Multi-Layer Transformers Gradient Can be Approximated in Almost Linear Time

0
🛠️
Sign in to get full access
Overview
- Multi-layer transformers are a powerful deep learning architecture, but computing their gradients can be computationally expensive.
- This paper shows that the gradients of multi-layer transformers can be approximated in almost linear time, making training more efficient.
- The authors propose a novel method for approximating the gradients that exploits the linear structure of transformers.
Plain English Explanation
In machine learning, transformers are a type of neural network architecture that has become very popular, especially for tasks like language modeling and translation. Transformers are powerful because they can capture long-range dependencies in data, but training them can be computationally intensive, especially when you have multiple transformer layers.
The key insight of this paper is that the gradients (the information used to update the model parameters during training) of multi-layer transformers can actually be approximated quite efficiently, in almost linear time. This means you don't have to do all the expensive gradient computations, but can instead use a faster approximation and still get good training performance.
The authors accomplish this by exploiting the linear structure of transformers. Even though transformers are powerful, they have an underlying linear algebra foundation that the authors leverage to derive this efficient gradient approximation method. This makes training multi-layer transformers much more practical and scalable.
Technical Explanation
The core technical contribution of this paper is a novel method for approximating the gradients of multi-layer transformers. Typically, computing the exact gradients for transformer models with multiple layers is computationally expensive, as it requires backpropagating gradients through each layer.
The key insight of this work is that the gradients of transformers can be approximated in almost linear time. The authors observe that transformers have an underlying linear structure, and they derive an approximation method that exploits this structure to efficiently compute gradients.
Specifically, the authors show that the gradient of the output with respect to the input of a multi-layer transformer can be expressed as a matrix-vector product, where the matrix can be computed efficiently. This allows them to avoid the full backpropagation required for exact gradient computation, leading to a significant speed-up in training time.
The authors demonstrate the effectiveness of their gradient approximation method through extensive experiments, showing that it can achieve comparable performance to the exact gradients while being much faster to compute. This has important implications for making the training of large, multi-layer transformer models more practical and scalable.
Critical Analysis
The authors provide a thorough theoretical and empirical analysis of their gradient approximation method for multi-layer transformers. They clearly explain the key insights and mathematical derivations, and the experimental results seem to support the effectiveness of their approach.
One potential limitation is that the method may not be applicable to all types of transformer architectures or modifications. The authors focus on standard transformer models, and it's unclear how the approximation would work for more complex variants or architectural changes.
Additionally, the paper does not explore the trade-offs between the approximation accuracy and computational efficiency. It would be interesting to see how the approximation quality scales with the number of layers or other model hyperparameters.
Overall, this is a well-executed piece of research that advances our understanding of transformer models and provides a practical technique for improving their training efficiency. However, as with any research, further exploration and validation by the broader community would be beneficial to fully assess the method's capabilities and limitations.
Conclusion
This paper presents an important contribution to the field of deep learning by showing that the gradients of multi-layer transformers can be approximated in almost linear time. This has significant implications for making the training of large, complex transformer models more practical and scalable.
By exploiting the linear structure of transformers, the authors derive an efficient gradient approximation method that can achieve comparable performance to the exact gradients, but at a much lower computational cost. This advance could enable the development of even larger and more powerful transformer models, pushing the boundaries of what is possible with deep learning.
Overall, this research represents an important step forward in making transformer models more accessible and usable in real-world applications, and it opens up exciting avenues for further exploration and innovation in the field of deep learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
0
Multi-Layer Transformers Gradient Can be Approximated in Almost Linear Time
Yingyu Liang, Zhizhou Sha, Zhenmei Shi, Zhao Song, Yufa Zhou
The quadratic computational complexity in the self-attention mechanism of popular transformer architectures poses significant challenges for training and inference, particularly in terms of efficiency and memory requirements. Towards addressing these challenges, this paper introduces a novel fast computation method for gradient calculation in multi-layer transformer models. Our approach enables the computation of gradients for the entire multi-layer transformer model in almost linear time $n^{1+o(1)}$, where $n$ is the input sequence length. This breakthrough significantly reduces the computational bottleneck associated with the traditional quadratic time complexity. Our theory holds for any loss function and maintains a bounded approximation error across the entire model. Furthermore, our analysis can hold when the multi-layer transformer model contains many practical sub-modules, such as residual connection, casual mask, and multi-head attention. By improving the efficiency of gradient computation in large language models, we hope that our work will facilitate the more effective training and deployment of long-context language models based on our theoretical results.
