MuLan: Multimodal-LLM Agent for Progressive and Interactive Multi-Object Diffusion

0
Sign in to get full access
Overview
- This paper introduces MuLan, a Multimodal-LLM (Large Language Model) Agent for Progressive Multi-Object Diffusion.
- MuLan combines a large language model with a diffusion-based image generation model to enable interactive, iterative refinement of generated images.
- The model can generate and refine images containing multiple objects, with the ability to add, remove, or modify specific objects based on textual prompts.
Plain English Explanation
MuLan is a new AI system that can create and refine images in an interactive, step-by-step way. It combines a powerful language model with a diffusion-based image generation model, allowing users to describe what they want to see in an image and then refine and modify the image iteratively.
Unlike traditional image generation models that produce a single final image, MuLan lets users add, remove, or change specific objects in the image based on text prompts. This makes it easier to create complex scenes with multiple elements, as users can focus on improving specific parts of the image rather than starting from scratch.
The key innovation in MuLan is its ability to understand and act on natural language instructions to progressively improve the generated images. This allows for a more intuitive and collaborative image creation process, where the user and the AI system work together to bring the desired image to life.
Technical Explanation
The MuLan model consists of a large language model and a diffusion-based image generation model. The language model is used to understand textual prompts and generate natural language descriptions of the desired image. The diffusion model is then used to actually generate and refine the image based on these descriptions.
MuLan uses a novel "progressive multi-object diffusion" approach, where the model can add, remove, or modify specific objects in the image based on the user's text prompts. This is achieved by conditioning the diffusion process on both the initial image and the textual prompt, allowing the model to selectively refine parts of the image.
The authors evaluate MuLan on several benchmarks for multi-object image generation and text-guided image editing, demonstrating its ability to outperform previous state-of-the-art approaches. The model is shown to generate high-quality images with complex, controllable content.
Critical Analysis
The MuLan paper presents an impressive and innovative approach to interactive image generation. By combining powerful language understanding with diffusion-based image generation, the model enables a more natural and intuitive image creation process.
One potential limitation of the approach is the computational cost of the iterative refinement process, as each modification to the image may require running the diffusion model multiple times. The authors do not provide detailed information on the runtime or resource requirements of the system.
Additionally, the paper does not discuss the potential biases or limitations of the language model, which could lead to the generation of images with problematic content or stereotypes. Further research is needed to understand and mitigate these issues.
Overall, MuLan represents a significant advancement in the field of AI-assisted image creation, and the authors' progressive multi-object diffusion approach is a promising direction for future research in this area.
Conclusion
The MuLan paper introduces a novel Multimodal-LLM Agent for Progressive Multi-Object Diffusion, which combines a large language model and a diffusion-based image generation model to enable interactive, iterative refinement of generated images.
The key innovation of MuLan is its ability to understand and act on natural language instructions to selectively add, remove, or modify specific objects in the image. This makes the image creation process more intuitive and collaborative, where the user and the AI system work together to bring the desired image to life.
