Multi-Head Attention Residual Unfolded Network for Model-Based Pansharpening

0
🌐
Sign in to get full access
Overview
- The goal of pansharpening and hypersharpening is to accurately combine a high-resolution panchromatic (PAN) image with a low-resolution multispectral (MS) or hyperspectral (HS) image.
- Unfolding fusion methods integrate the powerful representation capabilities of deep learning with the robustness of model-based approaches.
- These techniques involve unrolling the steps of the optimization scheme derived from the minimization of an energy into a deep learning framework, resulting in efficient and highly interpretable architectures.
- The paper proposes a model-based deep unfolded method for satellite image fusion.
Plain English Explanation
The paper describes a method for combining high-resolution and low-resolution satellite images to create a single, high-quality image. This is known as "pansharpening" (for multispectral images) or "hypersharpening" (for hyperspectral images).
The key idea is to use a deep learning approach that is grounded in a mathematical model of how the images are related. This allows the method to be both powerful (thanks to deep learning) and interpretable (thanks to the underlying model). Specifically, the method involves "unfolding" the steps of an optimization problem into a deep neural network architecture.
The architecture includes several novel components, such as attention-based residual networks to exploit image self-similarities, and a post-processing module to further enhance the quality of the fused images. The method is evaluated on several satellite image datasets and shown to outperform other state-of-the-art approaches.
Technical Explanation
The paper proposes a model-based deep unfolded method for satellite image fusion, which combines a high-resolution panchromatic (PAN) image with a low-resolution multispectral (MS) or hyperspectral (HS) image.
The approach is based on a variational formulation that incorporates the classic observation model for MS/HS data, a high-frequency injection constraint based on the PAN image, and an arbitrary convex prior. For the unfolding stage, the method introduces upsampling and downsampling layers that use geometric information encoded in the PAN image through residual networks.
The backbone of the method is a multi-head attention residual network (MARNet), which replaces the proximity operator in the optimization scheme and combines multiple head attentions with residual learning to exploit image self-similarities via nonlocal operators defined in terms of patches.
Additionally, the method incorporates a post-processing module based on the MARNet architecture to further enhance the quality of the fused images. Experimental results on PRISMA, Quickbird, and WorldView2 datasets demonstrate the superior performance of the method and its ability to generalize across different sensor configurations and varying spatial and spectral resolutions.
Critical Analysis
The paper provides a comprehensive and technically sound approach to the problem of satellite image fusion. The use of a model-based deep unfolding method is a novel and promising direction, as it combines the strengths of both model-based and deep learning-based approaches.
One potential limitation of the method is its reliance on the availability of a high-resolution PAN image, which may not always be the case, especially for older or less advanced satellite systems. The authors could explore ways to adapt the method to work with alternative sources of high-frequency information or to handle cases where a PAN image is not available.
Additionally, the paper does not provide much discussion on the computational complexity and runtime performance of the proposed method, which could be an important consideration for practical applications that require real-time or near-real-time processing. Investigating the trade-offs between performance and accuracy would be a valuable addition to the research.
Overall, the paper presents a well-designed and thoughtfully implemented method for satellite image fusion, and the authors have done a commendable job in validating its performance on multiple datasets. Further research into the method's robustness and applicability to a wider range of scenarios would be a natural next step.
Conclusion
The paper introduces a model-based deep unfolded method for accurate satellite image fusion, combining high-resolution panchromatic (PAN) and low-resolution multispectral (MS) or hyperspectral (HS) images. The key innovations include the use of a variational formulation, unfolding techniques to integrate deep learning and model-based approaches, and novel architectural components like multi-head attention residual networks.
