MLaKE: Multilingual Knowledge Editing Benchmark for Large Language Models
2404.04990
0
0
Abstract
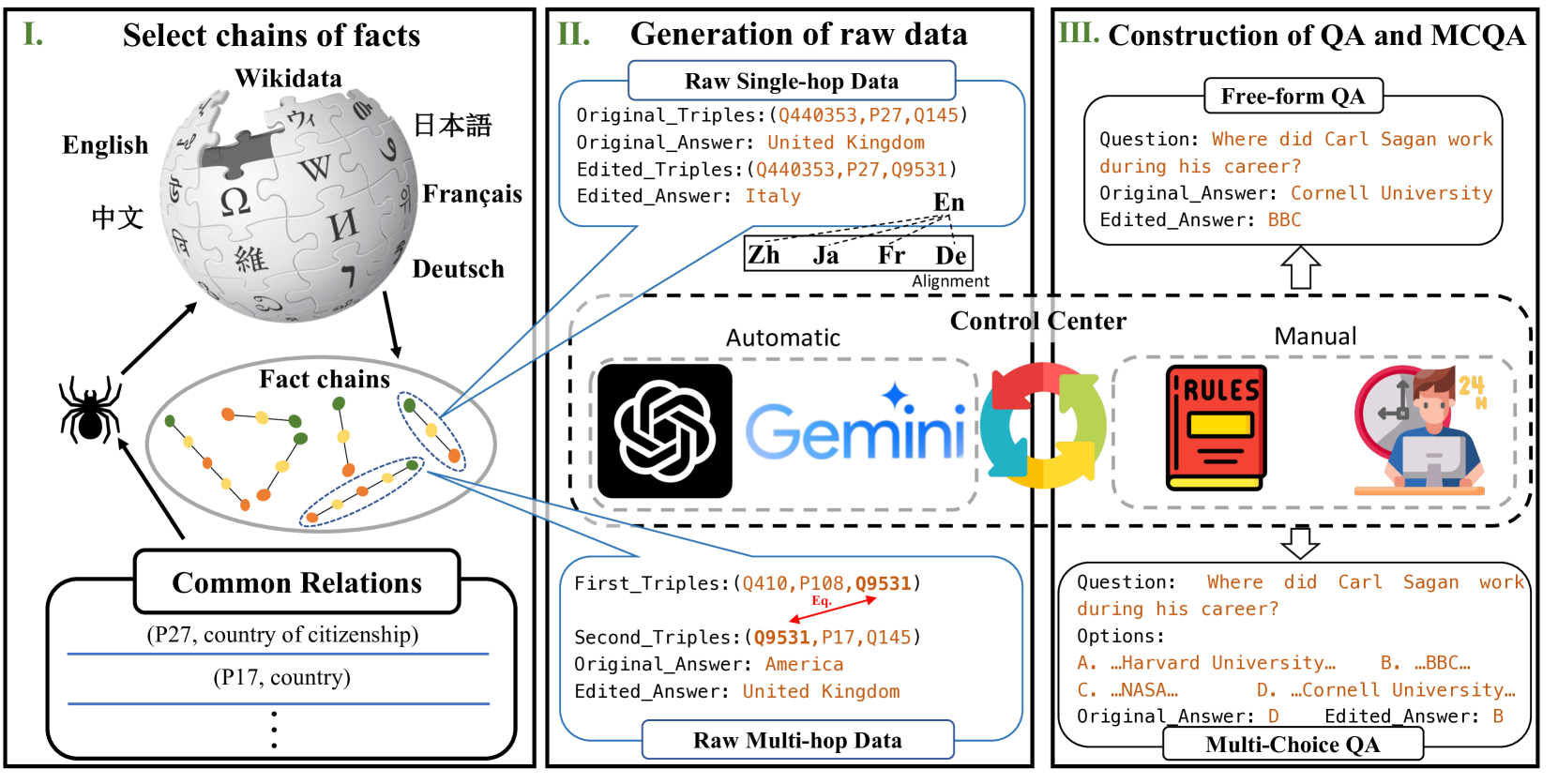
The extensive utilization of large language models (LLMs) underscores the crucial necessity for precise and contemporary knowledge embedded within their intrinsic parameters. Existing research on knowledge editing primarily concentrates on monolingual scenarios, neglecting the complexities presented by multilingual contexts and multi-hop reasoning. To address these challenges, our study introduces MLaKE (Multilingual Language Knowledge Editing), a novel benchmark comprising 4072 multi-hop and 5360 single-hop questions designed to evaluate the adaptability of knowledge editing methods across five languages: English, Chinese, Japanese, French, and German. MLaKE aggregates fact chains from Wikipedia across languages and utilizes LLMs to generate questions in both free-form and multiple-choice. We evaluate the multilingual knowledge editing generalization capabilities of existing methods on MLaKE. Existing knowledge editing methods demonstrate higher success rates in English samples compared to other languages. However, their generalization capabilities are limited in multi-language experiments. Notably, existing knowledge editing methods often show relatively high generalization for languages within the same language family compared to languages from different language families. These results underscore the imperative need for advancements in multilingual knowledge editing and we hope MLaKE can serve as a valuable resource for benchmarking and solution development.
