Multi-label Zero-Shot Audio Classification with Temporal Attention

0

Sign in to get full access
Overview
- The paper proposes a method for multi-label zero-shot audio classification using temporal attention.
- The key ideas include using a shared embedding space for audio and text, and an attention mechanism to focus on relevant audio features for each class.
- The method is evaluated on several audio classification benchmarks and shows improved performance over existing zero-shot approaches.
Plain English Explanation
The researchers developed a new way to classify audio recordings into multiple categories, even when the model hasn't been trained on those specific categories before. This is called "zero-shot" learning, because the model can handle new classes without any prior training on them.
The core idea is to create a shared space where audio features and textual descriptions of sound classes can be compared and matched. This allows the model to recognize new sound classes based on their textual descriptions, without needing examples of those sounds during training.
To make this work, the model also uses an "attention" mechanism. This lets it focus on the most relevant parts of the audio input when classifying each new sound category. By honing in on the important audio features for each class, the model can make more accurate zero-shot predictions.
The researchers tested this approach on several benchmarks for audio classification, and found it outperformed other zero-shot methods. This suggests it's a promising technique for building audio AI systems that can handle open-ended sets of sound categories, without the need for exhaustive training data.
Technical Explanation
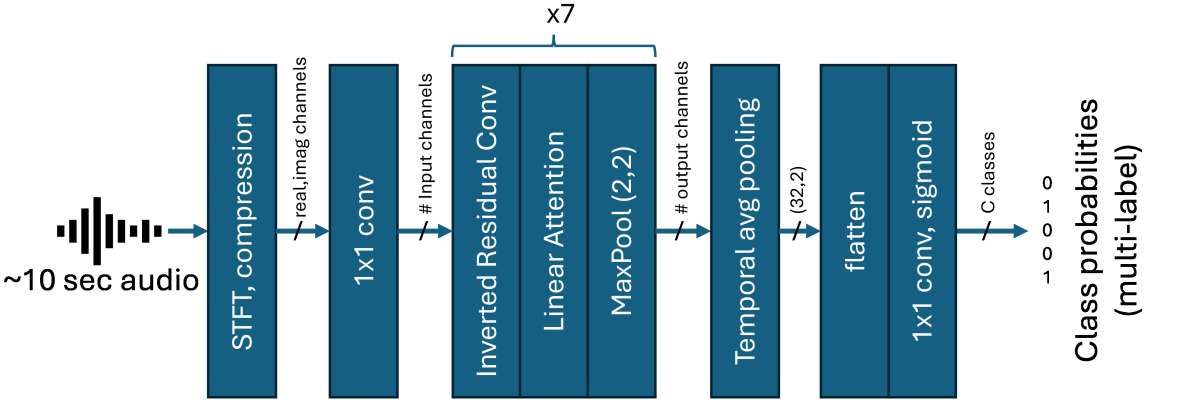
The paper introduces a multi-label zero-shot audio classification model that uses temporal attention to focus on relevant audio features for each target class.
The key components are:
- A shared embedding space that maps audio features and text descriptions of sound classes into a common vector representation.
- A classification head that predicts multiple labels for an audio input by attending to the relevant parts of the audio based on each class's text embedding.
- A training process that learns the shared embedding space and attention weights in a end-to-end fashion, using only text descriptions of sound classes (no audio examples for new classes).
The model is evaluated on several audio classification benchmarks, showing improved zero-shot performance compared to prior methods. The temporal attention mechanism is found to be a crucial component, allowing the model to focus on the salient audio features for each target class.
Critical Analysis
The paper presents a well-designed method for multi-label zero-shot audio classification, with a strong technical approach and thorough experimental evaluation.
However, the authors acknowledge some limitations:
- The model still relies on having high-quality text descriptions for the sound classes, which may not always be available.
- The zero-shot performance, while improved over prior work, is still lower than supervised learning approaches that have access to labeled audio examples.
- The training and inference time of the model could be optimized further for real-world deployment.
Additionally, one might question whether the attention mechanism is truly necessary, or if simpler cross-modal matching could achieve comparable results. Further analysis and ablation studies could help validate the importance of this component.
Overall, this is a thoughtful and well-executed piece of research that advances the state-of-the-art in zero-shot audio classification. The insights and techniques presented could be valuable for building more flexible and generalizable audio AI systems.
Conclusion
This paper introduces a novel approach for multi-label zero-shot audio classification that leverages a shared embedding space and temporal attention. By learning to focus on the relevant audio features for each target class, the model can effectively recognize new sound categories based only on their text descriptions.
The proposed method demonstrates improved zero-shot performance on standard benchmarks, suggesting it is a promising direction for building audio AI systems that can adapt to open-ended sets of sound classes without exhaustive training data. While some limitations remain, this work represents an important step forward in advancing the capabilities of zero-shot learning for audio understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multi-label Zero-Shot Audio Classification with Temporal Attention
Duygu Dogan, Huang Xie, Toni Heittola, Tuomas Virtanen
Zero-shot learning models are capable of classifying new classes by transferring knowledge from the seen classes using auxiliary information. While most of the existing zero-shot learning methods focused on single-label classification tasks, the present study introduces a method to perform multi-label zero-shot audio classification. To address the challenge of classifying multi-label sounds while generalizing to unseen classes, we adapt temporal attention. The temporal attention mechanism assigns importance weights to different audio segments based on their acoustic and semantic compatibility, thus enabling the model to capture the varying dominance of different sound classes within an audio sample by focusing on the segments most relevant for each class. This leads to more accurate multi-label zero-shot classification than methods employing temporally aggregated acoustic features without weighting, which treat all audio segments equally. We evaluate our approach on a subset of AudioSet against a zero-shot model using uniformly aggregated acoustic features, a zero-rule baseline, and the proposed method in the supervised scenario. Our results show that temporal attention enhances the zero-shot audio classification performance in multi-label scenario.
Read more9/4/2024

