Bridging Language, Vision and Action: Multimodal VAEs in Robotic Manipulation Tasks
2404.01932
0
0
Abstract
In this work, we focus on unsupervised vision-language-action mapping in the area of robotic manipulation. Recently, multiple approaches employing pre-trained large language and vision models have been proposed for this task. However, they are computationally demanding and require careful fine-tuning of the produced outputs. A more lightweight alternative would be the implementation of multimodal Variational Autoencoders (VAEs) which can extract the latent features of the data and integrate them into a joint representation, as has been demonstrated mostly on image-image or image-text data for the state-of-the-art models. Here we explore whether and how can multimodal VAEs be employed in unsupervised robotic manipulation tasks in a simulated environment. Based on the obtained results, we propose a model-invariant training alternative that improves the models' performance in a simulator by up to 55%. Moreover, we systematically evaluate the challenges raised by the individual tasks such as object or robot position variability, number of distractors or the task length. Our work thus also sheds light on the potential benefits and limitations of using the current multimodal VAEs for unsupervised learning of robotic motion trajectories based on vision and language.
Create account to get full access
Overview
- The paper explores using multimodal variational autoencoders (VAEs) to bridge language, vision, and action in robotic manipulation tasks.
- It aims to learn a shared latent representation that can encode linguistic instructions, visual observations, and robotic actions.
- The model is trained on a dataset of language descriptions, visual observations, and action sequences for various manipulation tasks.
- The learned latent representation is then used to generate action sequences from language inputs and visual observations.
Plain English Explanation
The researchers are working on getting robots to understand and follow instructions given in natural language. They want the robots to be able to see the world around them, interpret language commands, and then perform the right actions to complete a task.
To do this, the researchers use a special type of neural network called a "variational autoencoder" (VAE). This kind of network can learn a compact representation, or "code," that captures the key features of different types of data, like language and visual observations.
The key innovation in this paper is using a multimodal VAE that can learn a shared code for language, vision, and actions. This shared code allows the robot to translate between the different modalities - for example, using language instructions and visual observations to generate the appropriate actions to perform a task.
The researchers train their model on a dataset that includes language descriptions of manipulation tasks, images of the task setup, and the sequences of actions the robot should perform. The model learns to map between these different kinds of data, building a unified representation that can bridge language, vision, and action.
