CN-RMA: Combined Network with Ray Marching Aggregation for 3D Indoors Object Detection from Multi-view Images

0
Sign in to get full access
Overview
- This paper proposes a novel 3D object detection model called "CN-RMA" (Combined Network with Ray Marching Aggregation) for detecting objects in indoor spaces from multi-view images.
- The model combines a 2D object detection network with a 3D ray marching aggregation module to efficiently process multi-view data and infer 3D bounding boxes.
- The key innovation is the ray marching aggregation module, which efficiently combines 2D detection results across multiple views to estimate the 3D location and shape of objects.
Plain English Explanation
The paper describes a new AI system that can detect and locate 3D objects inside buildings using multiple camera views. The system first uses a 2D object detection network to identify objects in individual camera images. It then combines the 2D detections from multiple views using a special "ray marching" technique to estimate the 3D position and shape of the detected objects.
The key innovation is this ray marching aggregation module, which efficiently integrates the 2D detection results to infer the 3D properties of the objects. This allows the system to accurately detect and localize 3D objects in indoor environments using only 2D camera images, without needing expensive 3D sensors like laser scanners.
Technical Explanation
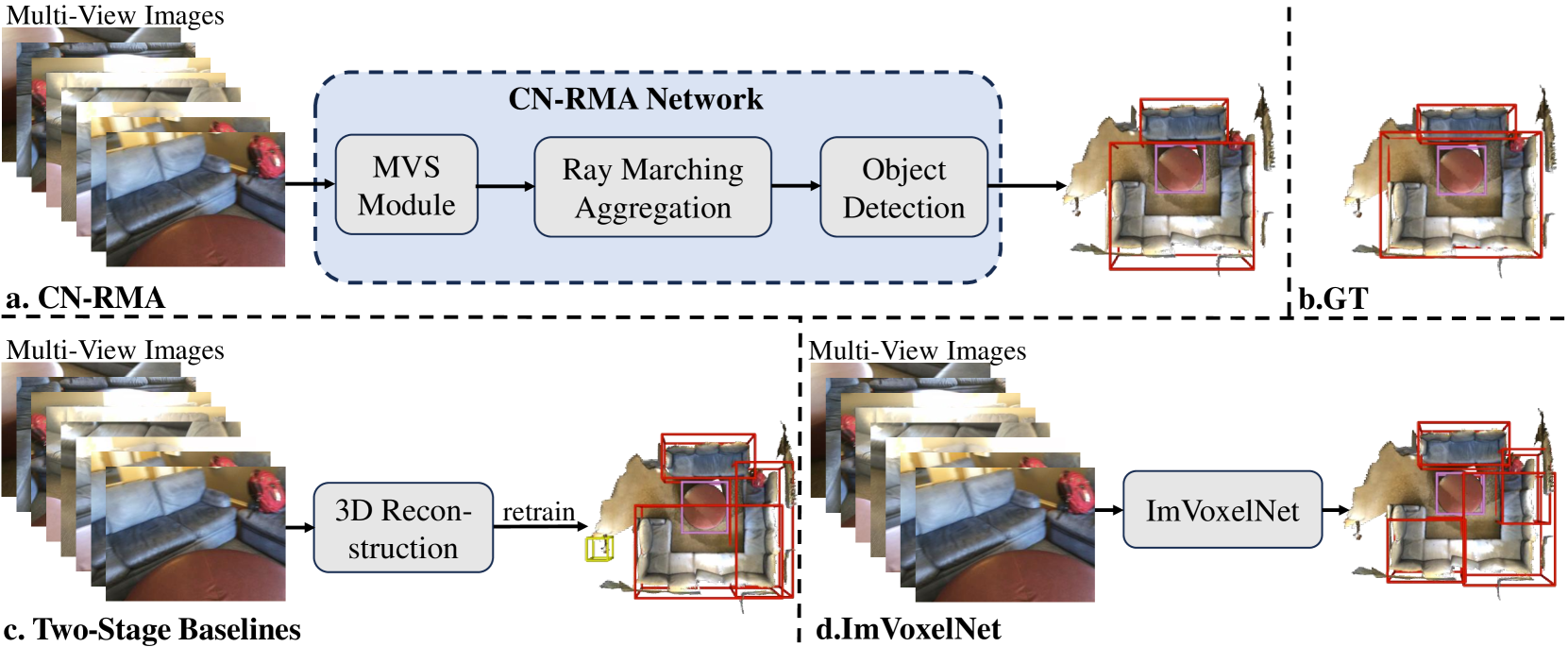
The paper proposes the CN-RMA model, which consists of two main components:
- A 2D object detection network that processes individual camera images to identify the locations of objects in 2D.
