A Multi-Aspect Framework for Counter Narrative Evaluation using Large Language Models

0
💬
Sign in to get full access
Overview
- Counter narratives are responses designed to refute hateful claims and calm harmful encounters.
- Previous work has proposed methods to automatically generate counter narratives, but evaluating these approaches remains a challenge.
- Existing automatic metrics for counter narrative evaluation don't align well with human judgments, as they focus on superficial comparisons instead of key aspects of counter narrative quality.
- This paper proposes a new evaluation framework that uses large language models (LLMs) to score and provide feedback on generated counter narratives based on 5 defined quality criteria.
- The LLM evaluators achieved strong alignment with human-annotated scores and outperformed alternative metrics, suggesting they could be effective multi-aspect, reference-free, and interpretable evaluators for counter narrative systems.
Plain English Explanation
When people say terrible, hateful things, it's important to have effective ways to counter and defuse those harmful messages. One approach is to create "counter narratives" - responses that refute the hateful claims and try to calm the situation down.
Previous research has looked at ways to automatically generate these counter narratives to assist human efforts. However, evaluating the quality of automatically generated counter narratives has been difficult. Existing evaluation methods tend to focus on superficial comparisons instead of really understanding what makes a good counter narrative.
This new research proposes a novel way to evaluate counter narratives. It uses powerful AI language models to score and provide feedback on generated counter narratives, based on 5 key criteria identified from guidelines by organizations that specialize in counter narratives.
The researchers found that these AI evaluators were able to provide scores and feedback that aligned very closely with how human experts judged the counter narratives. This suggests the AI could be a helpful, interpretable tool for evaluating the quality of automatically generated counter narratives, going beyond simple comparisons to really assess their effectiveness.
Developing better ways to counter hate speech and defuse harmful situations is an important social challenge. This research represents a step forward in creating AI systems that can assist in that effort, by providing robust and insightful evaluation of counter narrative approaches.
Technical Explanation
The paper proposes a novel evaluation framework for automatically generated counter narratives, which are responses designed to refute hateful claims and de-escalate harmful encounters.
Previous work has explored methods for automatically generating counter narratives to support manual interventions. However, evaluating the quality of these automatically generated counter narratives remains an underdeveloped area. Existing automatic evaluation metrics tend to rely on superficial reference comparisons, rather than incorporating key aspects of counter narrative quality as evaluation criteria.
To address these limitations, the researchers developed an evaluation framework that prompts large language models (LLMs) to provide multi-aspect scores and feedback on generated counter narrative candidates. The 5 evaluation criteria were derived from guidelines provided by counter narrative-specialized NGOs, covering aspects like factual accuracy, emotional resonance, and de-escalation potential.
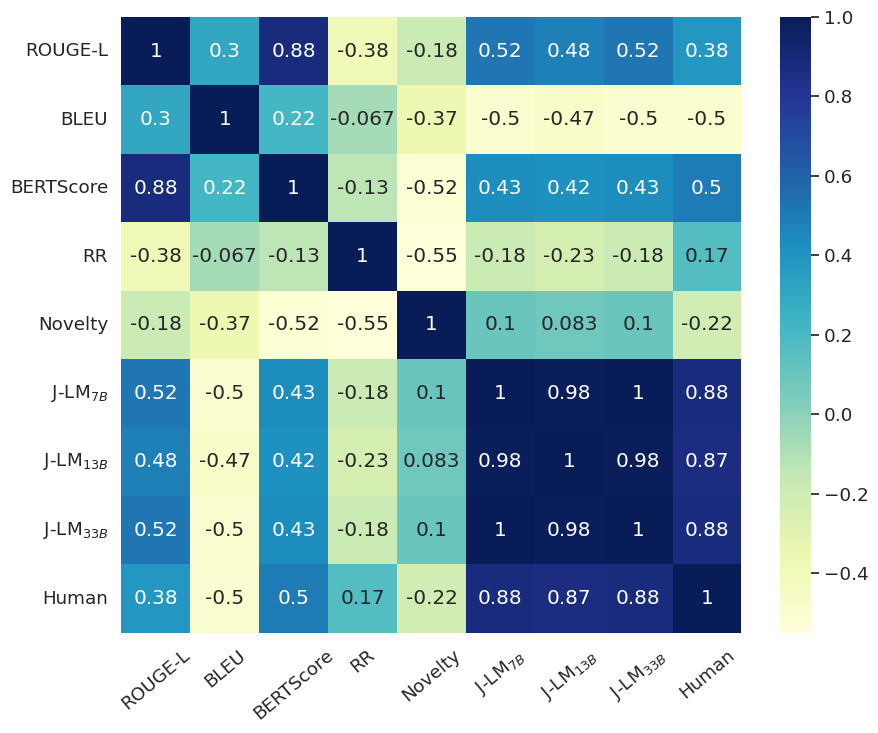
The researchers found that the LLM evaluators achieved strong alignment with human-annotated scores and feedback, outperforming alternative evaluation metrics like BLEU and METEOR. This suggests the LLM-based approach can serve as an effective, reference-free, and interpretable means of assessing counter narrative quality across multiple relevant dimensions.
Critical Analysis
The paper makes a valuable contribution by proposing a more comprehensive and human-aligned evaluation framework for automatically generated counter narratives. The use of LLMs to provide multi-aspect scores and feedback is a promising approach, as it can capture nuances that simpler metrics miss.
However, the paper does not discuss potential limitations or biases in the LLM evaluators themselves. Language models can reflect societal biases, and their assessments may not fully align with expert human judgment in all cases. Further research is needed to understand the robustness and generalizability of the LLM-based evaluation approach.