The authors demonstrate the effectiveness of MuLan on several benchmarks and show its ability to generate high-quality images with complex, controllable content. While the approach has some potential limitations, the MuLan paper represents a significant advancement in the field of AI-assisted image creation and opens up new possibilities for the future of this technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MuLan: Multimodal-LLM Agent for Progressive and Interactive Multi-Object Diffusion
Sen Li, Ruochen Wang, Cho-Jui Hsieh, Minhao Cheng, Tianyi Zhou
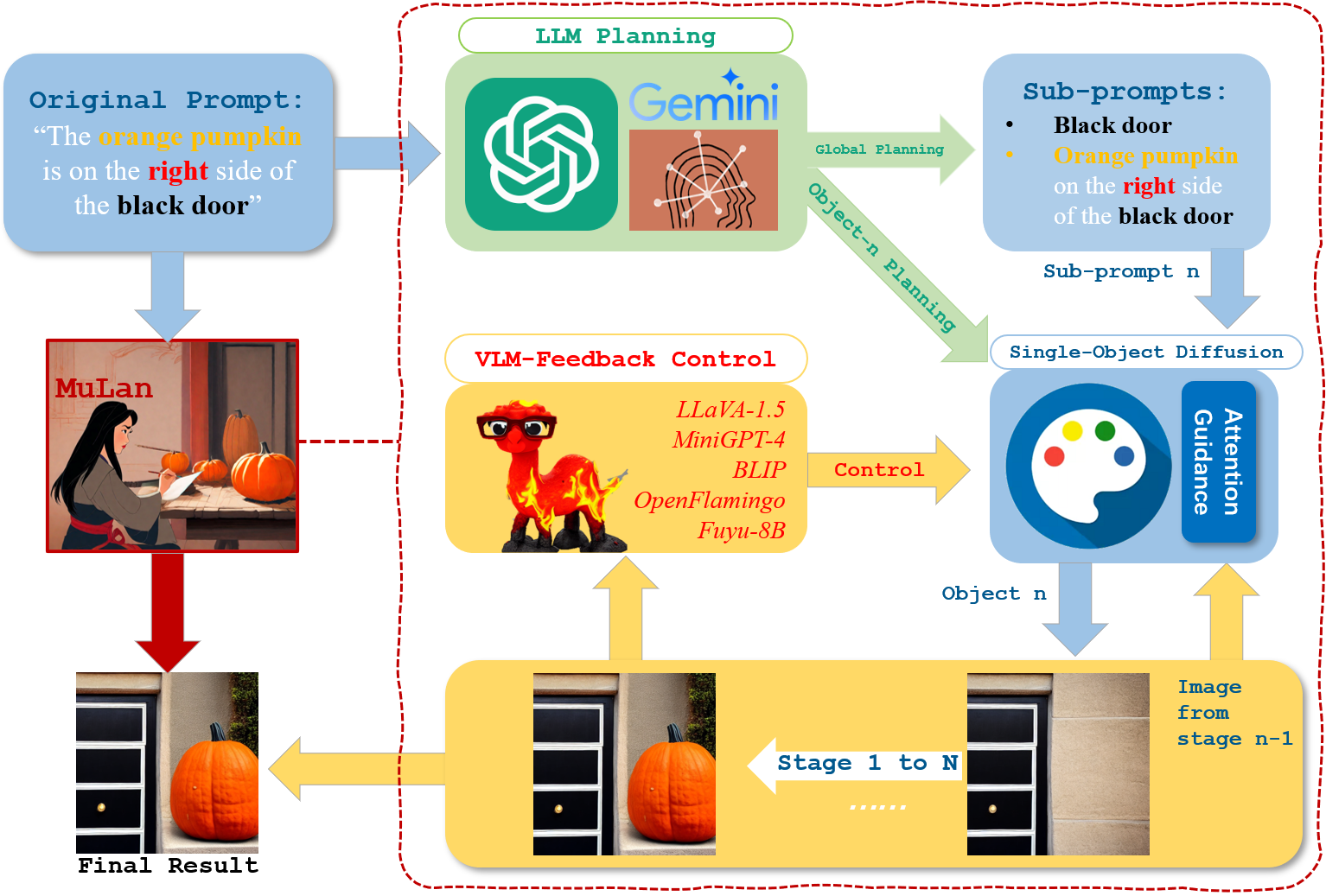
Existing text-to-image models still struggle to generate images of multiple objects, especially in handling their spatial positions, relative sizes, overlapping, and attribute bindings. To efficiently address these challenges, we develop a training-free Multimodal-LLM agent (MuLan), as a human painter, that can progressively generate multi-object with intricate planning and feedback control. MuLan harnesses a large language model (LLM) to decompose a prompt to a sequence of sub-tasks, each generating only one object by stable diffusion, conditioned on previously generated objects. Unlike existing LLM-grounded methods, MuLan only produces a high-level plan at the beginning while the exact size and location of each object are determined upon each sub-task by an LLM and attention guidance. Moreover, MuLan adopts a vision-language model (VLM) to provide feedback to the image generated in each sub-task and control the diffusion model to re-generate the image if it violates the original prompt. Hence, each model in every step of MuLan only needs to address an easy sub-task it is specialized for. The multi-step process also allows human users to monitor the generation process and make preferred changes at any intermediate step via text prompts, thereby improving the human-AI collaboration experience. We collect 200 prompts containing multi-objects with spatial relationships and attribute bindings from different benchmarks to evaluate MuLan. The results demonstrate the superiority of MuLan in generating multiple objects over baselines and its creativity when collaborating with human users. The code is available at https://github.com/measure-infinity/mulan-code.