Once the model is trained, it can be used to, say, generate the right sequence of robotic movements from just a natural language description of a task and the visual scene. This could allow robots to follow much richer, more flexible language commands than just simple pre-programmed instructions.
Technical Explanation
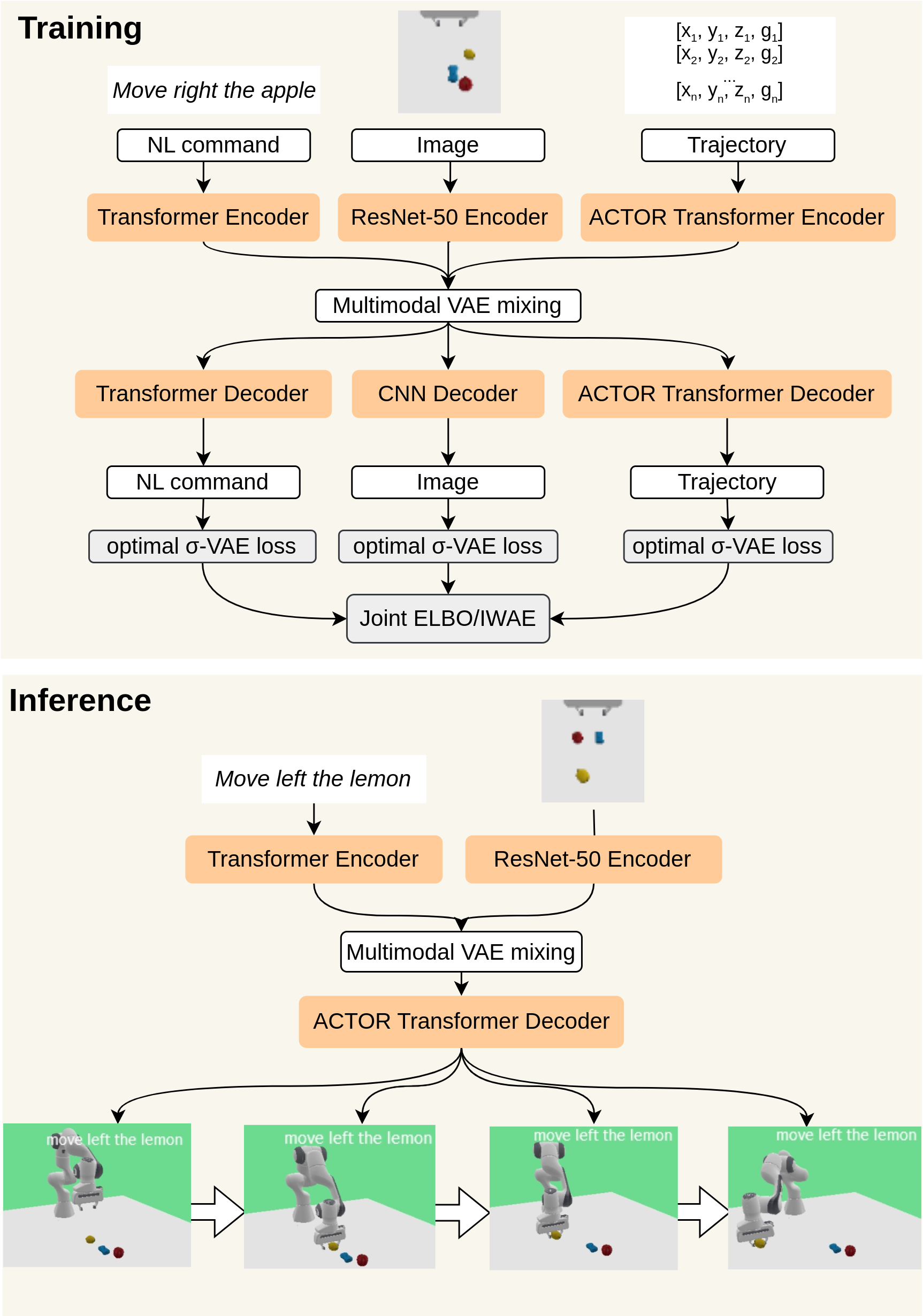
The paper proposes a multimodal variational autoencoder (MM-VAE) architecture to learn a shared latent representation that encodes linguistic instructions, visual observations, and robotic action sequences. The model consists of separate encoder networks for language, vision, and actions, which all map their respective inputs into a common latent space.
A variational autoencoder learns this latent representation by training an encoder network to map inputs into a compressed latent code, and a decoder network to reconstruct the original inputs from the latent code. The authors regularize this process to encourage the latent space to be smooth and continuous, enabling effective cross-modal mappings.
The MM-VAE is trained end-to-end on a dataset of language descriptions, visual observations, and robotic action sequences for various manipulation tasks. During training, the model learns to reconstruct each modality from the shared latent representation. At test time, the model can then be used to generate action sequences from language instructions and visual observations.
The authors evaluate their approach on a simulated robotic manipulation task and show that the MM-VAE outperforms baseline models that do not learn a shared representation. They also demonstrate zero-shot generalization, where the model can successfully execute new language instructions on novel visual scenes.
Critical Analysis
The paper presents a compelling approach to bridging language, vision, and action in robotic manipulation tasks. The multimodal VAE architecture is well-designed and the experimental results demonstrate the effectiveness of the approach.
One potential limitation is the reliance on simulated robotic environments for evaluation. While this allows for controlled experiments, it remains to be seen how well the approach would generalize to real-world robotic systems with all their inherent complexities and uncertainties.
Additionally, the paper does not explore the interpretability of the learned latent representation. It would be interesting to better understand what the model has learned about the relationships between language, vision, and actions.
Further research could also investigate the model's ability to handle more open-ended language instructions, rather than the relatively constrained task descriptions used in the current experiments. Expanding the scope of the language understanding capabilities could unlock even more flexibility and generalization in robotic manipulation.