Get summaries of the top AI research delivered straight to your inbox:
Overview
• This paper introduces MLaKE, a new Multilingual Knowledge Editing Benchmark for evaluating the capabilities of large language models (LLMs) in knowledge editing tasks across multiple languages.
• The benchmark covers a diverse range of knowledge editing tasks, including fact correction, knowledge addition, and knowledge refinement, in 8 different languages.
• The authors provide baselines using several state-of-the-art LLMs and highlight the challenges posed by MLaKE, demonstrating room for improvement in the multilingual knowledge editing capabilities of current LLMs.
Plain English Explanation
The paper presents a new benchmark called MLaKE (Multilingual Knowledge Editing Benchmark) that is designed to test the abilities of large language models (LLMs) in editing and manipulating knowledge across multiple languages. LLMs are powerful AI systems that can understand and generate human-like text, and this benchmark aims to assess how well they can perform tasks like correcting factual errors, adding new information, and refining existing knowledge in different languages.
The benchmark covers a diverse set of knowledge editing tasks in 8 languages, including English, Chinese, Japanese, and several European languages. This is important because it allows researchers to evaluate the multilingual capabilities of LLMs, rather than just their performance in a single language.
The authors provide baseline results using several state-of-the-art LLMs, which show that current models still struggle with some of the challenges posed by the MLaKE benchmark. This suggests that there is room for improvement in the knowledge editing abilities of LLMs, particularly when it comes to working with information across multiple languages.
Technical Explanation
The paper introduces the MLaKE (Multilingual Knowledge Editing Benchmark) dataset, which is designed to evaluate the knowledge editing capabilities of large language models (LLMs) in a multilingual setting. The benchmark covers a diverse range of knowledge editing tasks, including fact correction, knowledge addition, and knowledge refinement, across 8 different languages: English, Chinese, Japanese, French, German, Italian, Spanish, and Russian.
The authors construct the MLaKE dataset by gathering real-world knowledge from sources like Wikipedia and manually curating the knowledge editing tasks. They provide baseline results using several state-of-the-art LLMs, including GPT-3, T5, and [BLENDERBOT], highlighting the challenges posed by the MLaKE benchmark and the need for further advancements in the multilingual knowledge editing capabilities of current LLMs.
Critical Analysis
The MLaKE benchmark represents an important step forward in evaluating the multilingual capabilities of large language models. By covering a diverse range of knowledge editing tasks across multiple languages, the benchmark provides a more comprehensive assessment of LLM performance than previous, largely monolingual, evaluations.
However, the paper does not address potential biases or limitations in the dataset construction process, which could impact the fairness and generalizability of the benchmark. Additionally, the authors do not discuss the potential societal implications of developing more powerful multilingual knowledge editing capabilities, such as the risk of spreading misinformation or the potential for misuse.
Further research is needed to explore the ethical considerations and potential unintended consequences of advancing LLM capabilities in this area, as well as to address any biases or limitations in the MLaKE benchmark itself.
Conclusion
The MLaKE benchmark represents a significant contribution to the field of large language model evaluation, providing a comprehensive test of LLM capabilities in multilingual knowledge editing tasks. The baseline results highlight the challenges posed by the benchmark and the need for further advancements in this area.
