MULAN: A Multi Layer Annotated Dataset for Controllable Text-to-Image Generation

0

Sign in to get full access
Overview
- This paper presents MULAN, a new dataset for controllable text-to-image generation.
- MULAN provides multi-layer annotations for images, including object segmentation, scene graphs, and text descriptions.
- The authors demonstrate how this dataset can be used to improve the controllability and interpretability of text-to-image models.
Plain English Explanation
MULAN is a new dataset that could help make AI systems that generate images from text descriptions more powerful and easier to understand. Typically, these AI systems work like a black box - you give them a text description, and they spit out an image, but it's hard to know exactly how they did it.
The MULAN dataset aims to change that by providing extra information about the images, such as what objects are in the scene, how they're related to each other, and detailed text descriptions. This gives researchers more tools to understand and control how the AI system generates the images.
For example, if you ask the system to generate an image of "a person riding a bike in a park," the MULAN dataset could tell the system information like: "there is a person in the center of the image, they are sitting on a blue bicycle, and there are trees and grass in the background." This extra context can help the system create images that better match the text description.
Overall, the MULAN dataset is an important step towards making text-to-image AI systems more transparent and controllable, which could lead to better and more reliable image generation in the future.
Technical Explanation
The key contributions of this paper are:
- The MULAN dataset, which provides multi-layer annotations for over 30,000 images. This includes object segmentation, scene graphs, and text descriptions.
- Experiments demonstrating how the MULAN dataset can be used to improve the controllability and interpretability of text-to-image generation models.
The authors first describe their pipeline for annotating images with object segmentation, scene graphs, and text descriptions. This involves using a combination of automated tools and human annotators to label the various elements of each image.
They then show how this rich set of annotations can be leveraged to train text-to-image models that are more controllable and interpretable. For example, they demonstrate how providing the model with the scene graph information during generation leads to images that better match the given text prompt.
Additionally, the authors present techniques for visualizing the internal representations of the text-to-image model, allowing for better understanding of how it is translating the text into visual outputs.
Critical Analysis
The MULAN dataset and the associated techniques presented in this paper represent an important advance in the field of text-to-image generation. By providing richer annotations and tools for interpreting the models, the authors enable greater transparency and control over the image generation process.
That said, the dataset is still relatively small (30,000 images) compared to some other popular image datasets. Additionally, the annotation process is labor-intensive, which may limit the scalability of the approach.
The authors also acknowledge that their current techniques for visualizing the model internals are still somewhat limited. Further research is needed to develop more comprehensive interpretability tools.
Overall, though, this work is a valuable contribution that pushes the field of text-to-image generation towards more controllable and trustworthy systems. The MULAN dataset and the associated techniques provide a strong foundation for future research in this area.
Conclusion
The MULAN dataset and the techniques presented in this paper represent an important step forward in making text-to-image generation systems more transparent and controllable. By providing rich multi-layer annotations for images, the authors enable researchers to better understand how these models work and how to steer them towards generating images that more closely match the given text prompts.
This work has significant implications for a wide range of applications, from artistic image generation to educational tools and beyond. As text-to-image systems become more powerful and ubiquitous, it will be crucial to have the kind of interpretability and control that the MULAN dataset and associated techniques provide.
Overall, this research is a valuable contribution that lays the groundwork for a future where text-to-image AI systems are more reliable, trustworthy, and aligned with human needs and preferences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MULAN: A Multi Layer Annotated Dataset for Controllable Text-to-Image Generation
Petru-Daniel Tudosiu, Yongxin Yang, Shifeng Zhang, Fei Chen, Steven McDonagh, Gerasimos Lampouras, Ignacio Iacobacci, Sarah Parisot
Text-to-image generation has achieved astonishing results, yet precise spatial controllability and prompt fidelity remain highly challenging. This limitation is typically addressed through cumbersome prompt engineering, scene layout conditioning, or image editing techniques which often require hand drawn masks. Nonetheless, pre-existing works struggle to take advantage of the natural instance-level compositionality of scenes due to the typically flat nature of rasterized RGB output images. Towards adressing this challenge, we introduce MuLAn: a novel dataset comprising over 44K MUlti-Layer ANnotations of RGB images as multilayer, instance-wise RGBA decompositions, and over 100K instance images. To build MuLAn, we developed a training free pipeline which decomposes a monocular RGB image into a stack of RGBA layers comprising of background and isolated instances. We achieve this through the use of pretrained general-purpose models, and by developing three modules: image decomposition for instance discovery and extraction, instance completion to reconstruct occluded areas, and image re-assembly. We use our pipeline to create MuLAn-COCO and MuLAn-LAION datasets, which contain a variety of image decompositions in terms of style, composition and complexity. With MuLAn, we provide the first photorealistic resource providing instance decomposition and occlusion information for high quality images, opening up new avenues for text-to-image generative AI research. With this, we aim to encourage the development of novel generation and editing technology, in particular layer-wise solutions. MuLAn data resources are available at https://MuLAn-dataset.github.io/.