Overall, this paper represents an important step towards developing robotic systems that can fluidly interact with humans using natural language while maintaining strong perceptual and motor skills. The multimodal VAE approach is a promising direction for continued research in this area.
Conclusion
This paper presents a multimodal variational autoencoder (MM-VAE) model that learns a shared latent representation bridging language, vision, and action for robotic manipulation tasks. By training the model on a dataset of language descriptions, visual observations, and action sequences, it learns to generate appropriate action sequences from language instructions and visual inputs.
The key innovation is the use of a VAE architecture to learn a smooth, continuous latent space that can effectively capture the relationships between the different modalities. This allows the model to perform zero-shot generalization, executing new language instructions on novel visual scenes.
While the experiments are limited to simulated environments, the paper demonstrates the potential of this approach to enable more flexible, natural language-guided robotic systems. Further research into the interpretability of the learned representations and the ability to handle more open-ended language could unlock even greater capabilities in this domain.
Overall, this work represents an important step towards bridging the gap between human communication, perception, and robotic action, with significant implications for the development of more intuitive and capable robotic assistants.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Language Model-Based Paired Variational Autoencoders for Robotic Language Learning
Ozan Ozdemir, Matthias Kerzel, Cornelius Weber, Jae Hee Lee, Stefan Wermter
0
0
Human infants learn language while interacting with their environment in which their caregivers may describe the objects and actions they perform. Similar to human infants, artificial agents can learn language while interacting with their environment. In this work, first, we present a neural model that bidirectionally binds robot actions and their language descriptions in a simple object manipulation scenario. Building on our previous Paired Variational Autoencoders (PVAE) model, we demonstrate the superiority of the variational autoencoder over standard autoencoders by experimenting with cubes of different colours, and by enabling the production of alternative vocabularies. Additional experiments show that the model's channel-separated visual feature extraction module can cope with objects of different shapes. Next, we introduce PVAE-BERT, which equips the model with a pretrained large-scale language model, i.e., Bidirectional Encoder Representations from Transformers (BERT), enabling the model to go beyond comprehending only the predefined descriptions that the network has been trained on; the recognition of action descriptions generalises to unconstrained natural language as the model becomes capable of understanding unlimited variations of the same descriptions. Our experiments suggest that using a pretrained language model as the language encoder allows our approach to scale up for real-world scenarios with instructions from human users.
5/7/2024
🤖
A Survey on Vision-Language-Action Models for Embodied AI
Yueen Ma, Zixing Song, Yuzheng Zhuang, Jianye Hao, Irwin King
0
0
Deep learning has demonstrated remarkable success across many domains, including computer vision, natural language processing, and reinforcement learning. Representative artificial neural networks in these fields span convolutional neural networks, Transformers, and deep Q-networks. Built upon unimodal neural networks, numerous multi-modal models have been introduced to address a range of tasks such as visual question answering, image captioning, and speech recognition. The rise of instruction-following robotic policies in embodied AI has spurred the development of a novel category of multi-modal models known as vision-language-action models (VLAs). Their multi-modality capability has become a foundational element in robot learning. Various methods have been proposed to enhance traits such as versatility, dexterity, and generalizability. Some models focus on refining specific components through pretraining. Others aim to develop control policies adept at predicting low-level actions. Certain VLAs serve as high-level task planners capable of decomposing long-horizon tasks into executable subtasks. Over the past few years, a myriad of VLAs have emerged, reflecting the rapid advancement of embodied AI. Therefore, it is imperative to capture the evolving landscape through a comprehensive survey.
