Multi-Grid Graph Neural Networks with Self-Attention for Computational Mechanics

0

Sign in to get full access
Overview
- Introduces a new architecture called Multi-Grid Graph Neural Networks with Self-Attention (MGNN-SA) for computational mechanics
- Leverages the hierarchical structure of graphs and self-attention to improve the performance of existing graph neural network models
- Demonstrates the effectiveness of MGNN-SA on several computational mechanics tasks
Plain English Explanation
The paper presents a new neural network architecture called Multi-Grid Graph Neural Networks with Self-Attention (MGNN-SA) that is designed to work with graph-structured data, which is commonly used in computational mechanics problems.
Graphs are a way of representing objects and the relationships between them. In computational mechanics, graphs can be used to model the structure of materials or the flow of fluids, for example. Graph neural networks are a type of machine learning model that can learn from graph-structured data.
The key innovations in MGNN-SA are:
-
Hierarchical Structure: MGNN-SA organizes the graph data into multiple levels of abstraction, similar to how the human brain processes information. This helps the model capture both local and global relationships in the data.
-
Self-Attention: MGNN-SA uses a self-attention mechanism to dynamically focus on the most important parts of the graph when making predictions. This allows the model to adaptively process the input data.
By combining these two techniques, MGNN-SA is able to outperform existing graph neural network models on a variety of computational mechanics tasks, such as modeling complex physical systems.
Technical Explanation
The MGNN-SA architecture consists of multiple layers, each of which operates on a different level of abstraction of the input graph. The lower layers capture local, fine-grained features, while the higher layers capture more global, coarse-grained features.
At each layer, the model applies a graph convolutional operation to update the node features, followed by a self-attention mechanism to selectively focus on the most important parts of the graph. The output of each layer is then passed to the next layer, allowing the model to learn a hierarchical representation of the input data.
The authors evaluate MGNN-SA on several computational mechanics tasks, including structural analysis, fluid dynamics, and material design. They show that MGNN-SA outperforms existing graph neural network models, as well as traditional finite element methods, on these tasks.
Critical Analysis
The paper provides a thorough evaluation of MGNN-SA on a range of computational mechanics problems, demonstrating its effectiveness compared to existing methods. However, the authors do not discuss any potential limitations or caveats of the approach.
For example, the computational complexity of the self-attention mechanism may be a concern, especially for large-scale graph data. Additionally, the paper does not explore the interpretability of the MGNN-SA model, which could be important for understanding the underlying physical phenomena.
Further research could also investigate the generalization of MGNN-SA to other types of graph-structured data beyond computational mechanics, as well as explore ways to improve the model's efficiency and interpretability.
Conclusion
The Multi-Grid Graph Neural Networks with Self-Attention (MGNN-SA) architecture presented in this paper represents a significant advancement in the field of computational mechanics. By leveraging the hierarchical structure of graphs and the power of self-attention, MGNN-SA is able to outperform existing methods on a variety of tasks.
This research has the potential to enable more accurate and efficient modeling of complex physical systems, which could have important implications for engineering, materials science, and other domains. The authors have made an important contribution to the field, and their work paves the way for further developments in the use of graph neural networks for computational mechanics.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Multi-Grid Graph Neural Networks with Self-Attention for Computational Mechanics
Paul Garnier, Jonathan Viquerat, Elie Hachem
Advancement in finite element methods have become essential in various disciplines, and in particular for Computational Fluid Dynamics (CFD), driving research efforts for improved precision and efficiency. While Convolutional Neural Networks (CNNs) have found success in CFD by mapping meshes into images, recent attention has turned to leveraging Graph Neural Networks (GNNs) for direct mesh processing. This paper introduces a novel model merging Self-Attention with Message Passing in GNNs, achieving a 15% reduction in RMSE on the well known flow past a cylinder benchmark. Furthermore, a dynamic mesh pruning technique based on Self-Attention is proposed, that leads to a robust GNN-based multigrid approach, also reducing RMSE by 15%. Additionally, a new self-supervised training method based on BERT is presented, resulting in a 25% RMSE reduction. The paper includes an ablation study and outperforms state-of-the-art models on several challenging datasets, promising advancements similar to those recently achieved in natural language and image processing. Finally, the paper introduces a dataset with meshes larger than existing ones by at least an order of magnitude. Code and Datasets will be released at https://github.com/DonsetPG/multigrid-gnn.
