MQuAKE: Assessing Knowledge Editing in Language Models via Multi-Hop Questions

0
💬
Sign in to get full access
Overview
- Large language models (LLMs) quickly become outdated as new information emerges.
- Retraining these models from scratch is often not feasible.
- Techniques for injecting new facts by updating model weights have recently emerged.
- Current evaluation methods focus only on the recall of edited facts.
- Changing one fact should lead to rippling changes in the model's related beliefs.
Plain English Explanation
<internal-link>Large language models</internal-link> are powerful AI systems that can understand and generate human-like text. However, the information stored in these models can become outdated quickly as the world changes. Retraining these models from scratch is often not practical, so researchers have developed techniques to update the models with new information by adjusting the internal weights.
The problem is that current methods for evaluating these knowledge-editing techniques only look at whether the models can accurately recall the specific facts that were changed. But in the real world, changing one fact should have a ripple effect, causing changes to the model's related beliefs. For example, if you change the identity of the UK Prime Minister, the model should also give a different answer to the question "Who is married to the British Prime Minister?"
To address this, the researchers have created a new benchmark called <internal-link>MQuAKE (Multi-hop Question Answering for Knowledge Editing)</internal-link>. This benchmark tests whether knowledge-edited models can correctly answer multi-step questions where the answer should change as a consequence of the edited facts.
The researchers found that current knowledge-editing approaches can accurately recall edited facts but fail badly on the MQuAKE multi-hop questions. To address this, they propose a new technique called <internal-link>MeLLo</internal-link>, which stores all edited facts externally and uses an iterative process to generate answers that are consistent with the updated information. MeLLo is able to scale well to large language models like GPT-3.5-turbo and outperforms previous knowledge-editing methods.
Technical Explanation
The researchers developed <internal-link>MQuAKE</internal-link>, a benchmark that assesses whether knowledge-edited language models can correctly answer multi-hop questions where the answer should change as a consequence of the edited facts. MQuAKE comprises a set of multi-step questions that require reasoning about relationships between concepts.
To evaluate existing knowledge-editing techniques, the researchers applied several approaches, including <internal-link>retrieval-enhanced</internal-link> and <internal-link>memory-based</internal-link> methods, to update a base language model with new facts. They found that while these methods could accurately recall the edited facts, they performed poorly on the multi-hop questions in MQuAKE, often giving answers that were inconsistent with the updated knowledge.
To address this shortcoming, the researchers proposed <internal-link>MeLLo</internal-link>, a simple memory-based approach that stores all edited facts externally and uses an iterative process to generate answers that are consistent with the updated information. MeLLo was able to scale well to large language models like GPT-3.5-turbo and significantly outperformed previous knowledge-editing techniques on the MQuAKE benchmark.
Critical Analysis
The MQuAKE benchmark is a valuable contribution, as it highlights the limitations of current knowledge-editing approaches. The researchers rightly point out that simply validating the recall of edited facts is an incomplete metric, as changing one fact should have downstream effects on a model's related beliefs.
However, the MQuAKE benchmark itself may have some limitations. The researchers do not provide detailed information about the specific multi-hop questions used, making it difficult to assess the breadth and complexity of the reasoning required. Additionally, the benchmark is focused on English-language models, and it would be interesting to see how knowledge-editing techniques perform on multilingual benchmarks.
The proposed <internal-link>MeLLo</internal-link> approach is a promising solution, but it remains to be seen how it would scale to larger and more complex language models. The researchers also do not address potential issues with the external storage of edited facts, such as the security and privacy implications of maintaining a separate knowledge base.
Conclusion
This research highlights the importance of moving beyond simple fact-based evaluations of knowledge-editing techniques for large language models. The <internal-link>MQuAKE</internal-link> benchmark provides a more comprehensive way to assess whether updated models can correctly reason about the downstream consequences of edited facts.
