Msmsfnet: a multi-stream and multi-scale fusion net for edge detection

0

Sign in to get full access
Overview
- Proposes a multi-stream and multi-scale fusion network called Msmsfnet for edge detection
- Leverages pretrained weights from ImageNet to improve performance
- Compares Msmsfnet to other edge detection models on various datasets
Plain English Explanation
Msmsfnet is a deep learning model designed for the task of edge detection. Edge detection is the process of identifying the boundaries or edges of objects in an image. This is an important step in many computer vision applications, such as image segmentation, object recognition, and autonomous driving.
The key innovation of Msmsfnet is its use of multiple input streams and multiple scales of feature extraction. By processing the input image at different scales and then fusing the resulting features, the model is able to capture both local and global information about the edges in the image. This multi-scale approach helps the model perform more accurately than previous edge detection models.
Additionally, the researchers leverage pretrained weights from the ImageNet dataset, which contains a large number of natural images. This transfer learning approach allows the model to benefit from the general visual features learned on ImageNet, further boosting its performance on edge detection tasks.
The paper compares Msmsfnet to other state-of-the-art edge detection models on several benchmark datasets, demonstrating its superior performance in terms of accuracy and robustness. This suggests that Msmsfnet could be a valuable tool for developers and researchers working on computer vision applications that require accurate edge detection.
Technical Explanation
The Msmsfnet architecture consists of multiple input streams, each processing the input image at a different scale. These streams are then fused together using a multi-scale fusion module, which combines the features from the different scales to produce the final edge detection output.
The model is built upon a pretrained backbone network, such as ResNet or VGG, which has been trained on the large-scale ImageNet dataset. This allows the model to benefit from the general visual features learned during this pretraining process, improving its performance on the edge detection task.
The researchers conduct experiments on several benchmark datasets, including BSDS500, NYUD, and Multicue. The results demonstrate that Msmsfnet outperforms other state-of-the-art edge detection models in terms of various performance metrics, such as F-measure and precision-recall curves.
Critical Analysis
The paper provides a thorough evaluation of Msmsfnet's performance on multiple edge detection datasets, which is a strength of the research. However, the authors do not delve deeply into the potential limitations or weaknesses of the model. For example, it would be useful to understand how Msmsfnet performs on more challenging or diverse datasets, or how it might handle edge cases where the edges are particularly subtle or complex.
Additionally, the paper does not explore potential trade-offs between the model's accuracy and its computational complexity or inference time. This information would be valuable for developers who need to balance performance and efficiency in real-world applications.
Conclusion
The Msmsfnet model represents a significant advancement in the field of edge detection, leveraging multiple input streams and multi-scale fusion to achieve state-of-the-art performance on several benchmark datasets. The use of pretrained weights from the ImageNet dataset is a particularly noteworthy contribution, as it demonstrates the power of transfer learning to boost the performance of specialized computer vision models.
While the paper provides a solid technical foundation and compelling results, further research is needed to fully understand the model's limitations and explore its potential for real-world applications. Nonetheless, Msmsfnet's strong performance suggests that it could be a valuable tool for researchers and developers working on a wide range of computer vision tasks that rely on accurate edge detection.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Msmsfnet: a multi-stream and multi-scale fusion net for edge detection
Chenguang Liu, Chisheng Wang, Feifei Dong, Xin Su, Chuanhua Zhu, Dejin Zhang, Qingquan Li
Edge detection is a long standing problem in computer vision. Recent deep learning based algorithms achieve state of-the-art performance in publicly available datasets. Despite the efficiency of these algorithms, their performance, however, relies heavily on the pretrained weights of the backbone network on the ImageNet dataset. This limits heavily the design space of deep learning based edge detectors. Whenever we want to devise a new model, we have to train this new model on the ImageNet dataset first, and then fine tune the model using the edge detection datasets. The comparison would be unfair otherwise. However, it is usually not feasible for many researchers to train a model on the ImageNet dataset due to the limited computation resources. In this work, we study the performance that can be achieved by state-of-the-art deep learning based edge detectors in publicly available datasets when they are trained from scratch, and devise a new network architecture, the multi-stream and multi scale fusion net (msmsfnet), for edge detection. We show in our experiments that by training all models from scratch to ensure the fairness of comparison, out model outperforms state-of-the art deep learning based edge detectors in three publicly available datasets.
