A LLM-Based Ranking Method for the Evaluation of Automatic Counter-Narrative Generation

0
Sign in to get full access
Overview
- The paper presents a new method for evaluating the quality of automatically generated counter-narratives using large language models (LLMs).
- The authors propose a ranking-based approach that compares the generated counter-narratives to a set of human-written references.
- The method aims to provide a more comprehensive and reliable evaluation of counter-narrative generation systems, going beyond traditional measures like perplexity or human evaluation.
Plain English Explanation
The paper describes a new way to assess the quality of computer-generated counter-narratives. Counter-narratives are messages that challenge and undermine harmful or false narratives, like extremist ideologies or conspiracy theories. Generating high-quality counter-narratives automatically is an important but challenging task.
The researchers developed a ranking-based method that compares the computer-generated counter-narratives to a set of human-written examples. This allows them to evaluate the generated counter-narratives more thoroughly than just looking at how "fluent" or "natural" they sound. The key idea is to see how the computer-generated counter-narratives measure up against real human-written ones in terms of factors like coherence, persuasiveness, and faithfulness to the original narrative.
The authors believe this ranking-based approach provides a more comprehensive and reliable way to evaluate counter-narrative generation systems, going beyond simpler measures like how likely the text is or how much humans like it. By benchmarking the computer-generated output against high-quality human examples, the method aims to give a better sense of how well the systems are performing.
Technical Explanation
The paper presents a new ranking-based method for evaluating automatic counter-narrative generation. The authors propose using large language models (LLMs) to rank a set of generated counter-narratives against a collection of human-written reference counter-narratives.
The key steps are:
- Collect a set of human-written counter-narratives to serve as high-quality references.
- Generate a set of candidate counter-narratives using an automatic generation system.
- Use an LLM to rank the generated candidates relative to the human references.
- Evaluate the ranking performance as a proxy for the quality of the generated counter-narratives.
This approach aims to provide a more comprehensive evaluation than traditional measures like perplexity or human evaluation. By benchmarking the generated output against high-quality human examples, the method seeks to give a better sense of how well the counter-narrative generation systems are performing.
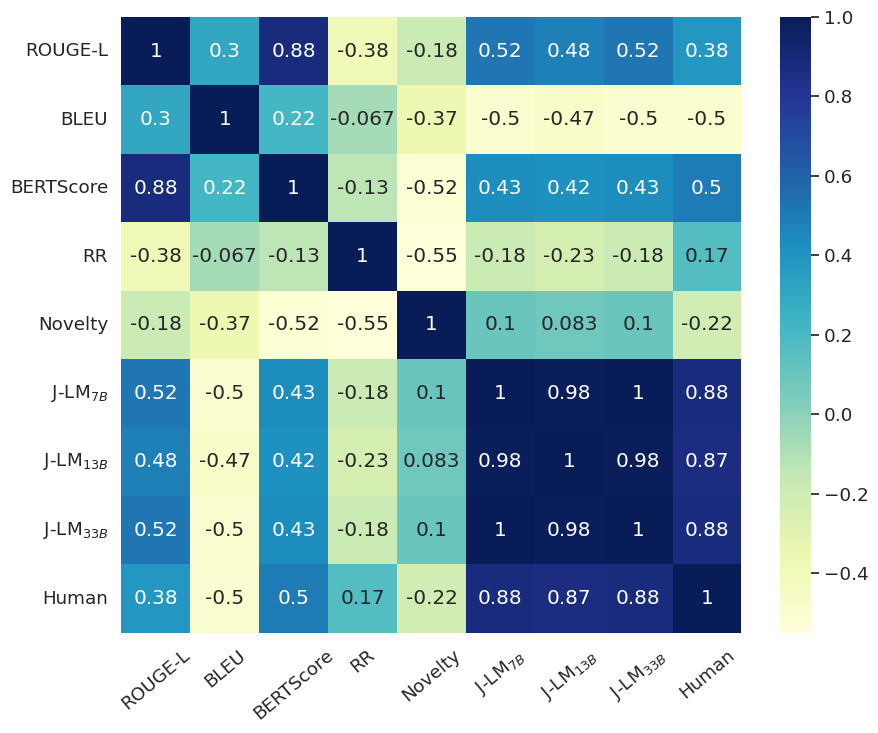
The authors conduct experiments on several datasets and generation models, including zero-shot LLM-guided counter-narrative generation and a multi-aspect framework for counter-narrative evaluation. They find that the ranking-based approach correlates well with human judgments and can differentiate between higher and lower quality counter-narratives.
Critical Analysis
The paper offers a promising new direction for evaluating counter-narrative generation systems, but it also acknowledges several limitations and areas for further research.
One key limitation is that the method relies on having a suitable set of high-quality human-written counter-narratives to use as references. Collecting and curating such a dataset can be challenging, especially for specific domains or use cases.
Additionally, the authors note that the ranking-based approach may not capture all aspects of counter-narrative quality, such as contextual appropriateness or the ability to shift beliefs. Combining this method with other evaluation techniques, like using LLMs to detect misinformation, could provide a more holistic assessment.
Further research could also explore ways to make the evaluation more granular, such as assessing different dimensions of counter-narrative quality (e.g., coherence, persuasiveness, factual accuracy) or developing methods to generate synthetic reference counter-narratives when human-written examples are scarce.