Read more4/4/2024
0
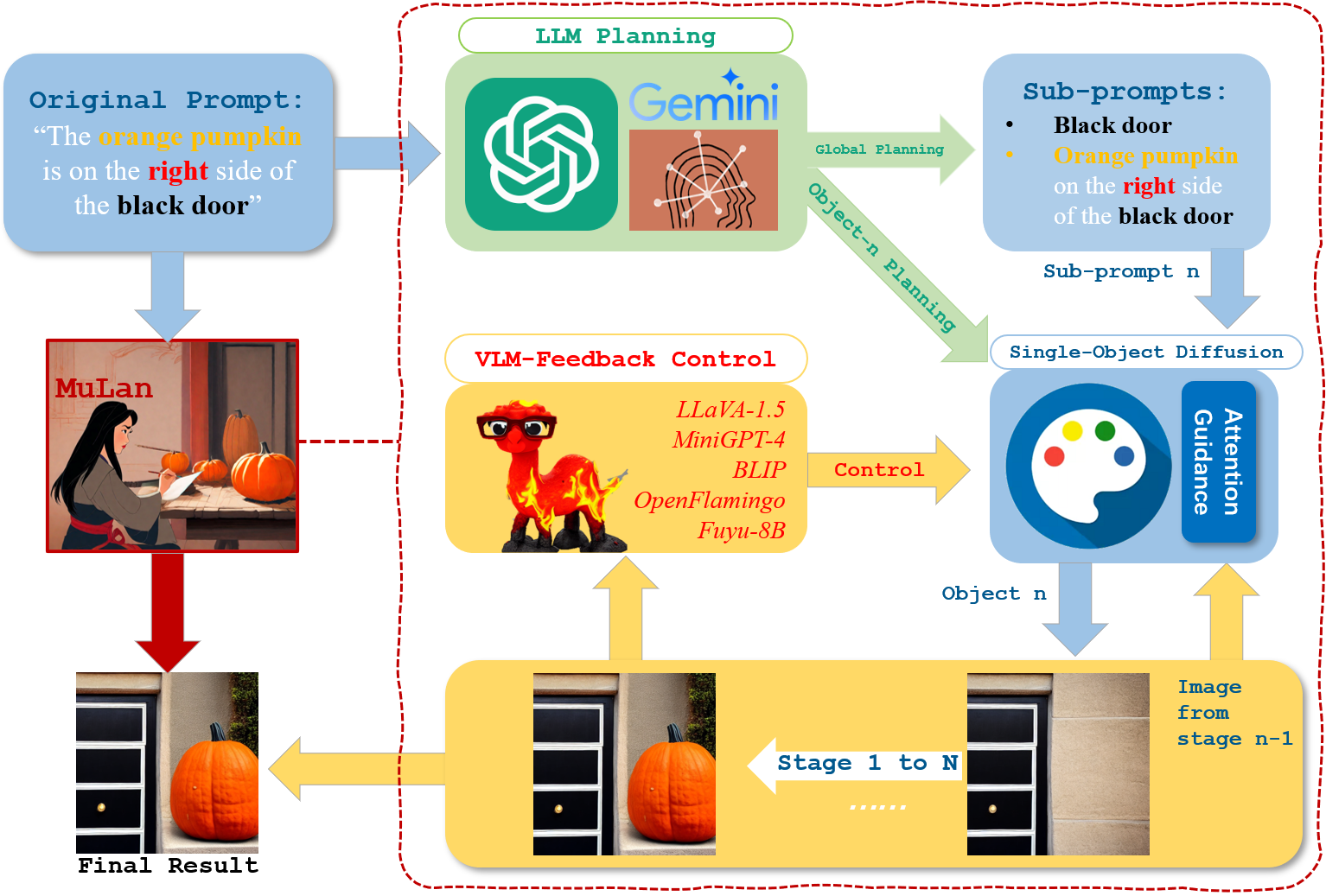
MuLan: Multimodal-LLM Agent for Progressive and Interactive Multi-Object Diffusion
Sen Li, Ruochen Wang, Cho-Jui Hsieh, Minhao Cheng, Tianyi Zhou
Existing text-to-image models still struggle to generate images of multiple objects, especially in handling their spatial positions, relative sizes, overlapping, and attribute bindings. To efficiently address these challenges, we develop a training-free Multimodal-LLM agent (MuLan), as a human painter, that can progressively generate multi-object with intricate planning and feedback control. MuLan harnesses a large language model (LLM) to decompose a prompt to a sequence of sub-tasks, each generating only one object by stable diffusion, conditioned on previously generated objects. Unlike existing LLM-grounded methods, MuLan only produces a high-level plan at the beginning while the exact size and location of each object are determined upon each sub-task by an LLM and attention guidance. Moreover, MuLan adopts a vision-language model (VLM) to provide feedback to the image generated in each sub-task and control the diffusion model to re-generate the image if it violates the original prompt. Hence, each model in every step of MuLan only needs to address an easy sub-task it is specialized for. The multi-step process also allows human users to monitor the generation process and make preferred changes at any intermediate step via text prompts, thereby improving the human-AI collaboration experience. We collect 200 prompts containing multi-objects with spatial relationships and attribute bindings from different benchmarks to evaluate MuLan. The results demonstrate the superiority of MuLan in generating multiple objects over baselines and its creativity when collaborating with human users. The code is available at https://github.com/measure-infinity/mulan-code.
Read more5/27/2024

0
MUMU: Bootstrapping Multimodal Image Generation from Text-to-Image Data
William Berman, Alexander Peysakhovich