As LLMs continue to grow in power and influence, it is crucial that the research community remains vigilant in evaluating their capabilities and limitations, while also considering the broader societal implications of these technologies. The MLaKE benchmark is an important step in this direction, but ongoing work is needed to ensure that the development of LLMs aligns with ethical principles and the best interests of humanity.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Event-level Knowledge Editing
Hao Peng, Xiaozhi Wang, Chunyang Li, Kaisheng Zeng, Jiangshan Duo, Yixin Cao, Lei Hou, Juanzi Li
0
0
Knowledge editing aims at updating knowledge of large language models (LLMs) to prevent them from becoming outdated. Existing work edits LLMs at the level of factual knowledge triplets. However, natural knowledge updates in the real world come from the occurrences of new events rather than direct changes in factual triplets. In this paper, we propose a new task setting: event-level knowledge editing, which directly edits new events into LLMs and improves over conventional triplet-level editing on (1) Efficiency. A single event edit leads to updates in multiple entailed knowledge triplets. (2) Completeness. Beyond updating factual knowledge, event-level editing also requires considering the event influences and updating LLMs' knowledge about future trends. We construct a high-quality event-level editing benchmark ELKEN, consisting of 1,515 event edits, 6,449 questions about factual knowledge, and 10,150 questions about future tendencies. We systematically evaluate the performance of various knowledge editing methods and LLMs on this benchmark. We find that ELKEN poses significant challenges to existing knowledge editing approaches. Our codes and dataset are publicly released to facilitate further research.
4/23/2024
Unveiling the Pitfalls of Knowledge Editing for Large Language Models
Zhoubo Li, Ningyu Zhang, Yunzhi Yao, Mengru Wang, Xi Chen, Huajun Chen
0
0
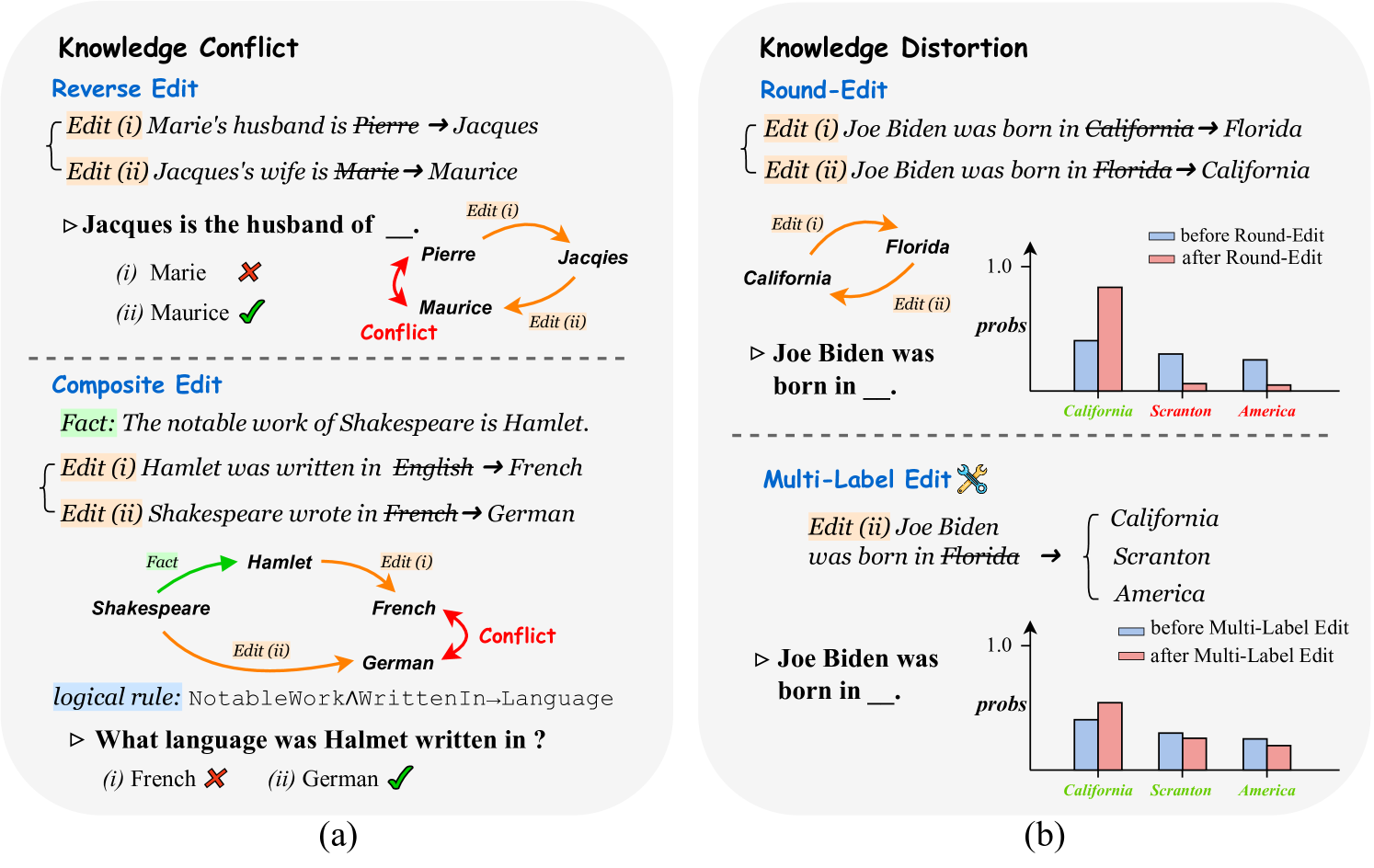
