Enhancing Inertial Hand based HAR through Joint Representation of Language, Pose and Synthetic IMUs

0

Sign in to get full access
Overview
- This paper explores ways to enhance hand-based human activity recognition (HAR) using a combination of language, pose, and synthetic inertial measurement unit (IMU) data.
- The key ideas include using multi-modal contrastive learning to jointly represent language, pose, and synthetic IMU data, and leveraging synthetic IMU data to improve HAR performance.
- The paper presents experiments demonstrating the effectiveness of this approach compared to using only real IMU data or other baselines.
Plain English Explanation
This research paper focuses on improving the accuracy of identifying human activities using data from sensors on the hands. The main approach is to combine three different types of information:
- Language: Descriptions of the activities in text form.
- Pose: Estimates of the body's position and movements.
- Synthetic IMU data: Simulated sensor data that mimics real-world inertial measurement units (IMUs), which track motion.
The researchers used a technique called "multi-modal contrastive learning" to learn a joint representation that captures the connections between these three data sources. This allows the model to leverage the complementary information they provide to better recognize the human activities.
A key innovation is the use of synthetic IMU data, which the researchers generated to supplement the limited real-world IMU data typically available. This synthetic data helped improve the model's performance on the hand-based activity recognition task.
Overall, the paper demonstrates how combining diverse modalities like language, pose, and simulated sensor data can enhance the accuracy of human activity recognition systems, particularly for hand-based interactions.
Technical Explanation
The paper presents a approach for improving hand-based human activity recognition (HAR) by jointly representing language, pose, and synthetic IMU data.
The key technical components are:
-
Multi-modal Contrastive Learning: The researchers use contrastive learning to learn a joint representation that captures the relationships between the language descriptions, 3D body pose estimates, and synthetic IMU data. This allows the model to leverage the complementary information provided by these different modalities.
-
Synthetic IMU Data Generation: To overcome the limited availability of real-world IMU data, the researchers generate synthetic IMU data using a physics-based simulation approach. This simulated data is used alongside the real IMU data to train the model.
-
Hand-based HAR Evaluation: The researchers evaluate their approach on hand-based human activity recognition tasks, demonstrating improved performance compared to using only real IMU data or other baselines. The tasks involve recognizing activities like writing, opening a bottle, and playing with a toy.
The experiments show that the joint representation learning and use of synthetic IMU data lead to significant boosts in HAR accuracy, highlighting the potential of this multi-modal approach for enhancing inertial sensor-based activity recognition, particularly for hand-centric interactions.
Critical Analysis
The paper presents a well-designed and thorough investigation into improving hand-based human activity recognition using a combination of language, pose, and synthetic IMU data. The key strengths of the research include:
- The use of multi-modal contrastive learning to capture the relationships between the different data sources, which is a promising approach for leveraging complementary information.
- The generation of synthetic IMU data to supplement the limited real-world data, which has been shown to be effective in other domains as well.
- The comprehensive evaluation on hand-based HAR tasks, which provides a clear demonstration of the practical benefits of the proposed approach.
However, the paper also acknowledges some limitations and areas for future work:
- The simulated IMU data may not fully capture all the nuances of real-world sensor data, so further refinements to the simulation model could be explored.
- The approach relies on having access to 3D pose estimates, which may not always be available in real-world scenarios. Investigating alternative ways to incorporate body movement information would be valuable.
- While the paper focuses on hand-based activities, the techniques could potentially be extended to whole-body activity recognition as well, which could broaden the applicability of the research.
Overall, this paper presents a promising direction for enhancing inertial sensor-based human activity recognition by leveraging multimodal data and synthetic training samples. The insights and techniques developed here could have important implications for wearable computing, human-computer interaction, and other areas where accurate activity recognition is crucial.
Conclusion
This research paper explores a novel approach to improving hand-based human activity recognition (HAR) by jointly representing language, 3D pose, and synthetic inertial measurement unit (IMU) data. The key contributions include:
- Using multi-modal contrastive learning to capture the relationships between these diverse data sources and learn a joint representation that leverages their complementary information.