The proposed method demonstrates superior performance on multiple satellite image datasets, showcasing its ability to generalize across different sensor configurations and resolutions. While the reliance on PAN images and the computational efficiency aspects could be further explored, the paper presents a compelling and technically sound approach to the challenging problem of satellite image fusion, with potential implications for a wide range of remote sensing and earth observation applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌐
0
Multi-Head Attention Residual Unfolded Network for Model-Based Pansharpening
Ivan Pereira-S'anchez, Eloi Sans, Julia Navarro, Joan Duran
The objective of pansharpening and hypersharpening is to accurately combine a high-resolution panchromatic (PAN) image with a low-resolution multispectral (MS) or hyperspectral (HS) image, respectively. Unfolding fusion methods integrate the powerful representation capabilities of deep learning with the robustness of model-based approaches. These techniques involve unrolling the steps of the optimization scheme derived from the minimization of an energy into a deep learning framework, resulting in efficient and highly interpretable architectures. In this paper, we propose a model-based deep unfolded method for satellite image fusion. Our approach is based on a variational formulation that incorporates the classic observation model for MS/HS data, a high-frequency injection constraint based on the PAN image, and an arbitrary convex prior. For the unfolding stage, we introduce upsampling and downsampling layers that use geometric information encoded in the PAN image through residual networks. The backbone of our method is a multi-head attention residual network (MARNet), which replaces the proximity operator in the optimization scheme and combines multiple head attentions with residual learning to exploit image self-similarities via nonlocal operators defined in terms of patches. Additionally, we incorporate a post-processing module based on the MARNet architecture to further enhance the quality of the fused images. Experimental results on PRISMA, Quickbird, and WorldView2 datasets demonstrate the superior performance of our method and its ability to generalize across different sensor configurations and varying spatial and spectral resolutions. The source code will be available at https://github.com/TAMI-UIB/MARNet.
Read more9/5/2024

0
Variational Zero-shot Multispectral Pansharpening
Xiangyu Rui, Xiangyong Cao, Yining Li, Deyu Meng
Pansharpening aims to generate a high spatial resolution multispectral image (HRMS) by fusing a low spatial resolution multispectral image (LRMS) and a panchromatic image (PAN). The most challenging issue for this task is that only the to-be-fused LRMS and PAN are available, and the existing deep learning-based methods are unsuitable since they rely on many training pairs. Traditional variational optimization (VO) based methods are well-suited for addressing such a problem. They focus on carefully designing explicit fusion rules as well as regularizations for an optimization problem, which are based on the researcher's discovery of the image relationships and image structures. Unlike previous VO-based methods, in this work, we explore such complex relationships by a parameterized term rather than a manually designed one. Specifically, we propose a zero-shot pansharpening method by introducing a neural network into the optimization objective. This network estimates a representation component of HRMS, which mainly describes the relationship between HRMS and PAN. In this way, the network achieves a similar goal to the so-called deep image prior because it implicitly regulates the relationship between the HRMS and PAN images through its inherent structure. We directly minimize this optimization objective via network parameters and the expected HRMS image through iterative updating. Extensive experiments on various benchmark datasets demonstrate that our proposed method can achieve better performance compared with other state-of-the-art methods. The codes are available at https://github.com/xyrui/PSDip.
Read more7/10/2024

0
Unrolling Plug-and-Play Network for Hyperspectral Unmixing
Min Zhao, Linruize Tang, Jie Chen
Deep learning based unmixing methods have received great attention in recent years and achieve remarkable performance. These methods employ a data-driven approach to extract structure features from hyperspectral image, however, they tend to be less physical interpretable. Conventional unmixing methods are with much more interpretability, whereas they require manually designing regularization and choosing penalty parameters. To overcome these limitations, we propose a novel unmixing method by unrolling the plug-and-play unmixing algorithm to conduct the deep architecture. Our method integrates both inner and outer priors. The carefully designed unfolding deep architecture is used to learn the spectral and spatial information from the hyperspectral image, which we refer to as inner priors. Additionally, our approach incorporates deep denoisers that have been pretrained on a large volume of image data to leverage the outer priors. Secondly, we design a dynamic convolution to model the multiscale information. Different scales are fused using an attention module. Experimental results of both synthetic and real datasets demonstrate that our method outperforms compared methods.