Read more5/27/2024

0
GenArtist: Multimodal LLM as an Agent for Unified Image Generation and Editing
Zhenyu Wang, Aoxue Li, Zhenguo Li, Xihui Liu
Despite the success achieved by existing image generation and editing methods, current models still struggle with complex problems including intricate text prompts, and the absence of verification and self-correction mechanisms makes the generated images unreliable. Meanwhile, a single model tends to specialize in particular tasks and possess the corresponding capabilities, making it inadequate for fulfilling all user requirements. We propose GenArtist, a unified image generation and editing system, coordinated by a multimodal large language model (MLLM) agent. We integrate a comprehensive range of existing models into the tool library and utilize the agent for tool selection and execution. For a complex problem, the MLLM agent decomposes it into simpler sub-problems and constructs a tree structure to systematically plan the procedure of generation, editing, and self-correction with step-by-step verification. By automatically generating missing position-related inputs and incorporating position information, the appropriate tool can be effectively employed to address each sub-problem. Experiments demonstrate that GenArtist can perform various generation and editing tasks, achieving state-of-the-art performance and surpassing existing models such as SDXL and DALL-E 3, as can be seen in Fig. 1. Project page is https://zhenyuw16.github.io/GenArtist_page.
Read more7/9/2024

0
MULAN: A Multi Layer Annotated Dataset for Controllable Text-to-Image Generation
Petru-Daniel Tudosiu, Yongxin Yang, Shifeng Zhang, Fei Chen, Steven McDonagh, Gerasimos Lampouras, Ignacio Iacobacci, Sarah Parisot
Text-to-image generation has achieved astonishing results, yet precise spatial controllability and prompt fidelity remain highly challenging. This limitation is typically addressed through cumbersome prompt engineering, scene layout conditioning, or image editing techniques which often require hand drawn masks. Nonetheless, pre-existing works struggle to take advantage of the natural instance-level compositionality of scenes due to the typically flat nature of rasterized RGB output images. Towards adressing this challenge, we introduce MuLAn: a novel dataset comprising over 44K MUlti-Layer ANnotations of RGB images as multilayer, instance-wise RGBA decompositions, and over 100K instance images. To build MuLAn, we developed a training free pipeline which decomposes a monocular RGB image into a stack of RGBA layers comprising of background and isolated instances. We achieve this through the use of pretrained general-purpose models, and by developing three modules: image decomposition for instance discovery and extraction, instance completion to reconstruct occluded areas, and image re-assembly. We use our pipeline to create MuLAn-COCO and MuLAn-LAION datasets, which contain a variety of image decompositions in terms of style, composition and complexity. With MuLAn, we provide the first photorealistic resource providing instance decomposition and occlusion information for high quality images, opening up new avenues for text-to-image generative AI research. With this, we aim to encourage the development of novel generation and editing technology, in particular layer-wise solutions. MuLAn data resources are available at https://MuLAn-dataset.github.io/.
Read more4/4/2024
🖼️
0
MoMA: Multimodal LLM Adapter for Fast Personalized Image Generation
Kunpeng Song, Yizhe Zhu, Bingchen Liu, Qing Yan, Ahmed Elgammal, Xiao Yang
In this paper, we present MoMA: an open-vocabulary, training-free personalized image model that boasts flexible zero-shot capabilities. As foundational text-to-image models rapidly evolve, the demand for robust image-to-image translation grows. Addressing this need, MoMA specializes in subject-driven personalized image generation. Utilizing an open-source, Multimodal Large Language Model (MLLM), we train MoMA to serve a dual role as both a feature extractor and a generator. This approach effectively synergizes reference image and text prompt information to produce valuable image features, facilitating an image diffusion model. To better leverage the generated features, we further introduce a novel self-attention shortcut method that efficiently transfers image features to an image diffusion model, improving the resemblance of the target object in generated images. Remarkably, as a tuning-free plug-and-play module, our model requires only a single reference image and outperforms existing methods in generating images with high detail fidelity, enhanced identity-preservation and prompt faithfulness. Our work is open-source, thereby providing universal access to these advancements.
Read more4/9/2024