Efficiently Distilling LLMs for Edge Applications
2404.01353
0
0
👨🏫
Abstract
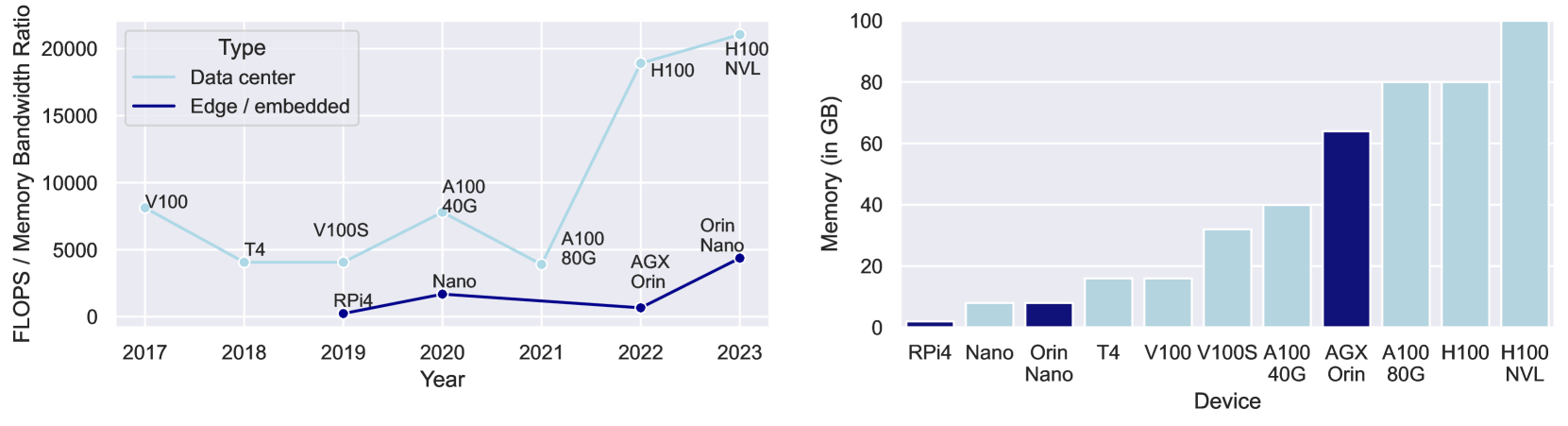
Supernet training of LLMs is of great interest in industrial applications as it confers the ability to produce a palette of smaller models at constant cost, regardless of the number of models (of different size / latency) produced. We propose a new method called Multistage Low-rank Fine-tuning of Super-transformers (MLFS) for parameter-efficient supernet training. We show that it is possible to obtain high-quality encoder models that are suitable for commercial edge applications, and that while decoder-only models are resistant to a comparable degree of compression, decoders can be effectively sliced for a significant reduction in training time.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents a method for efficiently distilling large language models (LLMs) for deployment on edge devices.
- The authors aim to compress the size and improve the performance of LLMs while maintaining their capabilities.
- They develop a novel distillation approach that leverages knowledge distillation and model pruning techniques.
- The proposed solution is evaluated on various tasks and demonstrates significant improvements in model size and inference speed compared to the original LLM.
Plain English Explanation
Large language models (LLMs) have revolutionized natural language processing, but they are often too large and computationally intensive to run on edge devices like smartphones or IoT sensors. This paper addresses this challenge by developing a method to efficiently distill these large models into smaller, faster versions without losing their core capabilities.
The key idea is to use a two-step process. First, they employ knowledge distillation, which involves training a smaller "student" model to mimic the behavior of the larger "teacher" model. This allows the student model to inherit the language understanding and generation abilities of the teacher, but in a more compact form.
Next, they apply model pruning techniques to further reduce the size and complexity of the distilled model. This involves identifying and removing less important neural network connections and parameters, resulting in a even more efficient model that can run on edge devices.
The authors evaluated their approach on a variety of language tasks and found that the distilled models maintained strong performance while being significantly smaller and faster than the original LLMs. This makes them much more practical for real-world applications on resource-constrained edge hardware.
Technical Explanation
The authors propose a two-step distillation approach to efficiently compress large language models (LLMs) for edge deployment. First, they leverage knowledge distillation to train a smaller "student" model to mimic the behavior of a larger "teacher" LLM. This allows the student to inherit the language understanding capabilities of the teacher in a more compact form.
Next, they apply model pruning to further reduce the size and complexity of the distilled student model. Specifically, they use a structured magnitude-based pruning technique to identify and remove less important neural network connections and parameters, resulting in a even more efficient model architecture.
The authors evaluate their approach on a range of NLP tasks, including text generation, sentiment analysis, and question answering. They demonstrate that the distilled models achieve comparable or even better performance than the original LLMs, while being significantly smaller in size (up to 10x reduction) and faster in inference (up to 5x speedup). This makes the distilled models much more practical for deployment on resource-constrained edge devices.
Critical Analysis
The authors provide a thorough evaluation of their distillation approach, including comparisons to other model compression techniques and ablation studies on the individual components. They also acknowledge several limitations and areas for future work.
One potential concern is the generalizability of the results - the experiments were conducted on a limited set of tasks and datasets. Further validation on a broader range of applications and real-world scenarios would help strengthen the claims.
Additionally, the authors do not provide much insight into the tradeoffs involved in the distillation process. For example, how does the performance of the distilled models compare to the original LLMs across different metrics (e.g., accuracy, perplexity, inference latency)? Exploring these tradeoffs in more depth would help users make informed decisions about when to apply this distillation technique.
