MRIo3DS-Net: A Mutually Reinforcing Images to 3D Surface RNN-like framework for model-adaptation indoor 3D reconstruction

0
✨
Sign in to get full access
Overview
- This paper proposes a new end-to-end framework called MRIo3DS-Net for indoor 3D reconstruction from multiple images.
- The framework combines multi-view dense matching and point cloud surface optimization, where the two modules mutually reinforce each other through a recurrent neural network-like structure.
- Key innovations include model adaptation strategies, smooth loss functions, and a multi-task loss for transfer learning.
- The framework is modular and flexible, allowing different state-of-the-art networks to be used for the individual components.
Plain English Explanation
The researchers have developed a new system called MRIo3DS-Net that can create detailed 3D models from multiple camera images of indoor environments. Rather than treating the different steps of this process - like matching features between images and optimizing the 3D surface - as separate tasks, the system links them together in a mutually reinforcing way.
The system has two main components: a multi-view dense matching module that uses a specialized neural network to find detailed correspondences between features in different images, and a point cloud surface optimization module that takes the resulting 3D point cloud and reconstructs a smooth 3D surface. These two modules are connected in a recurrent neural network-like structure, where the output of one module is used to iteratively refine and improve the other.
This mutual reinforcement allows the system to progressively enhance both the dense image matching and the 3D surface reconstruction. The researchers also developed some novel techniques to help this process, like using "model adaptation" to fine-tune the neural networks, adding a "smooth loss" function to improve the 3D surface, and using a "multi-task loss" to help the system transfer what it's learned to new environments.
The end result is a flexible system that can produce very detailed 3D reconstructions of indoor spaces from ordinary camera images, with the different components working together in a clever way to maximize the quality of the final output.
Technical Explanation
The key innovation in this paper is the MRIo3DS-Net framework, which tightly integrates multi-view dense matching and point cloud surface optimization through a recurrent neural network-like structure.
The multi-view dense matching module uses a Transformer-based neural network that is fine-tuned and optimized using a "model adaptation" strategy. This allows the network to develop stronger image feature matching and detail expression capabilities.
The point cloud surface optimization module is based on a 3D implicit field neural network, which is also optimized using model adaptation. This solves the challenge of 3D surface reconstruction without knowing the normal vectors of the 3D points.
To further improve the 3D surface reconstruction, the researchers introduce a "smooth loss" function that is added to this module.
The overall MRIo3DS-Net framework uses the output of the point cloud surface optimization to recursively refine and improve the multi-view dense matching. This mutual reinforcement between the two modules leads to iterative improvements in both the dense image matching and the final 3D reconstruction.
To accelerate the transfer of the system to new environments, the researchers use a multi-task loss function based on Bayesian uncertainty. This adaptively adjusts the relative weights of the losses for the two network modules.
Importantly, the MRIo3DS-Net framework is modular, allowing different state-of-the-art networks to be plugged into the multi-view diffusion or point cloud optimization components to potentially achieve even better 3D reconstruction results.
Critical Analysis
The paper provides a comprehensive technical description of the MRIo3DS-Net framework and its key innovations. The mutual reinforcement of the dense matching and surface optimization modules is a clever approach that appears to yield improved 3D reconstruction quality.
However, the paper does not provide much insight into the limitations or failure modes of the system. It would be helpful to know more about the types of scenes or geometries that pose challenges, the computational and memory requirements of the framework, and any other constraints or tradeoffs involved.
Additionally, while the modular design is highlighted as a strength, the paper does not explore in depth how different state-of-the-art networks could be integrated or how they might impact the overall performance. Some discussion of the transferability and generalizability of the approach would also be valuable.
Overall, the MRIo3DS-Net framework seems like a promising advance in 3D reconstruction from multi-view imagery. But a more critical examination of its weaknesses and limitations, as well as its flexibility and scalability, would help provide a more balanced assessment of the research.
Conclusion
This paper presents a novel end-to-end framework called MRIo3DS-Net for high-quality 3D reconstruction from multiple camera images of indoor environments. The key innovation is the tight integration of multi-view dense matching and point cloud surface optimization, where the two modules mutually reinforce each other through a recurrent neural network-like structure.