Read more9/10/2024
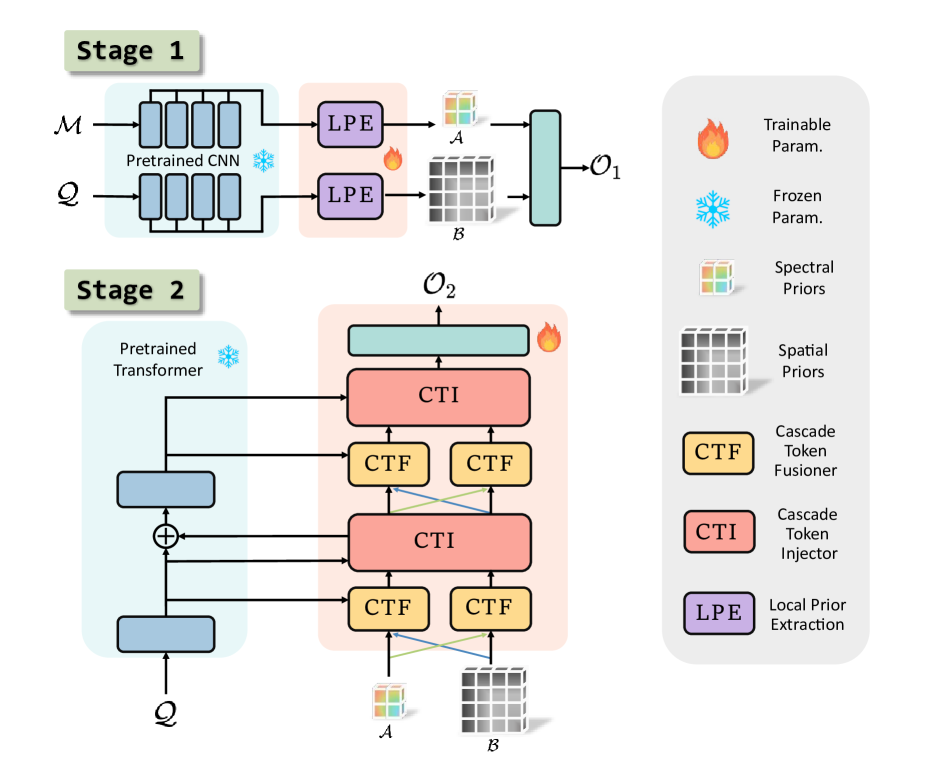
0
PanAdapter: Two-Stage Fine-Tuning with Spatial-Spectral Priors Injecting for Pansharpening
RuoCheng Wu, ZiEn Zhang, ShangQi Deng, YuLe Duan, LiangJian Deng
Pansharpening is a challenging image fusion task that involves restoring images using two different modalities: low-resolution multispectral images (LRMS) and high-resolution panchromatic (PAN). Many end-to-end specialized models based on deep learning (DL) have been proposed, yet the scale and performance of these models are limited by the size of dataset. Given the superior parameter scales and feature representations of pre-trained models, they exhibit outstanding performance when transferred to downstream tasks with small datasets. Therefore, we propose an efficient fine-tuning method, namely PanAdapter, which utilizes additional advanced semantic information from pre-trained models to alleviate the issue of small-scale datasets in pansharpening tasks. Specifically, targeting the large domain discrepancy between image restoration and pansharpening tasks, the PanAdapter adopts a two-stage training strategy for progressively adapting to the downstream task. In the first stage, we fine-tune the pre-trained CNN model and extract task-specific priors at two scales by proposed Local Prior Extraction (LPE) module. In the second stage, we feed the extracted two-scale priors into two branches of cascaded adapters respectively. At each adapter, we design two parameter-efficient modules for allowing the two branches to interact and be injected into the frozen pre-trained VisionTransformer (ViT) blocks. We demonstrate that by only training the proposed LPE modules and adapters with a small number of parameters, our approach can benefit from pre-trained image restoration models and achieve state-of-the-art performance in several benchmark pansharpening datasets. The code will be available soon.
Read more9/12/2024