Multi-Granularity Guided Fusion-in-Decoder

0

Sign in to get full access
Overview
- The paper proposes a new model called "Multi-Granularity Guided Fusion-in-Decoder" for natural language processing tasks.
- The model aims to improve performance by fusing information at multiple levels of granularity during the decoding process.
- Key innovations include a multi-granularity encoder and a fusion-in-decoder mechanism that integrates information from different granularities.
Plain English Explanation
The paper describes a new approach to natural language processing that tries to better understand the nuances and context of language by considering it at multiple "levels of detail."
Imagine you're reading a book and trying to understand the overall story. You might look at the big picture - the main plot, characters, and themes. But you'd also pay attention to smaller details like the descriptive language, metaphors, and word choices the author uses.
Similarly, this model looks at language at different "granularities" - from the high-level semantics and structure down to the specific words and phrases used. By fusing, or combining, all this information together during the decoding process, the model can build a richer, more complete understanding of the language.
The key innovation is a multi-granularity encoder that captures information at different levels, and a fusion-in-decoder mechanism that intelligently integrates all these perspectives when generating output. This allows the model to leverage both the big picture and the fine details to improve its performance on natural language tasks.
Technical Explanation
The paper introduces a new model architecture called "Multi-Granularity Guided Fusion-in-Decoder" (MGGFD) for natural language processing. The core idea is to encode information at multiple levels of granularity and then dynamically fuse this multi-granular knowledge during the decoding process.
The MGGFD model has a multi-granularity encoder that operates at different linguistic levels, including the token, phrase, and sentence levels. This allows the model to capture both local and global contextual cues. The encoded representations are then passed to a fusion-in-decoder module, which selectively integrates the multi-granular information to inform the language generation.
Specifically, the fusion-in-decoder mechanism consists of a series of fusion layers that dynamically weight and combine the token-, phrase-, and sentence-level representations. This fusion process is guided by the current decoding state, enabling the model to adaptively select the most relevant granularities for each step of the output sequence generation.
The authors evaluate the MGGFD model on a range of natural language tasks, including machine translation, text summarization, and dialogue response generation. Experiments show that the multi-granularity fusion approach consistently outperforms strong baselines that only use a single level of granularity. The results indicate that the ability to flexibly integrate information across multiple linguistic scales is a key factor in the model's superior performance.
Critical Analysis
The paper presents a well-designed and thoroughly evaluated approach to leveraging multi-granular information for language modeling. The authors acknowledge that previous work has often relied on a single level of granularity, and demonstrate the benefits of their more comprehensive fusion strategy.
One potential limitation is that the fusion-in-decoder mechanism adds additional complexity and computational overhead to the model. The authors note that this tradeoff is worthwhile given the performance gains, but it may limit the model's applicability in certain resource-constrained settings.
Additionally, the paper does not provide a deep analysis of the types of linguistic phenomena that benefit most from the multi-granular fusion approach. Further research could investigate how the model's performance varies across different linguistic structures, genres, or domains.
Despite these minor caveats, the MGGFD model represents a promising advance in the field of natural language processing. By considering language at multiple levels of detail and intelligently combining these perspectives, the model is able to capture richer semantic and contextual information, leading to improved performance on a range of practical tasks.
Conclusion
The "Multi-Granularity Guided Fusion-in-Decoder" model presented in this paper offers a novel approach to natural language processing that goes beyond traditional single-granularity techniques. By encoding information at multiple linguistic levels and dynamically fusing this knowledge during decoding, the model is able to build a more comprehensive understanding of language.
The empirical results demonstrate the benefits of this multi-granular fusion strategy, with the MGGFD model outperforming strong baselines across several important NLP tasks. While the added complexity may limit its applicability in certain scenarios, the core ideas represent an important step forward in developing more powerful and versatile language models.