As the cost associated with fine-tuning Large Language Models (LLMs) continues to rise, recent research efforts have pivoted towards developing methodologies to edit implicit knowledge embedded within LLMs. Yet, there's still a dark cloud lingering overhead -- will knowledge editing trigger butterfly effect? since it is still unclear whether knowledge editing might introduce side effects that pose potential risks or not. This paper pioneers the investigation into the potential pitfalls associated with knowledge editing for LLMs. To achieve this, we introduce new benchmark datasets and propose innovative evaluation metrics. Our results underline two pivotal concerns: (1) Knowledge Conflict: Editing groups of facts that logically clash can magnify the inherent inconsistencies in LLMs-a facet neglected by previous methods. (2) Knowledge Distortion: Altering parameters with the aim of editing factual knowledge can irrevocably warp the innate knowledge structure of LLMs. Experimental results vividly demonstrate that knowledge editing might inadvertently cast a shadow of unintended consequences on LLMs, which warrant attention and efforts for future works. Code and data are available at https://github.com/zjunlp/PitfallsKnowledgeEditing.
5/14/2024
💬
Can We Edit Multimodal Large Language Models?
Siyuan Cheng, Bozhong Tian, Qingbin Liu, Xi Chen, Yongheng Wang, Huajun Chen, Ningyu Zhang
0
0
In this paper, we focus on editing Multimodal Large Language Models (MLLMs). Compared to editing single-modal LLMs, multimodal model editing is more challenging, which demands a higher level of scrutiny and careful consideration in the editing process. To facilitate research in this area, we construct a new benchmark, dubbed MMEdit, for editing multimodal LLMs and establishing a suite of innovative metrics for evaluation. We conduct comprehensive experiments involving various model editing baselines and analyze the impact of editing different components for multimodal LLMs. Empirically, we notice that previous baselines can implement editing multimodal LLMs to some extent, but the effect is still barely satisfactory, indicating the potential difficulty of this task. We hope that our work can provide the NLP community with insights. Code and dataset are available in https://github.com/zjunlp/EasyEdit.