- A 3D ray marching aggregation module that combines the 2D detections from multiple views to estimate the 3D position and shape of the objects.
The ray marching module efficiently aggregates the 2D detections by tracing "rays" from each camera through the 3D space and accumulating the detection scores along these rays. This allows the model to effectively leverage multi-view information to infer the 3D properties of the objects, without requiring explicit 3D reconstruction.
The authors evaluate the CN-RMA model on a challenging indoor 3D object detection dataset, and show that it outperforms previous state-of-the-art methods that rely on RGB-D sensors or explicit 3D reasoning. This demonstrates the effectiveness of the proposed ray marching aggregation approach for leveraging multi-view 2D data to enable efficient 3D object detection.
Critical Analysis
The paper makes a compelling case for the CN-RMA model and its ability to perform accurate 3D object detection using only multi-view 2D images. However, a few potential limitations are worth noting:
- The method relies on the accuracy of the underlying 2D object detector, and may be susceptible to errors in the initial 2D detections.
- The ray marching aggregation might not work as well in cluttered environments with significant occlusions, where the 3D geometry cannot be reliably inferred from the 2D views.
- The paper does not explore the model's performance in outdoor or large-scale settings, where the camera views and object scales may differ significantly from the evaluated indoor dataset.
Further research could investigate ways to make the CN-RMA model more robust to noisy or incomplete 2D detections, as well as explore its applicability to a wider range of 3D object detection scenarios beyond indoor environments.
Conclusion
The CN-RMA model presented in this paper offers a promising approach for 3D object detection using only multi-view 2D images, without the need for expensive 3D sensors. The key innovation of the ray marching aggregation module allows the model to efficiently leverage information from multiple views to infer the 3D properties of objects, leading to state-of-the-art performance on an indoor 3D object detection benchmark.
While the method has some potential limitations, the paper demonstrates the power of combining 2D and 3D reasoning for enabling accurate 3D perception from multi-view imagery. This work could have important implications for a wide range of applications, from autonomous navigation to augmented reality, where efficient and cost-effective 3D object detection is a critical requirement.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CN-RMA: Combined Network with Ray Marching Aggregation for 3D Indoors Object Detection from Multi-view Images
Guanlin Shen, Jingwei Huang, Zhihua Hu, Bin Wang
This paper introduces CN-RMA, a novel approach for 3D indoor object detection from multi-view images. We observe the key challenge as the ambiguity of image and 3D correspondence without explicit geometry to provide occlusion information. To address this issue, CN-RMA leverages the synergy of 3D reconstruction networks and 3D object detection networks, where the reconstruction network provides a rough Truncated Signed Distance Function (TSDF) and guides image features to vote to 3D space correctly in an end-to-end manner. Specifically, we associate weights to sampled points of each ray through ray marching, representing the contribution of a pixel in an image to corresponding 3D locations. Such weights are determined by the predicted signed distances so that image features vote only to regions near the reconstructed surface. Our method achieves state-of-the-art performance in 3D object detection from multi-view images, as measured by [email protected] and [email protected] on the ScanNet and ARKitScenes datasets. The code and models are released at https://github.com/SerCharles/CN-RMA.