Read more9/19/2024

0
Mesh-based Super-Resolution of Fluid Flows with Multiscale Graph Neural Networks
Shivam Barwey, Pinaki Pal, Saumil Patel, Riccardo Balin, Bethany Lusch, Venkatram Vishwanath, Romit Maulik, Ramesh Balakrishnan
A graph neural network (GNN) approach is introduced in this work which enables mesh-based three-dimensional super-resolution of fluid flows. In this framework, the GNN is designed to operate not on the full mesh-based field at once, but on localized meshes of elements (or cells) directly. To facilitate mesh-based GNN representations in a manner similar to spectral (or finite) element discretizations, a baseline GNN layer (termed a message passing layer, which updates local node properties) is modified to account for synchronization of coincident graph nodes, rendering compatibility with commonly used element-based mesh connectivities. The architecture is multiscale in nature, and is comprised of a combination of coarse-scale and fine-scale message passing layer sequences (termed processors) separated by a graph unpooling layer. The coarse-scale processor embeds a query element (alongside a set number of neighboring coarse elements) into a single latent graph representation using coarse-scale synchronized message passing over the element neighborhood, and the fine-scale processor leverages additional message passing operations on this latent graph to correct for interpolation errors. Demonstration studies are performed using hexahedral mesh-based data from Taylor-Green Vortex flow simulations at Reynolds numbers of 1600 and 3200. Through analysis of both global and local errors, the results ultimately show how the GNN is able to produce accurate super-resolved fields compared to targets in both coarse-scale and multiscale model configurations.
Read more9/19/2024
0
Graph Convolutions Enrich the Self-Attention in Transformers!
Jeongwhan Choi, Hyowon Wi, Jayoung Kim, Yehjin Shin, Kookjin Lee, Nathaniel Trask, Noseong Park
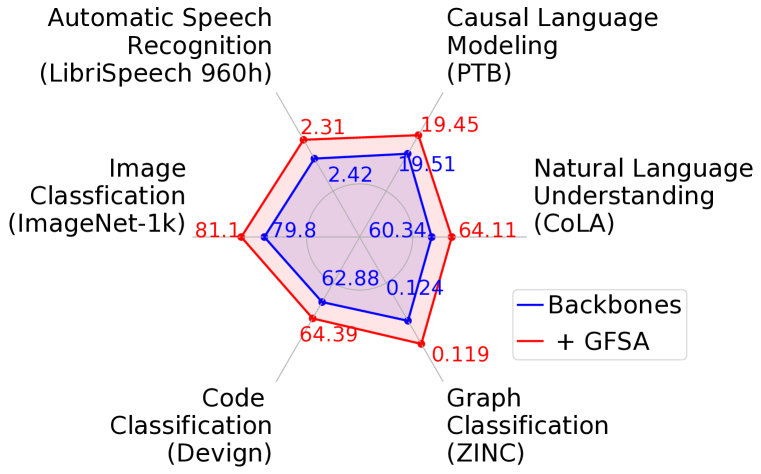
Transformers, renowned for their self-attention mechanism, have achieved state-of-the-art performance across various tasks in natural language processing, computer vision, time-series modeling, etc. However, one of the challenges with deep Transformer models is the oversmoothing problem, where representations across layers converge to indistinguishable values, leading to significant performance degradation. We interpret the original self-attention as a simple graph filter and redesign it from a graph signal processing (GSP) perspective. We propose a graph-filter-based self-attention (GFSA) to learn a general yet effective one, whose complexity, however, is slightly larger than that of the original self-attention mechanism. We demonstrate that GFSA improves the performance of Transformers in various fields, including computer vision, natural language processing, graph regression, speech recognition, and code classification.