Read more8/26/2024
0
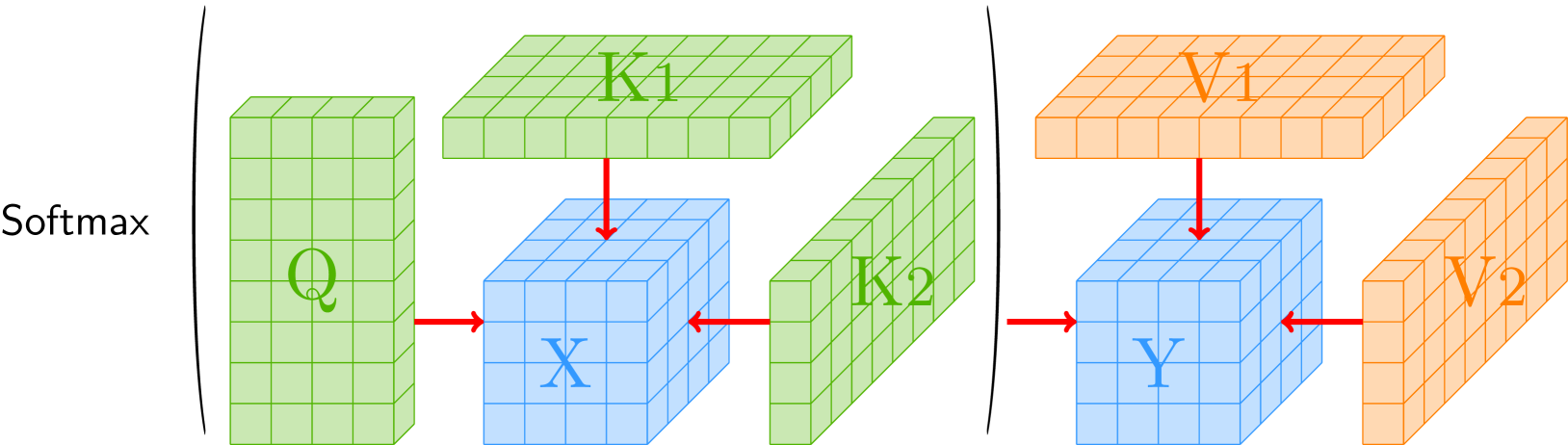
Tensor Attention Training: Provably Efficient Learning of Higher-order Transformers
Jiuxiang Gu, Yingyu Liang, Zhenmei Shi, Zhao Song, Yufa Zhou
Tensor Attention, a multi-view attention that is able to capture high-order correlations among multiple modalities, can overcome the representational limitations of classical matrix attention. However, the $Omega(n^3)$ time complexity of tensor attention poses a significant obstacle to its practical implementation in transformers, where $n$ is the input sequence length. In this work, we prove that the backward gradient of tensor attention training can be computed in almost linear $n^{1+o(1)}$ time, the same complexity as its forward computation under a bounded entries assumption. We provide a closed-form solution for the gradient and propose a fast computation method utilizing polynomial approximation methods and tensor algebraic tricks. Furthermore, we prove the necessity and tightness of our assumption through hardness analysis, showing that slightly weakening it renders the gradient problem unsolvable in truly subcubic time. Our theoretical results establish the feasibility of efficient higher-order transformer training and may facilitate practical applications of tensor attention architectures.
Read more5/28/2024

0
New!SGFormer: Single-Layer Graph Transformers with Approximation-Free Linear Complexity
Qitian Wu, Kai Yang, Hengrui Zhang, David Wipf, Junchi Yan
Learning representations on large graphs is a long-standing challenge due to the inter-dependence nature. Transformers recently have shown promising performance on small graphs thanks to its global attention for capturing all-pair interactions beyond observed structures. Existing approaches tend to inherit the spirit of Transformers in language and vision tasks, and embrace complicated architectures by stacking deep attention-based propagation layers. In this paper, we attempt to evaluate the necessity of adopting multi-layer attentions in Transformers on graphs, which considerably restricts the efficiency. Specifically, we analyze a generic hybrid propagation layer, comprised of all-pair attention and graph-based propagation, and show that multi-layer propagation can be reduced to one-layer propagation, with the same capability for representation learning. It suggests a new technical path for building powerful and efficient Transformers on graphs, particularly through simplifying model architectures without sacrificing expressiveness. As exemplified by this work, we propose a Simplified Single-layer Graph Transformers (SGFormer), whose main component is a single-layer global attention that scales linearly w.r.t. graph sizes and requires none of any approximation for accommodating all-pair interactions. Empirically, SGFormer successfully scales to the web-scale graph ogbn-papers100M, yielding orders-of-magnitude inference acceleration over peer Transformers on medium-sized graphs, and demonstrates competitiveness with limited labeled data.
Read more9/16/2024
1
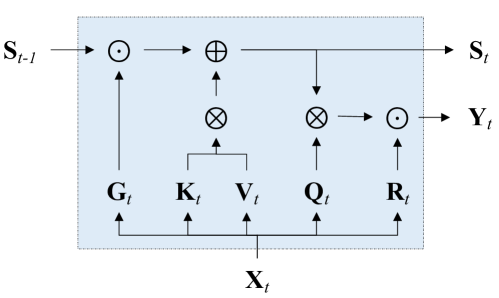
Gated Linear Attention Transformers with Hardware-Efficient Training
Songlin Yang, Bailin Wang, Yikang Shen, Rameswar Panda, Yoon Kim
Transformers with linear attention allow for efficient parallel training but can simultaneously be formulated as an RNN with 2D (matrix-valued) hidden states, thus enjoying linear-time inference complexity. However, linear attention generally underperforms ordinary softmax attention. Moreover, current implementations of linear attention lack I/O-awareness and are thus slower than highly optimized implementations of softmax attention. This work describes a hardware-efficient algorithm for linear attention that trades off memory movement against parallelizability. The resulting implementation, dubbed FLASHLINEARATTENTION, is faster than FLASHATTENTION-2 (Dao, 2023) as a standalone layer even on short sequence lengths (e.g., 1K). We then generalize this algorithm to a more expressive variant of linear attention with data-dependent gates. When used as a replacement for the standard attention layer in Transformers, the resulting gated linear attention (GLA) Transformer is found to perform competitively against the LLaMA-architecture Transformer (Touvron et al., 2023) as well recent linear-time-inference baselines such as RetNet (Sun et al., 2023a) and Mamba (Gu & Dao, 2023) on moderate-scale language modeling experiments. GLA Transformer is especially effective at length generalization, enabling a model trained on 2K to generalize to sequences longer than 20K without significant perplexity degradations. For training speed, the GLA Transformer has higher throughput than a similarly-sized Mamba model.
Read more6/6/2024