The researchers have developed several technical advances to enable this, including model adaptation strategies, smooth loss functions, and a multi-task loss for transfer learning. The modular design of the framework also allows different state-of-the-art networks to be used for the individual components.
Overall, the MRIo3DS-Net framework appears to be a significant step forward in producing detailed 3D models from ordinary camera images. While the paper could benefit from a more critical examination of the system's limitations and tradeoffs, the core ideas represent an interesting and promising direction for further research and development in 3D reconstruction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
✨
0
MRIo3DS-Net: A Mutually Reinforcing Images to 3D Surface RNN-like framework for model-adaptation indoor 3D reconstruction
Chang Li, Jiao Guo, Yufei Zhao, Yongjun Zhang
This paper is the first to propose an end-to-end framework of mutually reinforcing images to 3D surface recurrent neural network-like for model-adaptation indoor 3D reconstruction,where multi-view dense matching and point cloud surface optimization are mutually reinforced by a RNN-like structure rather than being treated as a separate issue.The characteristics are as follows:In the multi-view dense matching module, the model-adaptation strategy is used to fine-tune and optimize a Transformer-based multi-view dense matching DNN,so that it has the higher image feature for matching and detail expression capabilities;In the point cloud surface optimization module,the 3D surface reconstruction network based on 3D implicit field is optimized by using model-adaptation strategy,which solves the problem of point cloud surface optimization without knowing normal vector of 3D surface.To improve and finely reconstruct 3D surfaces from point cloud,smooth loss is proposed and added to this module;The MRIo3DS-Net is a RNN-like framework,which utilizes the finely optimized 3D surface obtained by PCSOM to recursively reinforce the differentiable warping for optimizing MVDMM.This refinement leads to achieving better dense matching results, and better dense matching results leads to achieving better 3D surface results recursively and mutually.Hence, model-adaptation strategy can better collaborate the differences between the two network modules,so that they complement each other to achieve the better effect;To accelerate the transfer learning and training convergence from source domain to target domain,a multi-task loss function based on Bayesian uncertainty is used to adaptively adjust the weights between the two networks loss functions of MVDMM and PCSOM;In this multi-task cascade network framework,any modules can be replaced by any state-of-the-art networks to achieve better 3D reconstruction results.
Read more7/17/2024
0
A Collaborative Model-driven Network for MRI Reconstruction
Xiaoyu Qiao, Weisheng Li, Guofen Wang, Yuping Huang
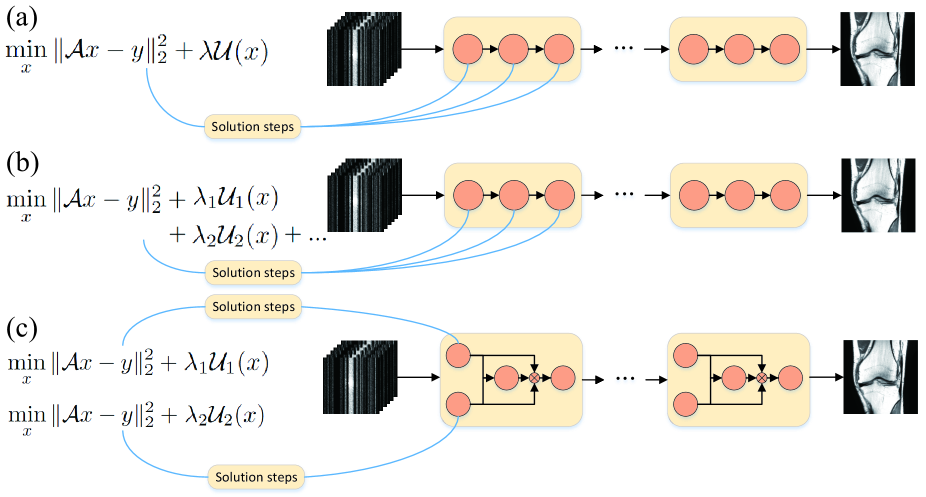
Deep learning (DL)-based methods offer a promising solution to reduce the prolonged scanning time in magnetic resonance imaging (MRI). While model-driven DL methods have demonstrated convincing results by incorporating prior knowledge into deep networks, further exploration is needed to optimize the integration of diverse priors.. Existing model-driven networks typically utilize linearly stacked unrolled cascades to mimic iterative solution steps in optimization algorithms. However, this approach needs to find a balance between different prior-based regularizers during training, resulting in slower convergence and suboptimal reconstructions. To overcome the limitations, we propose a collaborative model-driven network to maximally exploit the complementarity of different regularizers. We design attention modules to learn both the relative confidence (RC) and overall confidence (OC) for the intermediate reconstructions (IRs) generated by different prior-based subnetworks. RC assigns more weight to the areas of expertise of the subnetworks, enabling precise element-wise collaboration. We design correction modules to tackle bottleneck scenarios where both subnetworks exhibit low accuracy, and they further optimize the IRs based on OC maps. IRs across various stages are concatenated and fed to the attention modules to build robust and accurate confidence maps. Experimental results on multiple datasets showed significant improvements in the final results without additional computational costs. Moreover, the proposed model-driven network design strategy can be conveniently applied to various model-driven methods to improve their performance.