Read more6/3/2024
0
Hierarchical Attention Models for Multi-Relational Graphs
Roshni G. Iyer, Wei Wang, Yizhou Sun
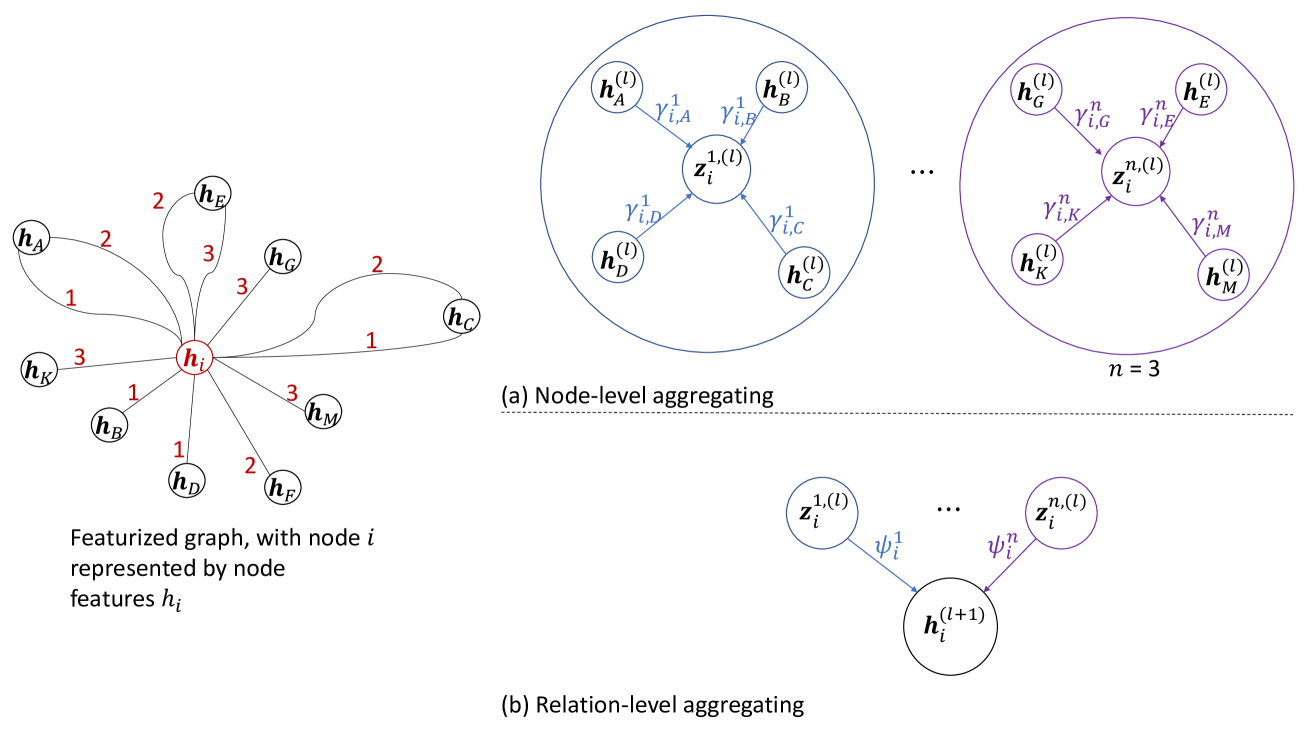
We present Bi-Level Attention-Based Relational Graph Convolutional Networks (BR-GCN), unique neural network architectures that utilize masked self-attentional layers with relational graph convolutions, to effectively operate on highly multi-relational data. BR-GCN models use bi-level attention to learn node embeddings through (1) node-level attention, and (2) relation-level attention. The node-level self-attentional layers use intra-relational graph interactions to learn relation-specific node embeddings using a weighted aggregation of neighborhood features in a sparse subgraph region. The relation-level self-attentional layers use inter-relational graph interactions to learn the final node embeddings using a weighted aggregation of relation-specific node embeddings. The BR-GCN bi-level attention mechanism extends Transformer-based multiplicative attention from the natural language processing (NLP) domain, and Graph Attention Networks (GAT)-based attention, to large-scale heterogeneous graphs (HGs). On node classification, BR-GCN outperforms baselines from 0.29% to 14.95% as a stand-alone model, and on link prediction, BR-GCN outperforms baselines from 0.02% to 7.40% as an auto-encoder model. We also conduct ablation studies to evaluate the quality of BR-GCN's relation-level attention and discuss how its learning of graph structure may be transferred to enrich other graph neural networks (GNNs). Through various experiments, we show that BR-GCN's attention mechanism is both scalable and more effective in learning compared to state-of-the-art GNNs.
Read more4/16/2024