Conclusion
This paper presents a novel LLM-based ranking method for evaluating automatic counter-narrative generation. By benchmarking generated counter-narratives against high-quality human-written references, the approach aims to provide a more comprehensive and reliable assessment than traditional evaluation techniques.
The findings suggest this ranking-based method can effectively differentiate between higher and lower quality counter-narratives, and the authors believe it represents an important step forward in the field of counter-narrative evaluation. While the approach has some limitations, it opens up new avenues for further research and development in this critical area of combating harmful narratives and misinformation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A LLM-Based Ranking Method for the Evaluation of Automatic Counter-Narrative Generation
Irune Zubiaga, Aitor Soroa, Rodrigo Agerri
The proliferation of misinformation and harmful narratives in online discourse has underscored the critical need for effective Counter Narrative (CN) generation techniques. However, existing automatic evaluation methods often lack interpretability and fail to capture the nuanced relationship between generated CNs and human perception. Aiming to achieve a higher correlation with human judgments, this paper proposes a novel approach to asses generated CNs that consists on the use of a Large Language Model (LLM) as a evaluator. By comparing generated CNs pairwise in a tournament-style format, we establish a model ranking pipeline that achieves a correlation of $0.88$ with human preference. As an additional contribution, we leverage LLMs as zero-shot (ZS) CN generators and conduct a comparative analysis of chat, instruct, and base models, exploring their respective strengths and limitations. Through meticulous evaluation, including fine-tuning experiments, we elucidate the differences in performance and responsiveness to domain-specific data. We conclude that chat-aligned models in ZS are the best option for carrying out the task, provided they do not refuse to generate an answer due to security concerns.
Read more6/24/2024
💬
0
A Multi-Aspect Framework for Counter Narrative Evaluation using Large Language Models
Jaylen Jones, Lingbo Mo, Eric Fosler-Lussier, Huan Sun
Counter narratives - informed responses to hate speech contexts designed to refute hateful claims and de-escalate encounters - have emerged as an effective hate speech intervention strategy. While previous work has proposed automatic counter narrative generation methods to aid manual interventions, the evaluation of these approaches remains underdeveloped. Previous automatic metrics for counter narrative evaluation lack alignment with human judgment as they rely on superficial reference comparisons instead of incorporating key aspects of counter narrative quality as evaluation criteria. To address prior evaluation limitations, we propose a novel evaluation framework prompting LLMs to provide scores and feedback for generated counter narrative candidates using 5 defined aspects derived from guidelines from counter narrative specialized NGOs. We found that LLM evaluators achieve strong alignment to human-annotated scores and feedback and outperform alternative metrics, indicating their potential as multi-aspect, reference-free and interpretable evaluators for counter narrative evaluation.
Read more4/1/2024
🛸
0
Zero-shot LLM-guided Counterfactual Generation for Text
Amrita Bhattacharjee, Raha Moraffah, Joshua Garland, Huan Liu
Counterfactual examples are frequently used for model development and evaluation in many natural language processing (NLP) tasks. Although methods for automated counterfactual generation have been explored, such methods depend on models such as pre-trained language models that are then fine-tuned on auxiliary, often task-specific datasets. Collecting and annotating such datasets for counterfactual generation is labor intensive and therefore, infeasible in practice. Therefore, in this work, we focus on a novel problem setting: textit{zero-shot counterfactual generation}. To this end, we propose a structured way to utilize large language models (LLMs) as general purpose counterfactual example generators. We hypothesize that the instruction-following and textual understanding capabilities of recent LLMs can be effectively leveraged for generating high quality counterfactuals in a zero-shot manner, without requiring any training or fine-tuning. Through comprehensive experiments on various downstream tasks in natural language processing (NLP), we demonstrate the efficacy of LLMs as zero-shot counterfactual generators in evaluating and explaining black-box NLP models.
Read more5/9/2024

0
LLMs for Generating and Evaluating Counterfactuals: A Comprehensive Study
Van Bach Nguyen, Paul Youssef, Jorg Schlotterer, Christin Seifert
As NLP models become more complex, understanding their decisions becomes more crucial. Counterfactuals (CFs), where minimal changes to inputs flip a model's prediction, offer a way to explain these models. While Large Language Models (LLMs) have shown remarkable performance in NLP tasks, their efficacy in generating high-quality CFs remains uncertain. This work fills this gap by investigating how well LLMs generate CFs for two NLU tasks. We conduct a comprehensive comparison of several common LLMs, and evaluate their CFs, assessing both intrinsic metrics, and the impact of these CFs on data augmentation. Moreover, we analyze differences between human and LLM-generated CFs, providing insights for future research directions. Our results show that LLMs generate fluent CFs, but struggle to keep the induced changes minimal. Generating CFs for Sentiment Analysis (SA) is less challenging than NLI where LLMs show weaknesses in generating CFs that flip the original label. This also reflects on the data augmentation performance, where we observe a large gap between augmenting with human and LLMs CFs. Furthermore, we evaluate LLMs' ability to assess CFs in a mislabelled data setting, and show that they have a strong bias towards agreeing with the provided labels. GPT4 is more robust against this bias and its scores correlate well with automatic metrics. Our findings reveal several limitations and point to potential future work directions.
Read more5/3/2024