Variational Zero-shot Multispectral Pansharpening

0

Sign in to get full access
Overview
- This paper presents a novel variational zero-shot approach for multispectral pansharpening, which aims to fuse a low-resolution multispectral image and a high-resolution panchromatic image to produce a high-resolution multispectral image.
- The method leverages the deep image prior (DIP) concept, which learns an image-specific neural network to capture the structure of the target high-resolution multispectral image without requiring any training data.
- The proposed approach is "zero-shot" in the sense that it does not require any paired training data of low- and high-resolution multispectral images, making it highly practical for real-world applications.
Plain English Explanation
In remote sensing, it is often desirable to have high-resolution multispectral images, which capture detailed information across different wavelengths of the electromagnetic spectrum. However, acquiring such high-resolution multispectral data can be challenging and expensive. Hyperspectral pansharpening is a technique that aims to address this by combining a low-resolution multispectral image with a high-resolution panchromatic (grayscale) image to produce a high-resolution multispectral image.
The key innovation in this paper is a new "zero-shot" approach to multispectral pansharpening. Rather than relying on paired training data of low- and high-resolution multispectral images, which can be difficult to obtain, the proposed method uses a deep neural network to learn the structure of the target high-resolution multispectral image directly from the given low-resolution multispectral and high-resolution panchromatic images. This "deep image prior" concept allows the algorithm to discover the inherent patterns in the data, without requiring any labeled training examples.
By avoiding the need for paired training data, this zero-shot approach makes multispectral pansharpening much more practical and accessible for real-world applications, where such data may not be readily available. The method could enable more widespread use of high-resolution multispectral imaging in fields like remote sensing, agriculture, and environmental monitoring.
Technical Explanation
The proposed method, called Variational Zero-shot Multispectral Pansharpening (VZMP), formulates the pansharpening task as a variational optimization problem. The key components are:
-
Deep Image Prior: The method leverages the deep image prior (DIP) concept, which learns an image-specific neural network to capture the structure of the target high-resolution multispectral image. This network is optimized directly on the input low-resolution multispectral and high-resolution panchromatic images, without any training data.
-
Variational Formulation: The pansharpening problem is cast as a variational optimization problem, where the goal is to find the high-resolution multispectral image that best matches the given low-resolution multispectral and high-resolution panchromatic images, while also satisfying certain regularity constraints.
-
Optimization: The optimization is performed using a gradient-based approach, where the image-specific neural network parameters and the high-resolution multispectral image are jointly optimized to minimize the variational objective function.
The key advantage of this approach is that it does not require any paired training data of low- and high-resolution multispectral images, which can be challenging to obtain in practice. By leveraging the deep image prior concept, the method can learn the structure of the target high-resolution multispectral image directly from the given input data, making it a "zero-shot" pansharpening technique.
The authors evaluate the proposed VZMP method on several benchmark multispectral pansharpening datasets and compare its performance to state-of-the-art pansharpening techniques, including Pan-Denoising-Guided Hyperspectral Image Denoising, Hyperspectral-Multispectral Image Fusion, and PSPRF-Pansharpening. The results demonstrate the effectiveness of the proposed zero-shot approach, which achieves competitive or superior performance compared to the other methods while requiring no paired training data.
Critical Analysis
The key strength of the proposed VZMP method is its ability to perform multispectral pansharpening in a zero-shot manner, without the need for any paired training data. This makes the technique highly practical and accessible for real-world applications, where such data may be scarce or difficult to obtain.
However, the paper also acknowledges some limitations of the approach. For example, the method relies on the deep image prior concept, which can be sensitive to hyperparameter choices and may not always converge to the optimal solution. Additionally, the authors note that the performance of the method can be influenced by the quality and characteristics of the input low-resolution multispectral and high-resolution panchromatic images.
Further research could explore ways to improve the robustness and stability of the optimization process, potentially through the incorporation of additional prior information or the use of more advanced neural network architectures. Additionally, Linearly Evolved Transformer and other recent pansharpening techniques could be investigated to see if they can be adapted for the zero-shot setting.
Overall, the Variational Zero-shot Multispectral Pansharpening method presented in this paper represents an important step forward in making high-resolution multispectral imaging more accessible and practical for a wide range of applications.
Conclusion
This paper introduces a novel variational zero-shot approach for multispectral pansharpening, which aims to fuse low-resolution multispectral and high-resolution panchromatic images to produce a high-resolution multispectral output. The key innovation is the use of the deep image prior concept, which allows the method to learn the structure of the target high-resolution multispectral image directly from the input data, without requiring any paired training examples.