Read more4/10/2024
✨
0
MRIo3DS-Net: A Mutually Reinforcing Images to 3D Surface RNN-like framework for model-adaptation indoor 3D reconstruction
Chang Li, Jiao Guo, Yufei Zhao, Yongjun Zhang
This paper is the first to propose an end-to-end framework of mutually reinforcing images to 3D surface recurrent neural network-like for model-adaptation indoor 3D reconstruction,where multi-view dense matching and point cloud surface optimization are mutually reinforced by a RNN-like structure rather than being treated as a separate issue.The characteristics are as follows:In the multi-view dense matching module, the model-adaptation strategy is used to fine-tune and optimize a Transformer-based multi-view dense matching DNN,so that it has the higher image feature for matching and detail expression capabilities;In the point cloud surface optimization module,the 3D surface reconstruction network based on 3D implicit field is optimized by using model-adaptation strategy,which solves the problem of point cloud surface optimization without knowing normal vector of 3D surface.To improve and finely reconstruct 3D surfaces from point cloud,smooth loss is proposed and added to this module;The MRIo3DS-Net is a RNN-like framework,which utilizes the finely optimized 3D surface obtained by PCSOM to recursively reinforce the differentiable warping for optimizing MVDMM.This refinement leads to achieving better dense matching results, and better dense matching results leads to achieving better 3D surface results recursively and mutually.Hence, model-adaptation strategy can better collaborate the differences between the two network modules,so that they complement each other to achieve the better effect;To accelerate the transfer learning and training convergence from source domain to target domain,a multi-task loss function based on Bayesian uncertainty is used to adaptively adjust the weights between the two networks loss functions of MVDMM and PCSOM;In this multi-task cascade network framework,any modules can be replaced by any state-of-the-art networks to achieve better 3D reconstruction results.
Read more7/17/2024

0
Riemann-based Multi-scale Attention Reasoning Network for Text-3D Retrieval
Wenrui Li, Wei Han, Yandu Chen, Yeyu Chai, Yidan Lu, Xingtao Wang, Xiaopeng Fan
Due to the challenges in acquiring paired Text-3D data and the inherent irregularity of 3D data structures, combined representation learning of 3D point clouds and text remains unexplored. In this paper, we propose a novel Riemann-based Multi-scale Attention Reasoning Network (RMARN) for text-3D retrieval. Specifically, the extracted text and point cloud features are refined by their respective Adaptive Feature Refiner (AFR). Furthermore, we introduce the innovative Riemann Local Similarity (RLS) module and the Global Pooling Similarity (GPS) module. However, as 3D point cloud data and text data often possess complex geometric structures in high-dimensional space, the proposed RLS employs a novel Riemann Attention Mechanism to reflect the intrinsic geometric relationships of the data. Without explicitly defining the manifold, RMARN learns the manifold parameters to better represent the distances between text-point cloud samples. To address the challenges of lacking paired text-3D data, we have created the large-scale Text-3D Retrieval dataset T3DR-HIT, which comprises over 3,380 pairs of text and point cloud data. T3DR-HIT contains coarse-grained indoor 3D scenes and fine-grained Chinese artifact scenes, consisting of 1,380 and over 2,000 text-3D pairs, respectively. Experiments on our custom datasets demonstrate the superior performance of the proposed method. Our code and proposed datasets are available at url{https://github.com/liwrui/RMARN}.
Read more8/27/2024

0
RMAFF-PSN: A Residual Multi-Scale Attention Feature Fusion Photometric Stereo Network
Kai Luo, Yakun Ju, Lin Qi, Kaixuan Wang, Junyu Dong
Predicting accurate normal maps of objects from two-dimensional images in regions of complex structure and spatial material variations is challenging using photometric stereo methods due to the influence of surface reflection properties caused by variations in object geometry and surface materials. To address this issue, we propose a photometric stereo network called a RMAFF-PSN that uses residual multiscale attentional feature fusion to handle the ``difficult'' regions of the object. Unlike previous approaches that only use stacked convolutional layers to extract deep features from the input image, our method integrates feature information from different resolution stages and scales of the image. This approach preserves more physical information, such as texture and geometry of the object in complex regions, through shallow-deep stage feature extraction, double branching enhancement, and attention optimization. To test the network structure under real-world conditions, we propose a new real dataset called Simple PS data, which contains multiple objects with varying structures and materials. Experimental results on a publicly available benchmark dataset demonstrate that our method outperforms most existing calibrated photometric stereo methods for the same number of input images, especially in the case of highly non-convex object structures. Our method also obtains good results under sparse lighting conditions.
Read more4/16/2024