4/19/2024
MedExpQA: Multilingual Benchmarking of Large Language Models for Medical Question Answering
I~nigo Alonso, Maite Oronoz, Rodrigo Agerri
0
0
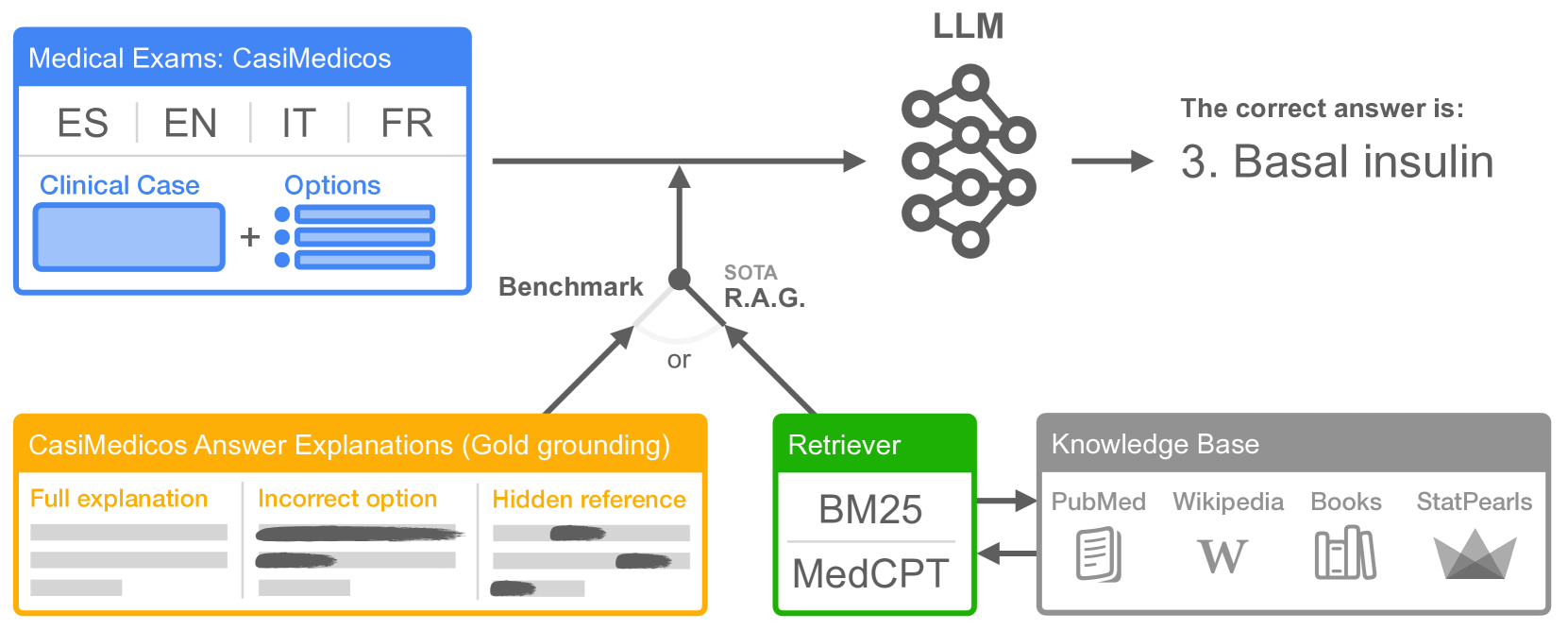
Large Language Models (LLMs) have the potential of facilitating the development of Artificial Intelligence technology to assist medical experts for interactive decision support, which has been demonstrated by their competitive performances in Medical QA. However, while impressive, the required quality bar for medical applications remains far from being achieved. Currently, LLMs remain challenged by outdated knowledge and by their tendency to generate hallucinated content. Furthermore, most benchmarks to assess medical knowledge lack reference gold explanations which means that it is not possible to evaluate the reasoning of LLMs predictions. Finally, the situation is particularly grim if we consider benchmarking LLMs for languages other than English which remains, as far as we know, a totally neglected topic. In order to address these shortcomings, in this paper we present MedExpQA, the first multilingual benchmark based on medical exams to evaluate LLMs in Medical Question Answering. To the best of our knowledge, MedExpQA includes for the first time reference gold explanations written by medical doctors which can be leveraged to establish various gold-based upper-bounds for comparison with LLMs performance. Comprehensive multilingual experimentation using both the gold reference explanations and Retrieval Augmented Generation (RAG) approaches show that performance of LLMs still has large room for improvement, especially for languages other than English. Furthermore, and despite using state-of-the-art RAG methods, our results also demonstrate the difficulty of obtaining and integrating readily available medical knowledge that may positively impact results on downstream evaluations for Medical Question Answering. So far the benchmark is available in four languages, but we hope that this work may encourage further development to other languages.
4/9/2024