By avoiding the need for labeled training data, the proposed VZMP technique makes multispectral pansharpening much more practical and accessible for real-world applications in remote sensing, agriculture, environmental monitoring, and beyond. While the method has some limitations, the paper represents an important contribution to the field of image fusion and could pave the way for more widespread use of high-resolution multispectral imaging in a variety of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Variational Zero-shot Multispectral Pansharpening
Xiangyu Rui, Xiangyong Cao, Yining Li, Deyu Meng
Pansharpening aims to generate a high spatial resolution multispectral image (HRMS) by fusing a low spatial resolution multispectral image (LRMS) and a panchromatic image (PAN). The most challenging issue for this task is that only the to-be-fused LRMS and PAN are available, and the existing deep learning-based methods are unsuitable since they rely on many training pairs. Traditional variational optimization (VO) based methods are well-suited for addressing such a problem. They focus on carefully designing explicit fusion rules as well as regularizations for an optimization problem, which are based on the researcher's discovery of the image relationships and image structures. Unlike previous VO-based methods, in this work, we explore such complex relationships by a parameterized term rather than a manually designed one. Specifically, we propose a zero-shot pansharpening method by introducing a neural network into the optimization objective. This network estimates a representation component of HRMS, which mainly describes the relationship between HRMS and PAN. In this way, the network achieves a similar goal to the so-called deep image prior because it implicitly regulates the relationship between the HRMS and PAN images through its inherent structure. We directly minimize this optimization objective via network parameters and the expected HRMS image through iterative updating. Extensive experiments on various benchmark datasets demonstrate that our proposed method can achieve better performance compared with other state-of-the-art methods. The codes are available at https://github.com/xyrui/PSDip.
Read more7/10/2024
🌐
0
Multi-Head Attention Residual Unfolded Network for Model-Based Pansharpening
Ivan Pereira-S'anchez, Eloi Sans, Julia Navarro, Joan Duran
The objective of pansharpening and hypersharpening is to accurately combine a high-resolution panchromatic (PAN) image with a low-resolution multispectral (MS) or hyperspectral (HS) image, respectively. Unfolding fusion methods integrate the powerful representation capabilities of deep learning with the robustness of model-based approaches. These techniques involve unrolling the steps of the optimization scheme derived from the minimization of an energy into a deep learning framework, resulting in efficient and highly interpretable architectures. In this paper, we propose a model-based deep unfolded method for satellite image fusion. Our approach is based on a variational formulation that incorporates the classic observation model for MS/HS data, a high-frequency injection constraint based on the PAN image, and an arbitrary convex prior. For the unfolding stage, we introduce upsampling and downsampling layers that use geometric information encoded in the PAN image through residual networks. The backbone of our method is a multi-head attention residual network (MARNet), which replaces the proximity operator in the optimization scheme and combines multiple head attentions with residual learning to exploit image self-similarities via nonlocal operators defined in terms of patches. Additionally, we incorporate a post-processing module based on the MARNet architecture to further enhance the quality of the fused images. Experimental results on PRISMA, Quickbird, and WorldView2 datasets demonstrate the superior performance of our method and its ability to generalize across different sensor configurations and varying spatial and spectral resolutions. The source code will be available at https://github.com/TAMI-UIB/MARNet.
Read more9/5/2024

0
Hyperspectral Pansharpening: Critical Review, Tools and Future Perspectives
Matteo Ciotola, Giuseppe Guarino, Gemine Vivone, Giovanni Poggi, Jocelyn Chanussot, Antonio Plaza, Giuseppe Scarpa
Hyperspectral pansharpening consists of fusing a high-resolution panchromatic band and a low-resolution hyperspectral image to obtain a new image with high resolution in both the spatial and spectral domains. These remote sensing products are valuable for a wide range of applications, driving ever growing research efforts. Nonetheless, results still do not meet application demands. In part, this comes from the technical complexity of the task: compared to multispectral pansharpening, many more bands are involved, in a spectral range only partially covered by the panchromatic component and with overwhelming noise. However, another major limiting factor is the absence of a comprehensive framework for the rapid development and accurate evaluation of new methods. This paper attempts to address this issue. We started by designing a dataset large and diverse enough to allow reliable training (for data-driven methods) and testing of new methods. Then, we selected a set of state-of-the-art methods, following different approaches, characterized by promising performance, and reimplemented them in a single PyTorch framework. Finally, we carried out a critical comparative analysis of all methods, using the most accredited quality indicators. The analysis highlights the main limitations of current solutions in terms of spectral/spatial quality and computational efficiency, and suggests promising research directions. To ensure full reproducibility of the results and support future research, the framework (including codes, evaluation procedures and links to the dataset) is shared on https://github.com/matciotola/hyperspectral_pansharpening_toolbox, as a single Python-based reference benchmark toolbox.