5/24/2024

Unity by Diversity: Improved Representation Learning in Multimodal VAEs
Thomas M. Sutter, Yang Meng, Andrea Agostini, Daphn'e Chopard, Norbert Fortin, Julia E. Vogt, Bahbak Shahbaba, Stephan Mandt
0
0
Variational Autoencoders for multimodal data hold promise for many tasks in data analysis, such as representation learning, conditional generation, and imputation. Current architectures either share the encoder output, decoder input, or both across modalities to learn a shared representation. Such architectures impose hard constraints on the model. In this work, we show that a better latent representation can be obtained by replacing these hard constraints with a soft constraint. We propose a new mixture-of-experts prior, softly guiding each modality's latent representation towards a shared aggregate posterior. This approach results in a superior latent representation and allows each encoding to preserve information better from its uncompressed original features. In extensive experiments on multiple benchmark datasets and two challenging real-world datasets, we show improved learned latent representations and imputation of missing data modalities compared to existing methods.
6/3/2024
QUAR-VLA: Vision-Language-Action Model for Quadruped Robots
Pengxiang Ding, Han Zhao, Wenjie Zhang, Wenxuan Song, Ningxi Yang, Donglin Wang
0
0
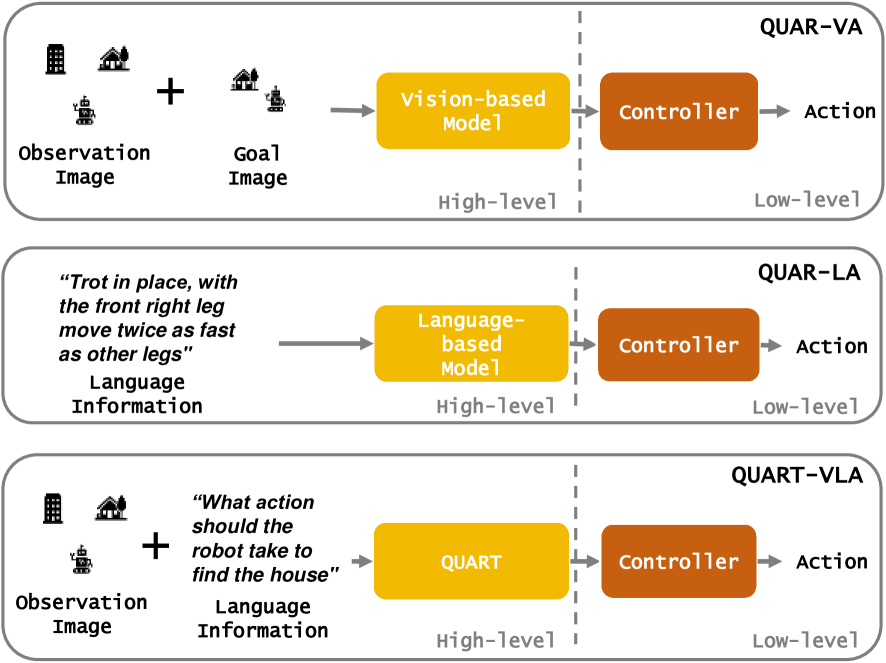
The important manifestation of robot intelligence is the ability to naturally interact and autonomously make decisions. Traditional approaches to robot control often compartmentalize perception, planning, and decision-making, simplifying system design but limiting the synergy between different information streams. This compartmentalization poses challenges in achieving seamless autonomous reasoning, decision-making, and action execution. To address these limitations, a novel paradigm, named Vision-Language-Action tasks for QUAdruped Robots (QUAR-VLA), has been introduced in this paper. This approach tightly integrates visual information and instructions to generate executable actions, effectively merging perception, planning, and decision-making. The central idea is to elevate the overall intelligence of the robot. Within this framework, a notable challenge lies in aligning fine-grained instructions with visual perception information. This emphasizes the complexity involved in ensuring that the robot accurately interprets and acts upon detailed instructions in harmony with its visual observations. Consequently, we propose QUAdruped Robotic Transformer (QUART), a family of VLA models to integrate visual information and instructions from diverse modalities as input and generates executable actions for real-world robots and present QUAdruped Robot Dataset (QUARD), a large-scale multi-task dataset including navigation, complex terrain locomotion, and whole-body manipulation tasks for training QUART models. Our extensive evaluation (4000 evaluation trials) shows that our approach leads to performant robotic policies and enables QUART to obtain a range of emergent capabilities.
6/18/2024