Overall, this research highlights the value of considering language at different scales of granularity, and suggests that future advances in natural language processing may come from models that can fluidly integrate insights from multiple linguistic perspectives.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multi-Granularity Guided Fusion-in-Decoder
Eunseong Choi, Hyeri Lee, Jongwuk Lee
In Open-domain Question Answering (ODQA), it is essential to discern relevant contexts as evidence and avoid spurious ones among retrieved results. The model architecture that uses concatenated multiple contexts in the decoding phase, i.e., Fusion-in-Decoder, demonstrates promising performance but generates incorrect outputs from seemingly plausible contexts. To address this problem, we propose the Multi-Granularity guided Fusion-in-Decoder (MGFiD), discerning evidence across multiple levels of granularity. Based on multi-task learning, MGFiD harmonizes passage re-ranking with sentence classification. It aggregates evident sentences into an anchor vector that instructs the decoder. Additionally, it improves decoding efficiency by reusing the results of passage re-ranking for passage pruning. Through our experiments, MGFiD outperforms existing models on the Natural Questions (NQ) and TriviaQA (TQA) datasets, highlighting the benefits of its multi-granularity solution.
Read more4/4/2024

0
FastFiD: Improve Inference Efficiency of Open Domain Question Answering via Sentence Selection
Yufei Huang, Xu Han, Maosong Sun
Open Domain Question Answering (ODQA) has been advancing rapidly in recent times, driven by significant developments in dense passage retrieval and pretrained language models. Current models typically incorporate the FiD framework, which is composed by a neural retriever alongside an encoder-decoder neural reader. In the answer generation process, the retriever will retrieve numerous passages (around 100 for instance), each of which is then individually encoded by the encoder. Subsequently, the decoder makes predictions based on these encoded passages. Nevertheless, this framework can be relatively time-consuming, particularly due to the extensive length of the gathered passages. To address this, we introduce FastFiD in this paper, a novel approach that executes sentence selection on the encoded passages. This aids in retaining valuable sentences while reducing the context length required for generating answers. Experiments on three commonly used datasets (Natural Questions, TriviaQA and ASQA) demonstrate that our method can enhance the inference speed by 2.3X-5.7X, while simultaneously maintaining the model's performance. Moreover, an in-depth analysis of the model's attention reveals that the selected sentences indeed hold a substantial contribution towards the final answer. The codes are publicly available at https://github.com/thunlp/FastFiD.
Read more8/13/2024
🔍
0
Narrowing the Knowledge Evaluation Gap: Open-Domain Question Answering with Multi-Granularity Answers
Gal Yona, Roee Aharoni, Mor Geva
Factual questions typically can be answered correctly at different levels of granularity. For example, both ``August 4, 1961'' and ``1961'' are correct answers to the question ``When was Barack Obama born?''. Standard question answering (QA) evaluation protocols, however, do not explicitly take this into account and compare a predicted answer against answers of a single granularity level. In this work, we propose GRANOLA QA, a novel evaluation setting where a predicted answer is evaluated in terms of accuracy and informativeness against a set of multi-granularity answers. We present a simple methodology for enriching existing datasets with multi-granularity answers, and create GRANOLA-EQ, a multi-granularity version of the EntityQuestions dataset. We evaluate a range of decoding methods on GRANOLA-EQ, including a new algorithm, called Decoding with Response Aggregation (DRAG), that is geared towards aligning the response granularity with the model's uncertainty. Our experiments show that large language models with standard decoding tend to generate specific answers, which are often incorrect. In contrast, when evaluated on multi-granularity answers, DRAG yields a nearly 20 point increase in accuracy on average, which further increases for rare entities. Overall, this reveals that standard evaluation and decoding schemes may significantly underestimate the knowledge encapsulated in LMs.