Read more4/9/2024

0
EMDFNet: Efficient Multi-scale and Diverse Feature Network for Traffic Sign Detection
Pengyu Li, Chenhe Liu, Tengfei Li, Xinyu Wang, Shihui Zhang, Dongyang Yu
The detection of small objects, particularly traffic signs, is a critical subtask within object detection and autonomous driving. Despite the notable achievements in previous research, two primary challenges persist. Firstly, the main issue is the singleness of feature extraction. Secondly, the detection process fails to effectively integrate with objects of varying sizes or scales. These issues are also prevalent in generic object detection. Motivated by these challenges, in this paper, we propose a novel object detection network named Efficient Multi-scale and Diverse Feature Network (EMDFNet) for traffic sign detection that integrates an Augmented Shortcut Module and an Efficient Hybrid Encoder to address the aforementioned issues simultaneously. Specifically, the Augmented Shortcut Module utilizes multiple branches to integrate various spatial semantic information and channel semantic information, thereby enhancing feature diversity. The Efficient Hybrid Encoder utilizes global feature fusion and local feature interaction based on various features to generate distinctive classification features by integrating feature information in an adaptable manner. Extensive experiments on the Tsinghua-Tencent 100K (TT100K) benchmark and the German Traffic Sign Detection Benchmark (GTSDB) demonstrate that our EMDFNet outperforms other state-of-the-art detectors in performance while retaining the real-time processing capabilities of single-stage models. This substantiates the effectiveness of EMDFNet in detecting small traffic signs.
Read more8/27/2024
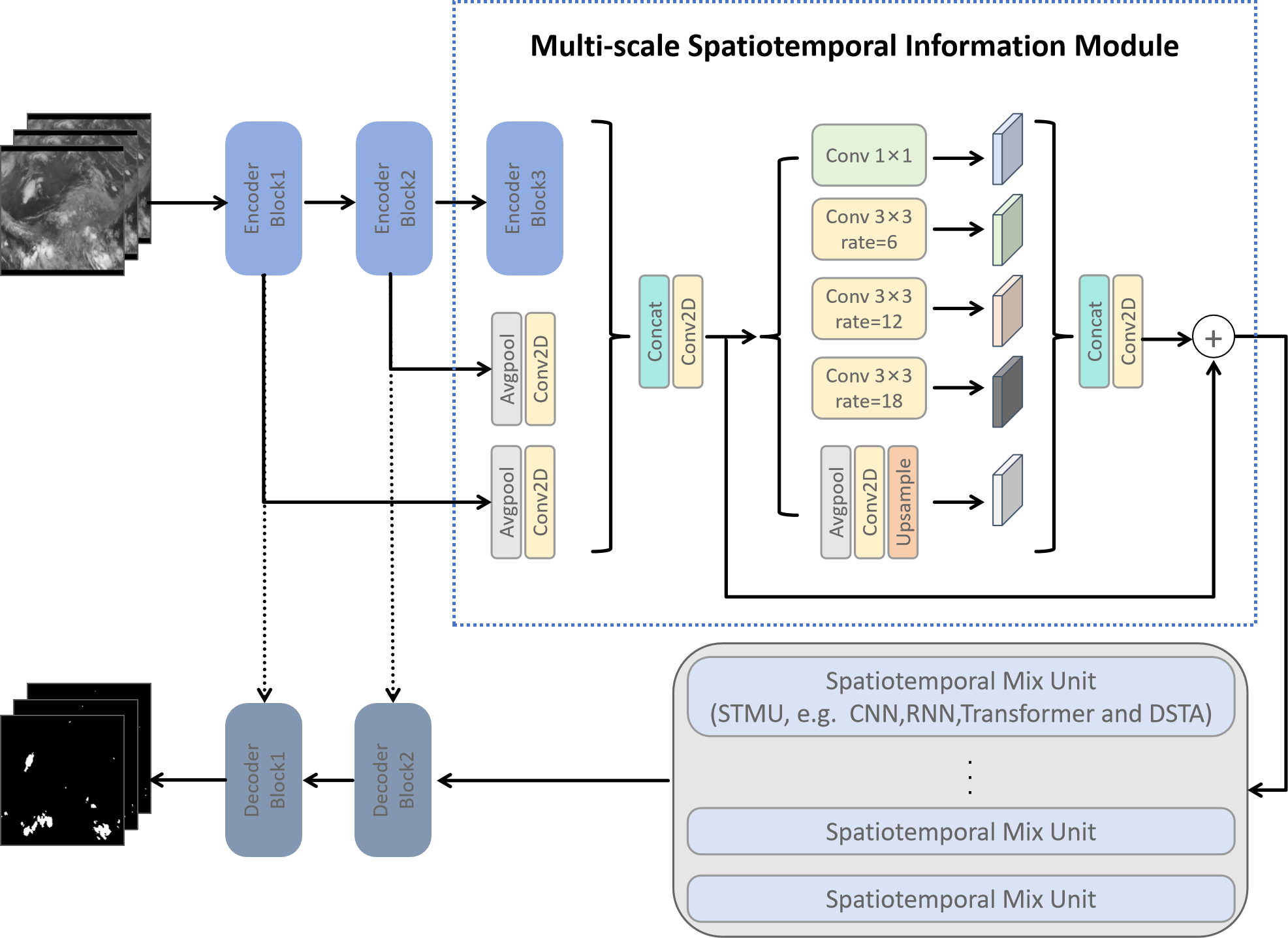
0
MCSDNet: Mesoscale Convective System Detection Network via Multi-scale Spatiotemporal Information
Jiajun Liang, Baoquan Zhang, Yunming Ye, Xutao Li, Chuyao Luo, Xukai Fu
The accurate detection of Mesoscale Convective Systems (MCS) is crucial for meteorological monitoring due to their potential to cause significant destruction through severe weather phenomena such as hail, thunderstorms, and heavy rainfall. However, the existing methods for MCS detection mostly targets on single-frame detection, which just considers the static characteristics and ignores the temporal evolution in the life cycle of MCS. In this paper, we propose a novel encoder-decoder neural network for MCS detection(MCSDNet). MCSDNet has a simple architecture and is easy to expand. Different from the previous models, MCSDNet targets on multi-frames detection and leverages multi-scale