Multi-label audio classification with a noisy zero-shot teacher

0
Sign in to get full access
Overview
- Presents a novel approach for multi-label audio classification using a "noisy zero-shot teacher"
- Aims to tackle the challenge of limited labeled data for audio classification tasks
- Leverages a zero-shot learning model to provide guidance for the classification model, even in the presence of noisy labels
Plain English Explanation
This research paper describes a new way to classify audio clips into multiple categories, even when there is limited labeled data available for training the classification model. The key idea is to use a "zero-shot" model that can make predictions about audio clips without being trained on labeled examples.
The zero-shot model acts as a "teacher" that provides guidance to the main classification model, even when the teacher's predictions may be noisy or imperfect. By incorporating this noisy zero-shot "teacher" input, the classification model can learn to make accurate multi-label predictions despite the limited labeled training data.
The authors demonstrate the effectiveness of this approach on several audio classification benchmarks, showing that it can outperform traditional supervised learning methods when labeled data is scarce. This technique could be particularly useful in real-world applications where obtaining large labeled audio datasets can be challenging or expensive.
Technical Explanation
The paper introduces a "Noisy Zero-shot Teacher" (NZT) framework for multi-label audio classification. The core idea is to leverage a zero-shot learning model, which can make predictions about audio clips without being trained on labeled examples, to guide the training of a multi-label classification model.
The NZT framework consists of two main components:
- Zero-shot Teacher: This is a pre-trained model that can map audio clips to semantic embedding spaces and make predictions about their labels, even without having seen labeled examples during training.
- Multi-label Classifier: This is the main classification model that is trained to make accurate multi-label predictions on the audio data. It is trained using the limited labeled data, as well as the (potentially noisy) predictions from the zero-shot teacher model.
By incorporating the zero-shot teacher's predictions, even if they are not perfectly accurate, the multi-label classifier can learn to make more reliable multi-label predictions, especially when labeled training data is scarce.
The authors evaluate the NZT framework on several audio classification benchmarks, including AudioSet, ESC-50, and FSDnoisy18k. They show that the NZT approach outperforms traditional supervised learning methods when labeled data is limited, demonstrating the potential of this technique for real-world audio classification tasks.
Critical Analysis
The paper presents a promising approach for addressing the challenge of limited labeled data in multi-label audio classification. The use of a zero-shot "teacher" model to provide guidance to the main classification model is a novel and potentially impactful idea.
One potential limitation of the NZT framework is the reliance on the accuracy of the zero-shot teacher model. If the teacher's predictions are too noisy or unreliable, this could negatively impact the performance of the main classifier. The authors do acknowledge this limitation and suggest that further research is needed to improve the robustness of the zero-shot teacher model.
Additionally, the paper does not provide a detailed analysis of the computational and memory requirements of the NZT framework, which could be an important consideration for real-world deployment. It would be valuable to understand the trade-offs between the performance gains and the increased model complexity or inference time.
Overall, the NZT framework represents an interesting and potentially valuable contribution to the field of audio classification. The authors have demonstrated its effectiveness on several benchmarks, and further research to address the identified limitations could lead to even more robust and practical solutions.
Conclusion
This research paper presents a novel approach for multi-label audio classification that leverages a "noisy zero-shot teacher" to guide the training of a classification model, even when labeled data is limited. The key idea is to use a zero-shot learning model to provide predictions about audio clips, and then incorporate this "teacher" input into the training of the main classification model.
The authors show that this NZT framework can outperform traditional supervised learning methods on several audio classification benchmarks when labeled data is scarce. This technique could be particularly useful in real-world applications where obtaining large labeled audio datasets can be challenging or expensive.
While the paper identifies some potential limitations of the NZT approach, such as the reliance on the accuracy of the zero-shot teacher model, the overall contribution represents an interesting and promising direction for improving audio classification in data-limited scenarios. Further research to address these limitations could lead to even more robust and practical solutions for this important problem.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multi-label audio classification with a noisy zero-shot teacher
Sebastian Braun, Hannes Gamper
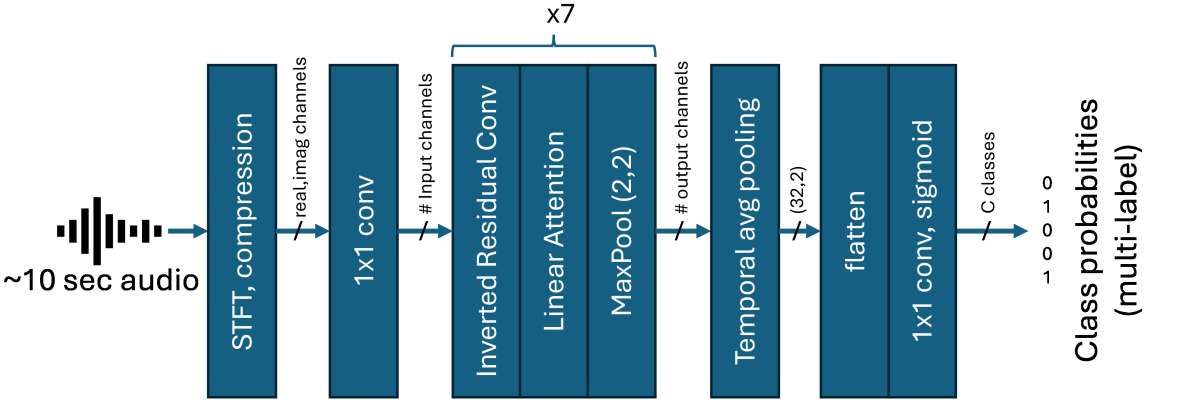
We propose a novel training scheme using self-label correction and data augmentation methods designed to deal with noisy labels and improve real-world accuracy on a polyphonic audio content detection task. The augmentation method reduces label noise by mixing multiple audio clips and joining their labels, while being compatible with multiple active labels. We additionally show that performance can be improved by a self-label correction method using the same pretrained model. Finally, we show that it is feasible to use a strong zero-shot model such as CLAP to generate labels for unlabeled data and improve the results using the proposed training and label enhancement methods. The resulting model performs similar to CLAP while being an efficient mobile device friendly architecture and can be quickly adapted to unlabeled sound classes.
Read more7/23/2024