Read more8/2/2024
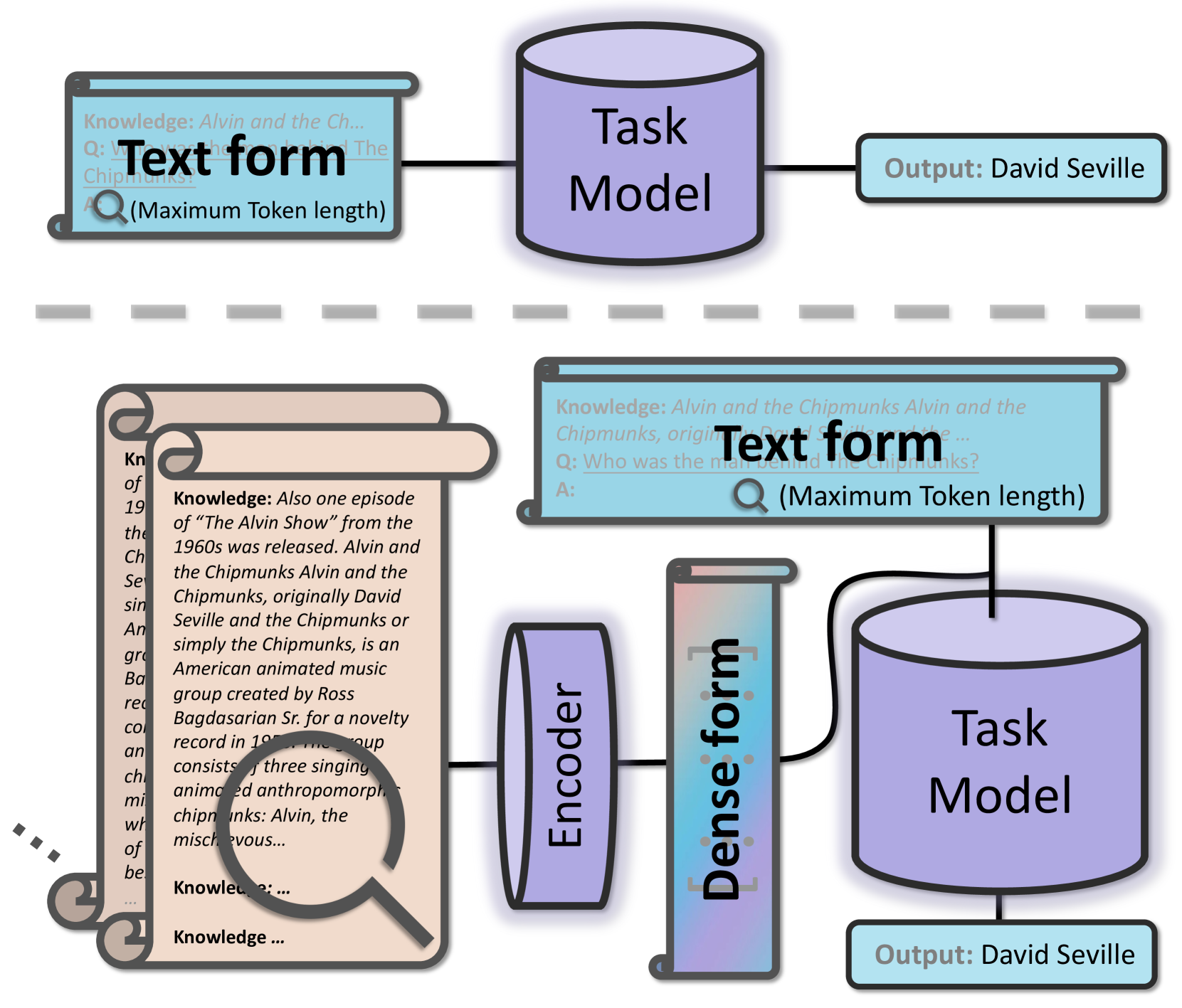
0
Improving Retrieval Augmented Open-Domain Question-Answering with Vectorized Contexts
Zhuo Chen, Xinyu Wang, Yong Jiang, Pengjun Xie, Fei Huang, Kewei Tu
In the era of large language models, applying techniques such as Retrieval Augmented Generation can better address Open-Domain Question-Answering problems. Due to constraints including model sizes and computing resources, the length of context is often limited, and it becomes challenging to empower the model to cover overlong contexts while answering questions from open domains. This paper proposes a general and convenient method to covering longer contexts in Open-Domain Question-Answering tasks. It leverages a small encoder language model that effectively encodes contexts, and the encoding applies cross-attention with origin inputs. With our method, the origin language models can cover several times longer contexts while keeping the computing requirements close to the baseline. Our experiments demonstrate that after fine-tuning, there is improved performance across two held-in datasets, four held-out datasets, and also in two In Context Learning settings.
Read more7/2/2024