Additionally, the paper focuses on the evaluation framework but does not provide a detailed analysis of the automatically generated counter narratives themselves. It would be helpful to understand the strengths and weaknesses of the generated content, beyond just the evaluation scores.
Finally, the paper does not address the broader societal and ethical implications of developing automated systems to counter hate speech. While the goals are noble, there are complex questions around free speech, algorithmic bias, and the potential for misuse that warrant careful consideration.
Conclusion
This research represents an important step forward in creating more robust and human-aligned evaluation methods for automatically generated counter narratives - responses designed to refute hateful claims and de-escalate harmful encounters.
By leveraging large language models to provide multi-aspect scores and feedback, the proposed evaluation framework shows promise in capturing nuanced aspects of counter narrative quality beyond simple reference comparisons. The strong alignment with human expert judgments suggests this approach could be a valuable tool for assessing the effectiveness of counter narrative generation systems.
As efforts to combat hate speech and misinformation continue, developing reliable means of evaluating counter narrative approaches will be crucial. This work lays the groundwork for further research and refinement in this vital area, with the ultimate goal of empowering communities to respond effectively to the spread of harmful rhetoric.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
A Multi-Aspect Framework for Counter Narrative Evaluation using Large Language Models
Jaylen Jones, Lingbo Mo, Eric Fosler-Lussier, Huan Sun
Counter narratives - informed responses to hate speech contexts designed to refute hateful claims and de-escalate encounters - have emerged as an effective hate speech intervention strategy. While previous work has proposed automatic counter narrative generation methods to aid manual interventions, the evaluation of these approaches remains underdeveloped. Previous automatic metrics for counter narrative evaluation lack alignment with human judgment as they rely on superficial reference comparisons instead of incorporating key aspects of counter narrative quality as evaluation criteria. To address prior evaluation limitations, we propose a novel evaluation framework prompting LLMs to provide scores and feedback for generated counter narrative candidates using 5 defined aspects derived from guidelines from counter narrative specialized NGOs. We found that LLM evaluators achieve strong alignment to human-annotated scores and feedback and outperform alternative metrics, indicating their potential as multi-aspect, reference-free and interpretable evaluators for counter narrative evaluation.
Read more4/1/2024
0
A LLM-Based Ranking Method for the Evaluation of Automatic Counter-Narrative Generation
Irune Zubiaga, Aitor Soroa, Rodrigo Agerri
The proliferation of misinformation and harmful narratives in online discourse has underscored the critical need for effective Counter Narrative (CN) generation techniques. However, existing automatic evaluation methods often lack interpretability and fail to capture the nuanced relationship between generated CNs and human perception. Aiming to achieve a higher correlation with human judgments, this paper proposes a novel approach to asses generated CNs that consists on the use of a Large Language Model (LLM) as a evaluator. By comparing generated CNs pairwise in a tournament-style format, we establish a model ranking pipeline that achieves a correlation of $0.88$ with human preference. As an additional contribution, we leverage LLMs as zero-shot (ZS) CN generators and conduct a comparative analysis of chat, instruct, and base models, exploring their respective strengths and limitations. Through meticulous evaluation, including fine-tuning experiments, we elucidate the differences in performance and responsiveness to domain-specific data. We conclude that chat-aligned models in ZS are the best option for carrying out the task, provided they do not refuse to generate an answer due to security concerns.
Read more6/24/2024
📈
0
NLP for Counterspeech against Hate: A Survey and How-To Guide
Helena Bonaldi, Yi-Ling Chung, Gavin Abercrombie, Marco Guerini
In recent years, counterspeech has emerged as one of the most promising strategies to fight online hate. These non-escalatory responses tackle online abuse while preserving the freedom of speech of the users, and can have a tangible impact in reducing online and offline violence. Recently, there has been growing interest from the Natural Language Processing (NLP) community in addressing the challenges of analysing, collecting, classifying, and automatically generating counterspeech, to reduce the huge burden of manually producing it. In particular, researchers have taken different directions in addressing these challenges, thus providing a variety of related tasks and resources. In this paper, we provide a guide for doing research on counterspeech, by describing - with detailed examples - the steps to undertake, and providing best practices that can be learnt from the NLP studies on this topic. Finally, we discuss open challenges and future directions of counterspeech research in NLP.
Read more4/1/2024
🛸
0
Auditing Counterfire: Evaluating Advanced Counterargument Generation with Evidence and Style
Preetika Verma, Kokil Jaidka, Svetlana Churina
We audited large language models (LLMs) for their ability to create evidence-based and stylistic counter-arguments to posts from the Reddit ChangeMyView dataset. We benchmarked their rhetorical quality across a host of qualitative and quantitative metrics and then ultimately evaluated them on their persuasive abilities as compared to human counter-arguments. Our evaluation is based on Counterfire: a new dataset of 32,000 counter-arguments generated from large language models (LLMs): GPT-3.5 Turbo and Koala and their fine-tuned variants, and PaLM 2, with varying prompts for evidence use and argumentative style. GPT-3.5 Turbo ranked highest in argument quality with strong paraphrasing and style adherence, particularly in `reciprocity' style arguments. However, the stylistic counter-arguments still fall short of human persuasive standards, where people also preferred reciprocal to evidence-based rebuttals. The findings suggest that a balance between evidentiality and stylistic elements is vital to a compelling counter-argument. We close with a discussion of future research directions and implications for evaluating LLM outputs.
Read more4/23/2024