0
Multi-label Zero-Shot Audio Classification with Temporal Attention
Duygu Dogan, Huang Xie, Toni Heittola, Tuomas Virtanen
Zero-shot learning models are capable of classifying new classes by transferring knowledge from the seen classes using auxiliary information. While most of the existing zero-shot learning methods focused on single-label classification tasks, the present study introduces a method to perform multi-label zero-shot audio classification. To address the challenge of classifying multi-label sounds while generalizing to unseen classes, we adapt temporal attention. The temporal attention mechanism assigns importance weights to different audio segments based on their acoustic and semantic compatibility, thus enabling the model to capture the varying dominance of different sound classes within an audio sample by focusing on the segments most relevant for each class. This leads to more accurate multi-label zero-shot classification than methods employing temporally aggregated acoustic features without weighting, which treat all audio segments equally. We evaluate our approach on a subset of AudioSet against a zero-shot model using uniformly aggregated acoustic features, a zero-rule baseline, and the proposed method in the supervised scenario. Our results show that temporal attention enhances the zero-shot audio classification performance in multi-label scenario.
Read more9/4/2024

0
New!ReCLAP: Improving Zero Shot Audio Classification by Describing Sounds
Sreyan Ghosh, Sonal Kumar, Chandra Kiran Reddy Evuru, Oriol Nieto, Ramani Duraiswami, Dinesh Manocha
Open-vocabulary audio-language models, like CLAP, offer a promising approach for zero-shot audio classification (ZSAC) by enabling classification with any arbitrary set of categories specified with natural language prompts. In this paper, we propose a simple but effective method to improve ZSAC with CLAP. Specifically, we shift from the conventional method of using prompts with abstract category labels (e.g., Sound of an organ) to prompts that describe sounds using their inherent descriptive features in a diverse context (e.g.,The organ's deep and resonant tones filled the cathedral.). To achieve this, we first propose ReCLAP, a CLAP model trained with rewritten audio captions for improved understanding of sounds in the wild. These rewritten captions describe each sound event in the original caption using their unique discriminative characteristics. ReCLAP outperforms all baselines on both multi-modal audio-text retrieval and ZSAC. Next, to improve zero-shot audio classification with ReCLAP, we propose prompt augmentation. In contrast to the traditional method of employing hand-written template prompts, we generate custom prompts for each unique label in the dataset. These custom prompts first describe the sound event in the label and then employ them in diverse scenes. Our proposed method improves ReCLAP's performance on ZSAC by 1%-18% and outperforms all baselines by 1% - 55%.
Read more9/17/2024
0
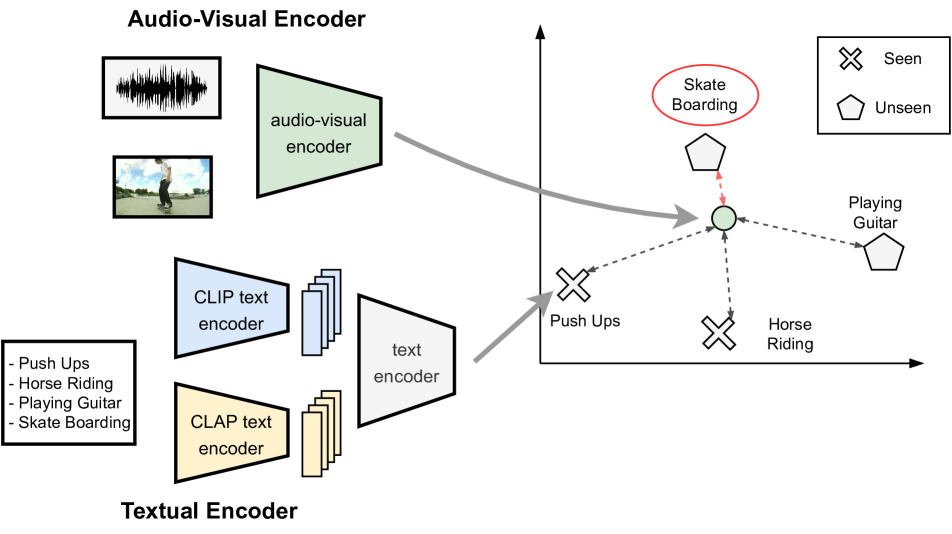
Audio-Visual Generalized Zero-Shot Learning using Pre-Trained Large Multi-Modal Models
David Kurzendorfer, Otniel-Bogdan Mercea, A. Sophia Koepke, Zeynep Akata
Audio-visual zero-shot learning methods commonly build on features extracted from pre-trained models, e.g. video or audio classification models. However, existing benchmarks predate the popularization of large multi-modal models, such as CLIP and CLAP. In this work, we explore such large pre-trained models to obtain features, i.e. CLIP for visual features, and CLAP for audio features. Furthermore, the CLIP and CLAP text encoders provide class label embeddings which are combined to boost the performance of the system. We propose a simple yet effective model that only relies on feed-forward neural networks, exploiting the strong generalization capabilities of the new audio, visual and textual features. Our framework achieves state-of-the-art performance on VGGSound-GZSL, UCF-GZSL, and ActivityNet-GZSL with our new features. Code and data available at: https://github.com/dkurzend/ClipClap-GZSL.
Read more4/10/2024