- Generating synthetic IMU data to supplement the limited real-world sensor data and enhance the model's performance.
- Demonstrating the effectiveness of this approach through comprehensive evaluations on hand-based HAR tasks, outperforming baselines that use only real IMU data.
The insights and techniques developed in this paper have the potential to significantly improve the accuracy and robustness of inertial sensor-based activity recognition systems, particularly for hand-centric interactions. This could have important implications for a wide range of applications, from wearable computing to human-computer interaction, where reliable activity recognition is crucial.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Enhancing Inertial Hand based HAR through Joint Representation of Language, Pose and Synthetic IMUs
Vitor Fortes Rey, Lala Shakti Swarup Ray, Xia Qingxin, Kaishun Wu, Paul Lukowicz
Due to the scarcity of labeled sensor data in HAR, prior research has turned to video data to synthesize Inertial Measurement Units (IMU) data, capitalizing on its rich activity annotations. However, generating IMU data from videos presents challenges for HAR in real-world settings, attributed to the poor quality of synthetic IMU data and its limited efficacy in subtle, fine-grained motions. In this paper, we propose Multi$^3$Net, our novel multi-modal, multitask, and contrastive-based framework approach to address the issue of limited data. Our pretraining procedure uses videos from online repositories, aiming to learn joint representations of text, pose, and IMU simultaneously. By employing video data and contrastive learning, our method seeks to enhance wearable HAR performance, especially in recognizing subtle activities.Our experimental findings validate the effectiveness of our approach in improving HAR performance with IMU data. We demonstrate that models trained with synthetic IMU data generated from videos using our method surpass existing approaches in recognizing fine-grained activities.
Read more7/30/2024
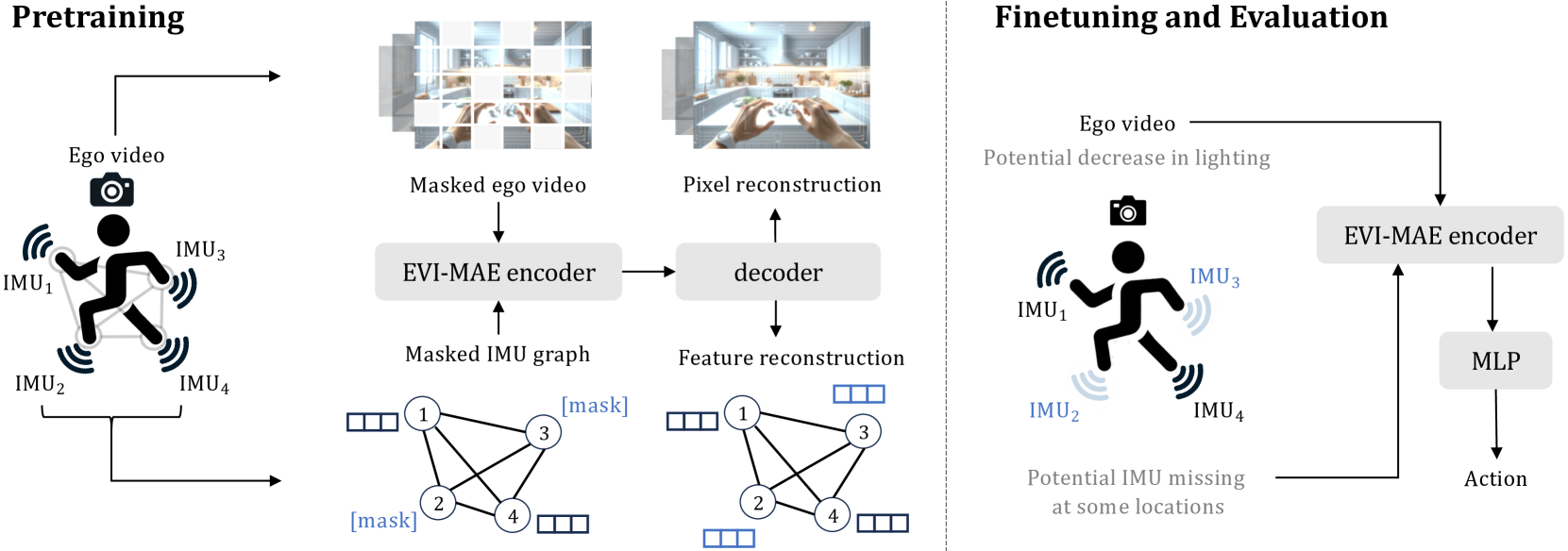
0
Masked Video and Body-worn IMU Autoencoder for Egocentric Action Recognition
Mingfang Zhang, Yifei Huang, Ruicong Liu, Yoichi Sato
Compared with visual signals, Inertial Measurement Units (IMUs) placed on human limbs can capture accurate motion signals while being robust to lighting variation and occlusion. While these characteristics are intuitively valuable to help egocentric action recognition, the potential of IMUs remains under-explored. In this work, we present a novel method for action recognition that integrates motion data from body-worn IMUs with egocentric video. Due to the scarcity of labeled multimodal data, we design an MAE-based self-supervised pretraining method, obtaining strong multi-modal representations via modeling the natural correlation between visual and motion signals. To model the complex relation of multiple IMU devices placed