Multi-Agent Reinforcement Learning for Multi-Cell Spectrum and Power Allocation

0

Sign in to get full access
Overview
- This paper proposes a scalable multi-agent reinforcement learning (MARL) solution for scheduling in wireless networks with conflicting transmission links.
- The key ideas are:
- Modeling the network as a decentralized partially observable Markov decision process (Dec-POMDP).
- Using recurrent neural networks to handle dynamic network conditions.
- Developing a distributed learning algorithm that converges to a near-optimal scheduling policy.
Plain English Explanation
The paper tackles the problem of scheduling transmissions in wireless networks where different links may conflict with each other and cannot transmit at the same time. To solve this, the researchers model the network as a decentralized partially observable Markov decision process, which allows each node to make decisions based on limited local information.
They then use recurrent neural networks to help the nodes adapt their scheduling decisions to changing network conditions over time. Finally, they develop a distributed learning algorithm that allows the nodes to cooperatively converge to a near-optimal scheduling policy without requiring a centralized controller.
The key advantage of this approach is that it can scale to large, dynamic wireless networks where a centralized solution would be impractical. By having the individual nodes learn and adapt their behavior through reinforcement learning, the system can respond effectively to changes in the network without the need for constant oversight.
Technical Explanation
The paper models the wireless network scheduling problem as a decentralized partially observable Markov decision process (Dec-POMDP). In this formulation, each node in the network is an agent that must decide whether to transmit or remain idle in each time slot, based only on its local observations. The goal is to maximize the overall throughput of the network while avoiding conflicts between transmitting nodes.
To handle the dynamic nature of wireless networks, the authors propose using recurrent neural networks to represent the scheduling policy. This allows the agents to maintain an internal state that encodes information about past observations and actions, enabling them to adapt their decisions over time.
The learning algorithm developed in the paper is a distributed reinforcement learning approach, where each agent updates its policy independently based on its own experiences. The agents learn to coordinate their actions through a reward signal that encourages them to maximize the overall network throughput while avoiding conflicts.
The authors demonstrate the effectiveness of their approach through simulations, showing that it can achieve near-optimal performance in a variety of network scenarios, including those with dynamic traffic patterns and node failures.
Critical Analysis
The paper presents a compelling solution for scheduling in wireless networks with conflicting links, but there are a few potential limitations and areas for further research:
-
The Dec-POMDP formulation assumes that each node has only partial information about the network state, which may not always be the case in practical scenarios. Exploring ways to incorporate more global information, either through additional sensors or communication between nodes, could potentially improve the performance of the system.
-
The use of recurrent neural networks adds complexity to the agent's decision-making process, which could impact the convergence speed and stability of the learning algorithm. Investigating alternative neural network architectures or reinforcement learning techniques that can handle dynamic environments more efficiently could be a fruitful area for future research.
-
The paper focuses on maximizing overall network throughput, but other performance metrics, such as fairness or latency, may also be important in certain applications. Extending the framework to consider these additional objectives could make the solution more broadly applicable.
-
The authors did not explore the impact of varying network sizes or the scalability of their approach to very large-scale deployments. Evaluating the performance and computational requirements of the algorithm in such scenarios would be an important next step.
Overall, the paper presents a promising approach to a challenging problem in wireless networks, and the insights and techniques developed could be valuable for a range of applications involving multi-agent decision-making in dynamic environments.
Conclusion
This paper introduces a scalable multi-agent reinforcement learning solution for scheduling transmissions in wireless networks with conflicting links. By modeling the problem as a decentralized partially observable Markov decision process and using recurrent neural networks to handle dynamic network conditions, the authors develop a distributed learning algorithm that can converge to near-optimal scheduling policies.
The key advantages of this approach are its scalability and adaptability, which make it well-suited for managing large, complex wireless networks where centralized control may be impractical. While the paper identifies a few areas for further research, the proposed solution represents an important contribution to the field of multi-agent reinforcement learning and its applications in wireless communication systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multi-Agent Reinforcement Learning for Multi-Cell Spectrum and Power Allocation
Yiming Zhang, Dongning Guo
This paper introduces a novel approach to radio resource allocation in multi-cell wireless networks using a fully scalable multi-agent reinforcement learning (MARL) framework. A distributed method is developed where agents control individual cells and determine spectrum and power allocation based on limited local information, yet achieve quality of service (QoS) performance comparable to centralized methods using global information. The objective is to minimize packet delays across devices under stochastic arrivals and applies to both conflict graph abstractions and cellular network configurations. This is formulated as a distributed learning problem, implementing a multi-agent proximal policy optimization (MAPPO) algorithm with recurrent neural networks and queueing dynamics. This traffic-driven MARL-based solution enables decentralized training and execution, ensuring scalability to large networks. Extensive simulations demonstrate that the proposed methods achieve comparable QoS performance to genie-aided centralized algorithms with significantly less execution time. The trained policies also exhibit scalability and robustness across various network sizes and traffic conditions.
Read more9/19/2024
🏅
0
Mobility-Aware Resource Allocation for mmWave IAB Networks: A Multi-Agent Reinforcement Learning Approach
Bibo Zhang, Ilario Filippini
MmWaves have been envisioned as a promising direction to provide Gbps wireless access. However, they are susceptible to high path losses and blockages, which directional antennas can only partially mitigate. That makes mmWave networks coverage-limited, thus requiring dense deployments. Integrated access and backhaul (IAB) architectures have emerged as a cost-effective solution for network densification. Resource allocation in mmWave IAB networks must face big challenges to cope with heavy temporal dynamics, such as intermittent links caused by user mobility and blockages from moving obstacles. This makes it extremely difficult to find optimal and adaptive solutions. In this article, exploiting the distributed structure of the problem, we propose a Multi-Agent Reinforcement Learning (MARL) framework to optimize user throughput via flow routing and link scheduling in mmWave IAB networks characterized by user mobility and link outages generated by moving obstacles. The proposed approach implicitly captures the environment dynamics, coordinates the interference, and manages the buffer levels of IAB relay nodes. We design different MARL components, considering full-duplex and half-duplex IAB-nodes. In addition, we provide a communication and coordination scheme for RL agents in an online training framework, addressing the feasibility issues of practical systems. Numerical results show the effectiveness of the proposed approach.
Read more4/24/2024