Read more7/2/2024
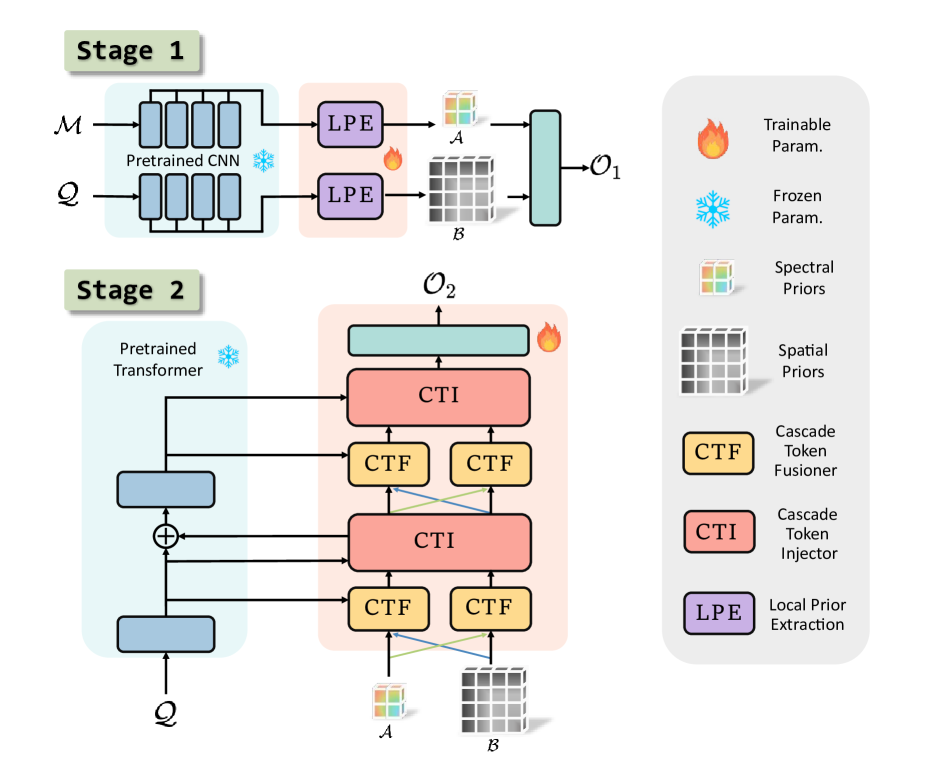
0
PanAdapter: Two-Stage Fine-Tuning with Spatial-Spectral Priors Injecting for Pansharpening
RuoCheng Wu, ZiEn Zhang, ShangQi Deng, YuLe Duan, LiangJian Deng
Pansharpening is a challenging image fusion task that involves restoring images using two different modalities: low-resolution multispectral images (LRMS) and high-resolution panchromatic (PAN). Many end-to-end specialized models based on deep learning (DL) have been proposed, yet the scale and performance of these models are limited by the size of dataset. Given the superior parameter scales and feature representations of pre-trained models, they exhibit outstanding performance when transferred to downstream tasks with small datasets. Therefore, we propose an efficient fine-tuning method, namely PanAdapter, which utilizes additional advanced semantic information from pre-trained models to alleviate the issue of small-scale datasets in pansharpening tasks. Specifically, targeting the large domain discrepancy between image restoration and pansharpening tasks, the PanAdapter adopts a two-stage training strategy for progressively adapting to the downstream task. In the first stage, we fine-tune the pre-trained CNN model and extract task-specific priors at two scales by proposed Local Prior Extraction (LPE) module. In the second stage, we feed the extracted two-scale priors into two branches of cascaded adapters respectively. At each adapter, we design two parameter-efficient modules for allowing the two branches to interact and be injected into the frozen pre-trained VisionTransformer (ViT) blocks. We demonstrate that by only training the proposed LPE modules and adapters with a small number of parameters, our approach can benefit from pre-trained image restoration models and achieve state-of-the-art performance in several benchmark pansharpening datasets. The code will be available soon.
Read more9/12/2024