The researchers' proposed <internal-link>MeLLo</internal-link> approach shows promise, but further work is needed to address the scalability and practical deployment challenges of knowledge-editing systems. As large language models become increasingly ubiquitous, developing robust and reliable methods for maintaining their knowledge will be a critical area of research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
MQuAKE: Assessing Knowledge Editing in Language Models via Multi-Hop Questions
Zexuan Zhong, Zhengxuan Wu, Christopher D. Manning, Christopher Potts, Danqi Chen
The information stored in large language models (LLMs) falls out of date quickly, and retraining from scratch is often not an option. This has recently given rise to a range of techniques for injecting new facts through updating model weights. Current evaluation paradigms are extremely limited, mainly validating the recall of edited facts, but changing one fact should cause rippling changes to the model's related beliefs. If we edit the UK Prime Minister to now be Rishi Sunak, then we should get a different answer to Who is married to the British Prime Minister? In this work, we present a benchmark, MQuAKE (Multi-hop Question Answering for Knowledge Editing), comprising multi-hop questions that assess whether edited models correctly answer questions where the answer should change as an entailed consequence of edited facts. While we find that current knowledge-editing approaches can recall edited facts accurately, they fail catastrophically on the constructed multi-hop questions. We thus propose a simple memory-based approach, MeLLo, which stores all edited facts externally while prompting the language model iteratively to generate answers that are consistent with the edited facts. While MQuAKE remains challenging, we show that MeLLo scales well with LLMs (e.g., OpenAI GPT-3.5-turbo) and outperforms previous model editors by a large margin.
Read more9/10/2024
💬
0
New!MQA-KEAL: Multi-hop Question Answering under Knowledge Editing for Arabic Language
Muhammad Asif Ali, Nawal Daftardar, Mutayyaba Waheed, Jianbin Qin, Di Wang
Large Language Models (LLMs) have demonstrated significant capabilities across numerous application domains. A key challenge is to keep these models updated with latest available information, which limits the true potential of these models for the end-applications. Although, there have been numerous attempts for LLMs Knowledge Editing (KE), i.e., to edit the LLMs prior knowledge and in turn test it via Multi-hop Question Answering (MQA), yet so far these studies are primarily focused on English language. To bridge this gap, in this paper we propose: Multi-hop Questioning Answering under Knowledge Editing for Arabic Language (MQA-KEAL). MQA-KEAL stores knowledge edits as structured knowledge units in the external memory. In order to solve multi-hop question, it first uses task-decomposition to decompose the question into smaller sub-problems. Later for each sub-problem, it iteratively queries the external memory and/or target LLM in order to generate the final response. In addition, we also contribute MQUAKE-AR (Arabic translation of English benchmark MQUAKE), as well as a new benchmark MQA-AEVAL for rigorous performance evaluation of MQA under KE for Arabic language. Experimentation evaluation reveals MQA-KEAL outperforms the baseline models by a significant margin.
Read more9/20/2024

0
LLM-Based Multi-Hop Question Answering with Knowledge Graph Integration in Evolving Environments
Ruirui Chen, Weifeng Jiang, Chengwei Qin, Ishaan Singh Rawal, Cheston Tan, Dongkyu Choi, Bo Xiong, Bo Ai
The rapid obsolescence of information in Large Language Models (LLMs) has driven the development of various techniques to incorporate new facts. However, existing methods for knowledge editing still face difficulties with multi-hop questions that require accurate fact identification and sequential logical reasoning, particularly among numerous fact updates. To tackle these challenges, this paper introduces Graph Memory-based Editing for Large Language Models (GMeLLo), a straitforward and effective method that merges the explicit knowledge representation of Knowledge Graphs (KGs) with the linguistic flexibility of LLMs. Beyond merely leveraging LLMs for question answering, GMeLLo employs these models to convert free-form language into structured queries and fact triples, facilitating seamless interaction with KGs for rapid updates and precise multi-hop reasoning. Our results show that GMeLLo significantly surpasses current state-of-the-art knowledge editing methods in the multi-hop question answering benchmark, MQuAKE, especially in scenarios with extensive knowledge edits.