0
Decentralized multi-agent reinforcement learning algorithm using a cluster-synchronized laser network
Shun Kotoku, Takatomo Mihana, Andr'e Rohm, Ryoichi Horisaki
Multi-agent reinforcement learning (MARL) studies crucial principles that are applicable to a variety of fields, including wireless networking and autonomous driving. We propose a photonic-based decision-making algorithm to address one of the most fundamental problems in MARL, called the competitive multi-armed bandit (CMAB) problem. Our numerical simulations demonstrate that chaotic oscillations and cluster synchronization of optically coupled lasers, along with our proposed decentralized coupling adjustment, efficiently balance exploration and exploitation while facilitating cooperative decision-making without explicitly sharing information among agents. Our study demonstrates how decentralized reinforcement learning can be achieved by exploiting complex physical processes controlled by simple algorithms.
Read more7/15/2024
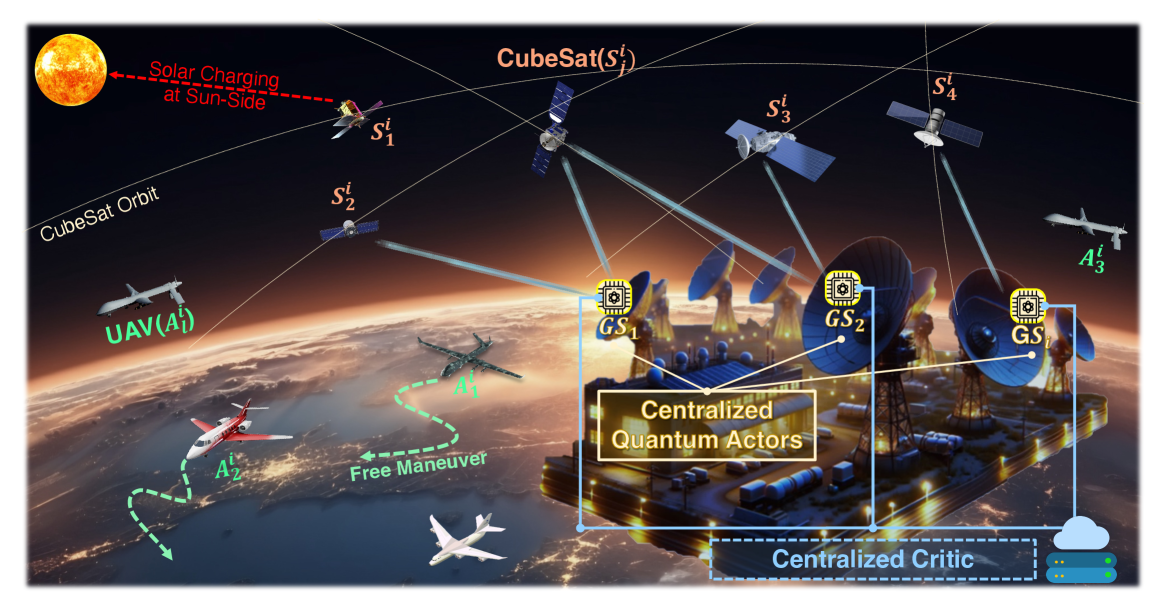
0
Quantum Multi-Agent Reinforcement Learning for Cooperative Mobile Access in Space-Air-Ground Integrated Networks
Gyu Seon Kim, Yeryeong Cho, Jaehyun Chung, Soohyun Park, Soyi Jung, Zhu Han, Joongheon Kim
Achieving global space-air-ground integrated network (SAGIN) access only with CubeSats presents significant challenges such as the access sustainability limitations in specific regions (e.g., polar regions) and the energy efficiency limitations in CubeSats. To tackle these problems, high-altitude long-endurance unmanned aerial vehicles (HALE-UAVs) can complement these CubeSat shortcomings for providing cooperatively global access sustainability and energy efficiency. However, as the number of CubeSats and HALE-UAVs, increases, the scheduling dimension of each ground station (GS) increases. As a result, each GS can fall into the curse of dimensionality, and this challenge becomes one major hurdle for efficient global access. Therefore, this paper provides a quantum multi-agent reinforcement Learning (QMARL)-based method for scheduling between GSs and CubeSats/HALE-UAVs in order to improve global access availability and energy efficiency. The main reason why the QMARL-based scheduler can be beneficial is that the algorithm facilitates a logarithmic-scale reduction in scheduling action dimensions, which is one critical feature as the number of CubeSats and HALE-UAVs expands. Additionally, individual GSs have different traffic demands depending on their locations and characteristics, thus it is essential to provide differentiated access services. The superiority of the proposed scheduler is validated through data-intensive experiments in realistic CubeSat/HALE-UAV settings.
Read more6/26/2024