0
Enhancing Zero-shot Audio Classification using Sound Attribute Knowledge from Large Language Models
Xuenan Xu, Pingyue Zhang, Ming Yan, Ji Zhang, Mengyue Wu
Zero-shot audio classification aims to recognize and classify a sound class that the model has never seen during training. This paper presents a novel approach for zero-shot audio classification using automatically generated sound attribute descriptions. We propose a list of sound attributes and leverage large language model's domain knowledge to generate detailed attribute descriptions for each class. In contrast to previous works that primarily relied on class labels or simple descriptions, our method focuses on multi-dimensional innate auditory attributes, capturing different characteristics of sound classes. Additionally, we incorporate a contrastive learning approach to enhance zero-shot learning from textual labels. We validate the effectiveness of our method on VGGSound and AudioSetfootnote{The code is available at url{https://www.github.com/wsntxxn/AttrEnhZsAc}.}. Our results demonstrate a substantial improvement in zero-shot classification accuracy. Ablation results show robust performance enhancement, regardless of the model architecture.
Read more7/22/2024
0
Multi-label audio classification with a noisy zero-shot teacher
Sebastian Braun, Hannes Gamper
We propose a novel training scheme using self-label correction and data augmentation methods designed to deal with noisy labels and improve real-world accuracy on a polyphonic audio content detection task. The augmentation method reduces label noise by mixing multiple audio clips and joining their labels, while being compatible with multiple active labels. We additionally show that performance can be improved by a self-label correction method using the same pretrained model. Finally, we show that it is feasible to use a strong zero-shot model such as CLAP to generate labels for unlabeled data and improve the results using the proposed training and label enhancement methods. The resulting model performs similar to CLAP while being an efficient mobile device friendly architecture and can be quickly adapted to unlabeled sound classes.
Read more7/23/2024
🤖
0
Enhancing Audio-Language Models through Self-Supervised Post-Training with Text-Audio Pairs
Anshuman Sinha, Camille Migozzi, Aubin Rey, Chao Zhang
Research on multi-modal contrastive learning strategies for audio and text has rapidly gained interest. Contrastively trained Audio-Language Models (ALMs), such as CLAP, which establish a unified representation across audio and language modalities, have enhanced the efficacy in various subsequent tasks by providing good text aligned audio encoders and vice versa. These improvements are evident in areas like zero-shot audio classification and audio retrieval, among others. However, the ability of these models to understand natural language and temporal relations is still a largely unexplored and open field for research. In this paper, we propose to equip the multi-modal ALMs with temporal understanding without loosing their inherent prior capabilities of audio-language tasks with a temporal instillation method TeminAL. We implement a two-stage training scheme TeminAL A $&$ B, where the model first learns to differentiate between multiple sounds in TeminAL A, followed by a phase that instills a sense of time, thereby enhancing its temporal understanding in TeminAL B. This approach results in an average performance gain of $5.28%$ in temporal understanding on the ESC-50 dataset, while the model remains competitive in zero-shot retrieval and classification tasks on the AudioCap/Clotho datasets. We also note the lack of proper evaluation techniques for contrastive ALMs and propose a strategy for evaluating ALMs in zero-shot settings. The general-purpose zero-shot model evaluation strategy ZSTE, is used to evaluate various prior models. ZSTE demonstrates a general strategy to evaluate all ZS contrastive models. The model trained with TeminAL successfully outperforms current models on most downstream tasks.
Read more8/20/2024