Read more5/7/2024

0
RCNet: Deep Recurrent Collaborative Network for Multi-View Low-Light Image Enhancement
Hao Luo, Baoliang Chen, Lingyu Zhu, Peilin Chen, Shiqi Wang
Scene observation from multiple perspectives would bring a more comprehensive visual experience. However, in the context of acquiring multiple views in the dark, the highly correlated views are seriously alienated, making it challenging to improve scene understanding with auxiliary views. Recent single image-based enhancement methods may not be able to provide consistently desirable restoration performance for all views due to the ignorance of potential feature correspondence among different views. To alleviate this issue, we make the first attempt to investigate multi-view low-light image enhancement. First, we construct a new dataset called Multi-View Low-light Triplets (MVLT), including 1,860 pairs of triple images with large illumination ranges and wide noise distribution. Each triplet is equipped with three different viewpoints towards the same scene. Second, we propose a deep multi-view enhancement framework based on the Recurrent Collaborative Network (RCNet). Specifically, in order to benefit from similar texture correspondence across different views, we design the recurrent feature enhancement, alignment and fusion (ReEAF) module, in which intra-view feature enhancement (Intra-view EN) followed by inter-view feature alignment and fusion (Inter-view AF) is performed to model the intra-view and inter-view feature propagation sequentially via multi-view collaboration. In addition, two different modules from enhancement to alignment (E2A) and from alignment to enhancement (A2E) are developed to enable the interactions between Intra-view EN and Inter-view AF, which explicitly utilize attentive feature weighting and sampling for enhancement and alignment, respectively. Experimental results demonstrate that our RCNet significantly outperforms other state-of-the-art methods. All of our dataset, code, and model will be available at https://github.com/hluo29/RCNet.
Read more9/9/2024

0
VI3DRM:Towards meticulous 3D Reconstruction from Sparse Views via Photo-Realistic Novel View Synthesis
Hao Chen, Jiafu Wu, Ying Jin, Jinlong Peng, Xiaofeng Mao, Mingmin Chi, Mufeng Yao, Bo Peng, Jian Li, Yun Cao
Recently, methods like Zero-1-2-3 have focused on single-view based 3D reconstruction and have achieved remarkable success. However, their predictions for unseen areas heavily rely on the inductive bias of large-scale pretrained diffusion models. Although subsequent work, such as DreamComposer, attempts to make predictions more controllable by incorporating additional views, the results remain unrealistic due to feature entanglement in the vanilla latent space, including factors such as lighting, material, and structure. To address these issues, we introduce the Visual Isotropy 3D Reconstruction Model (VI3DRM), a diffusion-based sparse views 3D reconstruction model that operates within an ID consistent and perspective-disentangled 3D latent space. By facilitating the disentanglement of semantic information, color, material properties and lighting, VI3DRM is capable of generating highly realistic images that are indistinguishable from real photographs. By leveraging both real and synthesized images, our approach enables the accurate construction of pointmaps, ultimately producing finely textured meshes or point clouds. On the NVS task, tested on the GSO dataset, VI3DRM significantly outperforms state-of-the-art method DreamComposer, achieving a PSNR of 38.61, an SSIM of 0.929, and an LPIPS of 0.027. Code will be made available upon publication.
Read more9/14/2024