Overall, the proposed approach represents a promising step towards enabling the deployment of large language models on edge devices. However, additional research is needed to fully understand the capabilities and limitations of the distillation method, as well as its applicability to a wider range of use cases.
Conclusion
This paper presents an effective technique for distilling large language models into more compact and efficient versions, without sacrificing their core capabilities. By combining knowledge distillation and model pruning, the authors demonstrate significant reductions in model size and inference time, making these models much more practical for deployment on resource-constrained edge devices.
The results suggest that this distillation approach could play a crucial role in bridging the gap between the impressive performance of LLMs and the real-world constraints of edge computing. As more applications require the language understanding capabilities of these large models, techniques like the one described in this paper will become increasingly valuable for bringing AI closer to the end user.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤯
Enhancing Inference Efficiency of Large Language Models: Investigating Optimization Strategies and Architectural Innovations
Georgy Tyukin
0
0
Large Language Models are growing in size, and we expect them to continue to do so, as larger models train quicker. However, this increase in size will severely impact inference costs. Therefore model compression is important, to retain the performance of larger models, but with a reduced cost of running them. In this thesis we explore the methods of model compression, and we empirically demonstrate that the simple method of skipping latter attention sublayers in Transformer LLMs is an effective method of model compression, as these layers prove to be redundant, whilst also being incredibly computationally expensive. We observed a 21% speed increase in one-token generation for Llama 2 7B, whilst surprisingly and unexpectedly improving performance over several common benchmarks.
4/10/2024
Federated Fine-Tuning of LLMs on the Very Edge: The Good, the Bad, the Ugly
Herbert Woisetschlager, Alexander Isenko, Shiqiang Wang, Ruben Mayer, Hans-Arno Jacobsen
0
0
Large Language Models (LLM) and foundation models are popular as they offer new opportunities for individuals and businesses to improve natural language processing, interact with data, and retrieve information faster. However, training or fine-tuning LLMs requires a vast amount of data, which can be challenging to access due to legal or technical restrictions and may require private computing resources. Federated Learning (FL) is a solution designed to overcome these challenges and expand data access for deep learning applications. This paper takes a hardware-centric approach to explore how LLMs can be brought to modern edge computing systems. Our study fine-tunes the FLAN-T5 model family, ranging from 80M to 3B parameters, using FL for a text summarization task. We provide a micro-level hardware benchmark, compare the model FLOP utilization to a state-of-the-art data center GPU, and study the network utilization in realistic conditions. Our contribution is twofold: First, we evaluate the current capabilities of edge computing systems and their potential for LLM FL workloads. Second, by comparing these systems with a data-center GPU, we demonstrate the potential for improvement and the next steps toward achieving greater computational efficiency at the edge.
5/3/2024
🛠️
Edge Intelligence Optimization for Large Language Model Inference with Batching and Quantization
Xinyuan Zhang, Jiang Liu, Zehui Xiong, Yudong Huang, Gaochang Xie, Ran Zhang
0
0
Generative Artificial Intelligence (GAI) is taking the world by storm with its unparalleled content creation ability. Large Language Models (LLMs) are at the forefront of this movement. However, the significant resource demands of LLMs often require cloud hosting, which raises issues regarding privacy, latency, and usage limitations. Although edge intelligence has long been utilized to solve these challenges by enabling real-time AI computation on ubiquitous edge resources close to data sources, most research has focused on traditional AI models and has left a gap in addressing the unique characteristics of LLM inference, such as considerable model size, auto-regressive processes, and self-attention mechanisms. In this paper, we present an edge intelligence optimization problem tailored for LLM inference. Specifically, with the deployment of the batching technique and model quantization on resource-limited edge devices, we formulate an inference model for transformer decoder-based LLMs. Furthermore, our approach aims to maximize the inference throughput via batch scheduling and joint allocation of communication and computation resources, while also considering edge resource constraints and varying user requirements of latency and accuracy. To address this NP-hard problem, we develop an optimal Depth-First Tree-Searching algorithm with online tree-Pruning (DFTSP) that operates within a feasible time complexity. Simulation results indicate that DFTSP surpasses other batching benchmarks in throughput across diverse user settings and quantization techniques, and it reduces time complexity by over 45% compared to the brute-force searching method.
5/14/2024
❗
Enabling High-Sparsity Foundational Llama Models with Efficient Pretraining and Deployment
Abhinav Agarwalla, Abhay Gupta, Alexandre Marques, Shubhra Pandit, Michael Goin, Eldar Kurtic, Kevin Leong, Tuan Nguyen, Mahmoud Salem, Dan Alistarh, Sean Lie, Mark Kurtz
0
0
Large language models (LLMs) have revolutionized Natural Language Processing (NLP), but their size creates computational bottlenecks. We introduce a novel approach to create accurate, sparse foundational versions of performant LLMs that achieve full accuracy recovery for fine-tuning tasks at up to 70% sparsity. We achieve this for the LLaMA-2 7B model by combining the SparseGPT one-shot pruning method and sparse pretraining of those models on a subset of the SlimPajama dataset mixed with a Python subset of The Stack dataset. We exhibit training acceleration due to sparsity on Cerebras CS-3 chips that closely matches theoretical scaling. In addition, we establish inference acceleration of up to 3x on CPUs by utilizing Neural Magic's DeepSparse engine and 1.7x on GPUs through Neural Magic's nm-vllm engine. The above gains are realized via sparsity alone, thus enabling further gains through additional use of quantization. Specifically, we show a total speedup on CPUs for sparse-quantized LLaMA models of up to 8.6x. We demonstrate these results across diverse, challenging tasks, including chat, instruction following, code generation, arithmetic reasoning, and summarization to prove their generality. This work paves the way for rapidly creating smaller and faster LLMs without sacrificing accuracy.
5/7/2024