spatiotemporal information for the detection of MCS regions in remote sensing imagery(RSI). As far as we know, it is the first work to utilize multi-scale spatiotemporal information to detect MCS regions. Firstly, we design a multi-scale spatiotemporal information module to extract multi-level semantic from different encoder levels, which makes our models can extract more detail spatiotemporal features. Secondly, a Spatiotemporal Mix Unit(STMU) is introduced to MCSDNet to capture both intra-frame features and inter-frame correlations, which is a scalable module and can be replaced by other spatiotemporal module, e.g., CNN, RNN, Transformer and our proposed Dual Spatiotemporal Attention(DSTA). This means that the future works about spatiotemporal modules can be easily integrated to our model. Finally, we present MCSRSI, the first publicly available dataset for multi-frames MCS detection based on visible channel images from the FY-4A satellite. We also conduct several experiments on MCSRSI and find that our proposed MCSDNet achieve the best performance on MCS detection task when comparing to other baseline methods.
Read more4/29/2024
🔎
0
Learning to utilize gradient information for crisp edge detection
Changsong Liu, Wei Zhang, Yanyan Liu, Yimeng Fan, Mingyang Li, Wenlin Li
Edge detection is a fundamental task in computer vision. It has made great progress under the development of deep convolutional neural networks (DCNNs), some of which have achieved a beyond human-level performance. However, recent top-performing edge detection methods tend to generate thick and noisy edge lines. In this work, we solve this problem from two aspects: (1) the lack of prior knowledge regarding image edges, and (2) the issue of imbalanced pixel distribution. We propose a second-order derivative-based multi-scale contextual enhancement module (SDMCM) to help the model locate true edge pixels accurately by introducing the edge prior knowledge. We also construct a hybrid focal loss function (HFL) to alleviate the imbalanced distribution issue. In addition, we employ the conditionally parameterized convolution (CondConv) to develop a novel boundary refinement module (BRM), which can further refine the final output edge maps. In the end, we propose a U-shape network named LUS-Net which is based on the SDMCM and BRM for crisp edge detection. We perform extensive experiments on three standard benchmarks, and the experiment results illustrate that our method can predict crisp and clean edge maps and achieves state-of-the-art performance on the BSDS500 dataset (ODS=0.829), NYUD-V2 dataset (ODS=0.768), and BIPED dataset (ODS=0.903).
Read more7/1/2024