We train a model to generate images from multimodal prompts of interleaved text and images such as a man and his dog in an animated style. We bootstrap a multimodal dataset by extracting semantically meaningful image crops corresponding to words in the image captions of synthetically generated and publicly available text-image data. Our model, MUMU, is composed of a vision-language model encoder with a diffusion decoder and is trained on a single 8xH100 GPU node. Despite being only trained on crops from the same image, MUMU learns to compose inputs from different images into a coherent output. For example, an input of a realistic person and a cartoon will output the same person in the cartoon style, and an input of a standing subject and a scooter will output the subject riding the scooter. As a result, our model generalizes to tasks such as style transfer and character consistency. Our results show the promise of using multimodal models as general purpose controllers for image generation.
Read more9/14/2024

0
TRINS: Towards Multimodal Language Models that Can Read
Ruiyi Zhang, Yanzhe Zhang, Jian Chen, Yufan Zhou, Jiuxiang Gu, Changyou Chen, Tong Sun
Large multimodal language models have shown remarkable proficiency in understanding and editing images. However, a majority of these visually-tuned models struggle to comprehend the textual content embedded in images, primarily due to the limitation of training data. In this work, we introduce TRINS: a Text-Rich image INStruction dataset, with the objective of enhancing the reading ability of the multimodal large language model. TRINS is built upon LAION using hybrid data annotation strategies that include machine-assisted and human-assisted annotation processes. It contains 39,153 text-rich images, captions, and 102,437 questions. Specifically, we show that the number of words per annotation in TRINS is significantly longer than that of related datasets, providing new challenges. Furthermore, we introduce a simple and effective architecture, called a Language-vision Reading Assistant (LaRA), which is good at understanding textual content within images. LaRA outperforms existing state-of-the-art multimodal large language models on the TRINS dataset, as well as other classical benchmarks. Lastly, we conducted a comprehensive evaluation with TRINS on various text-rich image understanding and generation tasks, demonstrating its effectiveness.
Read more6/12/2024