human-to-robot data, which facilitates its translation to new robots. First, we construct a shared latent space between humans and robots via adaptive contrastive learning that takes advantage of a proposed cross-domain similarity metric between the human and robot poses. Additionally, we propose a consistency term to build a common latent space that captures the similarity of the poses with precision while allowing direct robot motion control from the latent space. For instance, we can generate in-between motion through simple linear interpolation between two projected human poses. We conduct a comprehensive evaluation of robot control from diverse modalities (i.e., texts, RGB videos, and key poses), which facilitates robot control for non-expert users. Our model outperforms existing works regarding human-to-robot retargeting in terms of efficiency and precision. Finally, we implemented our method in a real robot with self-collision avoidance through a whole-body controller to showcase the effectiveness of our approach. More information on our website https://evm7.github.io/UnsH2R/
Read more4/9/2024
0
A Mixture of Experts Approach to 3D Human Motion Prediction
Edmund Shieh, Joshua Lee Franco, Kang Min Bae, Tej Lalvani
This project addresses the challenge of human motion prediction, a critical area for applications such as au- tonomous vehicle movement detection. Previous works have emphasized the need for low inference times to provide real time performance for applications like these. Our primary objective is to critically evaluate existing model ar- chitectures, identifying their advantages and opportunities for improvement by replicating the state-of-the-art (SOTA) Spatio-Temporal Transformer model as best as possible given computational con- straints. These models have surpassed the limitations of RNN-based models and have demonstrated the ability to generate plausible motion sequences over both short and long term horizons through the use of spatio-temporal rep- resentations. We also propose a novel architecture to ad- dress challenges of real time inference speed by incorpo- rating a Mixture of Experts (MoE) block within the Spatial- Temporal (ST) attention layer. The particular variation that is used is Soft MoE, a fully-differentiable sparse Transformer that has shown promising ability to enable larger model capacity at lower inference cost. We make out code publicly available at https://github.com/edshieh/motionprediction
Read more5/13/2024
0
Bridging Language, Vision and Action: Multimodal VAEs in Robotic Manipulation Tasks
Gabriela Sejnova, Michal Vavrecka, Karla Stepanova
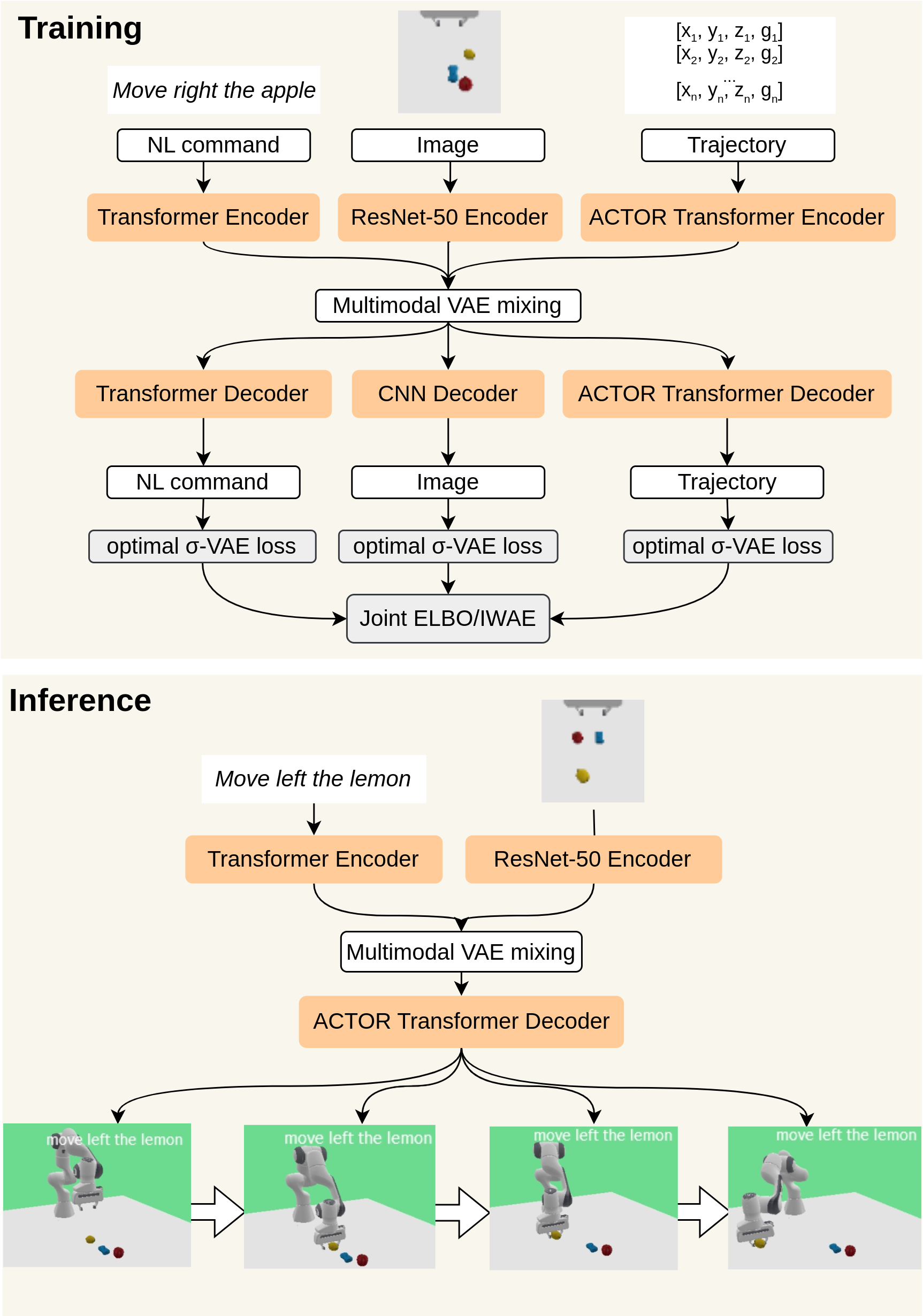
In this work, we focus on unsupervised vision-language-action mapping in the area of robotic manipulation. Recently, multiple approaches employing pre-trained large language and vision models have been proposed for this task. However, they are computationally demanding and require careful fine-tuning of the produced outputs. A more lightweight alternative would be the implementation of multimodal Variational Autoencoders (VAEs) which can extract the latent features of the data and integrate them into a joint representation, as has been demonstrated mostly on image-image or image-text data for the state-of-the-art models. Here we explore whether and how can multimodal VAEs be employed in unsupervised robotic manipulation tasks in a simulated environment. Based on the obtained results, we propose a model-invariant training alternative that improves the models' performance in a simulator by up to 55%. Moreover, we systematically evaluate the challenges raised by the individual tasks such as object or robot position variability, number of distractors or the task length. Our work thus also sheds light on the potential benefits and limitations of using the current multimodal VAEs for unsupervised learning of robotic motion trajectories based on vision and language.
Read more4/3/2024