Read more8/29/2024
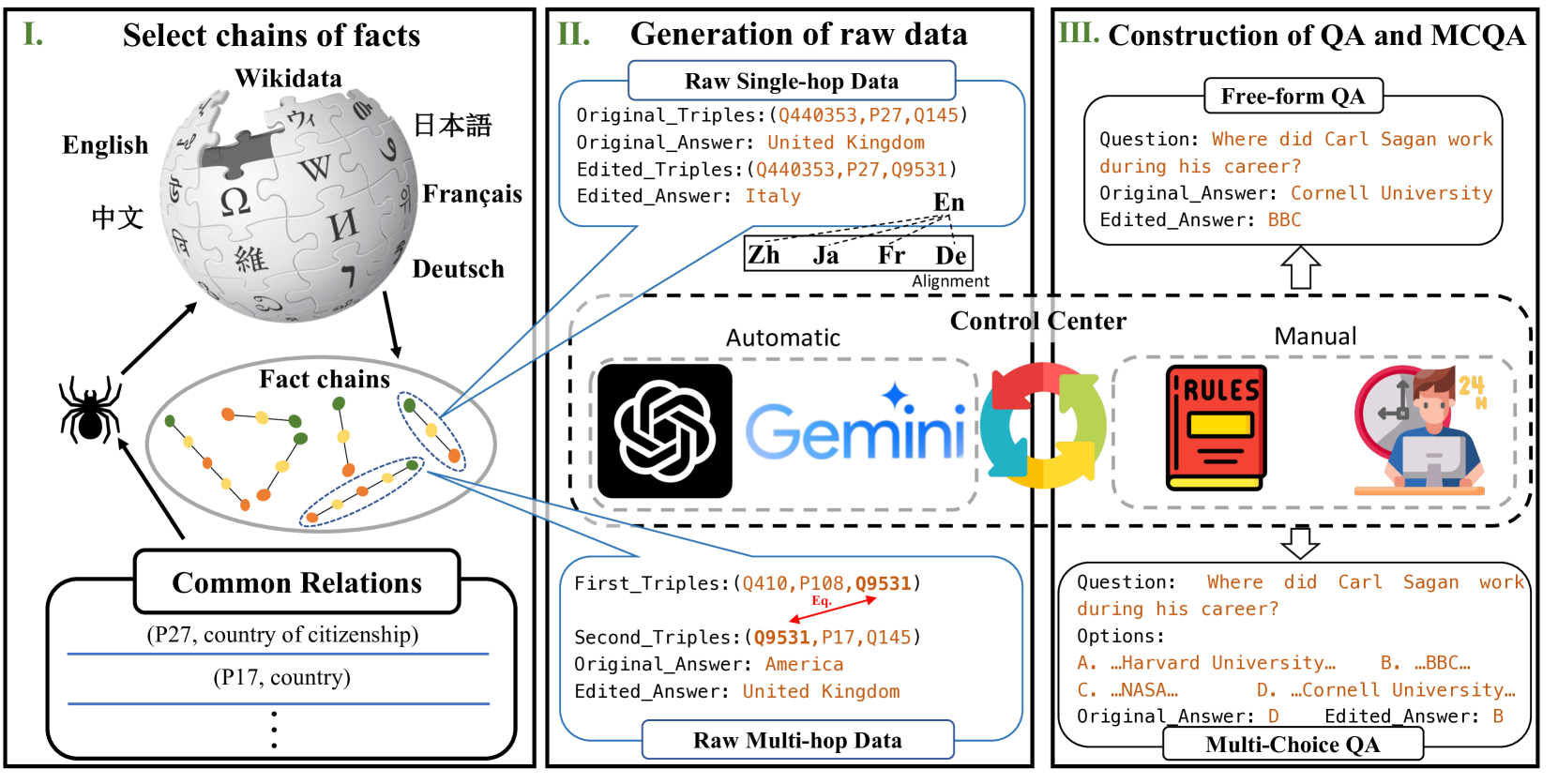
0
MLaKE: Multilingual Knowledge Editing Benchmark for Large Language Models
Zihao Wei, Jingcheng Deng, Liang Pang, Hanxing Ding, Huawei Shen, Xueqi Cheng
The extensive utilization of large language models (LLMs) underscores the crucial necessity for precise and contemporary knowledge embedded within their intrinsic parameters. Existing research on knowledge editing primarily concentrates on monolingual scenarios, neglecting the complexities presented by multilingual contexts and multi-hop reasoning. To address these challenges, our study introduces MLaKE (Multilingual Language Knowledge Editing), a novel benchmark comprising 4072 multi-hop and 5360 single-hop questions designed to evaluate the adaptability of knowledge editing methods across five languages: English, Chinese, Japanese, French, and German. MLaKE aggregates fact chains from Wikipedia across languages and utilizes LLMs to generate questions in both free-form and multiple-choice. We evaluate the multilingual knowledge editing generalization capabilities of existing methods on MLaKE. Existing knowledge editing methods demonstrate higher success rates in English samples compared to other languages. However, their generalization capabilities are limited in multi-language experiments. Notably, existing knowledge editing methods often show relatively high generalization for languages within the same language family compared to languages from different language families. These results underscore the imperative need for advancements in multilingual knowledge editing and we hope MLaKE can serve as a valuable resource for benchmarking and solution development.
Read more4/9/2024