across the body, we exploit the collaborative dynamics in multiple IMU devices and propose to embed the relative motion features of human joints into a graph structure. Experiments show our method can achieve state-of-the-art performance on multiple public datasets. The effectiveness of our MAE-based pretraining and graph-based IMU modeling are further validated by experiments in more challenging scenarios, including partially missing IMU devices and video quality corruption, promoting more flexible usages in the real world.
Read more7/10/2024

0
Fusion and Cross-Modal Transfer for Zero-Shot Human Action Recognition
Abhi Kamboj, Anh Duy Nguyen, Minh Do
Despite living in a multi-sensory world, most AI models are limited to textual and visual interpretations of human motion and behavior. Inertial measurement units (IMUs) provide a salient signal to understand human motion; however, they are challenging to use due to their uninterpretability and scarcity of their data. We investigate a method to transfer knowledge between visual and inertial modalities using the structure of an informative joint representation space designed for human action recognition (HAR). We apply the resulting Fusion and Cross-modal Transfer (FACT) method to a novel setup, where the model does not have access to labeled IMU data during training and is able to perform HAR with only IMU data during testing. Extensive experiments on a wide range of RGB-IMU datasets demonstrate that FACT significantly outperforms existing methods in zero-shot cross-modal transfer.
Read more7/25/2024

0
Sensor Data Augmentation from Skeleton Pose Sequences for Improving Human Activity Recognition
Parham Zolfaghari, Vitor Fortes Rey, Lala Ray, Hyun Kim, Sungho Suh, Paul Lukowicz
The proliferation of deep learning has significantly advanced various fields, yet Human Activity Recognition (HAR) has not fully capitalized on these developments, primarily due to the scarcity of labeled datasets. Despite the integration of advanced Inertial Measurement Units (IMUs) in ubiquitous wearable devices like smartwatches and fitness trackers, which offer self-labeled activity data from users, the volume of labeled data remains insufficient compared to domains where deep learning has achieved remarkable success. Addressing this gap, in this paper, we propose a novel approach to improve wearable sensor-based HAR by introducing a pose-to-sensor network model that generates sensor data directly from 3D skeleton pose sequences. our method simultaneously trains the pose-to-sensor network and a human activity classifier, optimizing both data reconstruction and activity recognition. Our contributions include the integration of simultaneous training, direct pose-to-sensor generation, and a comprehensive evaluation on the MM-Fit dataset. Experimental results demonstrate the superiority of our framework with significant performance improvements over baseline methods.
Read more6/26/2024