Gated Linear Attention Transformers with Hardware-Efficient Training
2312.06635
2
0
Abstract
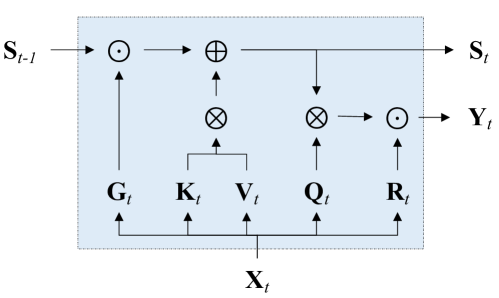
Transformers with linear attention allow for efficient parallel training but can simultaneously be formulated as an RNN with 2D (matrix-valued) hidden states, thus enjoying linear-time inference complexity. However, linear attention generally underperforms ordinary softmax attention. Moreover, current implementations of linear attention lack I/O-awareness and are thus slower than highly optimized implementations of softmax attention. This work describes a hardware-efficient algorithm for linear attention that trades off memory movement against parallelizability. The resulting implementation, dubbed FLASHLINEARATTENTION, is faster than FLASHATTENTION-2 (Dao, 2023) as a standalone layer even on short sequence lengths (e.g., 1K). We then generalize this algorithm to a more expressive variant of linear attention with data-dependent gates. When used as a replacement for the standard attention layer in Transformers, the resulting gated linear attention (GLA) Transformer is found to perform competitively against the LLaMA-architecture Transformer (Touvron et al., 2023) as well recent linear-time-inference baselines such as RetNet (Sun et al., 2023a) and Mamba (Gu & Dao, 2023) on moderate-scale language modeling experiments. GLA Transformer is especially effective at length generalization, enabling a model trained on 2K to generalize to sequences longer than 20K without significant perplexity degradations. For training speed, the GLA Transformer has higher throughput than a similarly-sized Mamba model.
Create account to get full access
Overview
- This paper introduces a new type of attention mechanism called Gated Linear Attention Transformers (GLAT), which aims to improve the efficiency of transformers for hardware-constrained applications.
- The key innovations include a gated linear attention mechanism that reduces the computational complexity of attention, and a hardware-aware training approach to further optimize the model for efficient inference.
- The proposed GLAT model achieves strong performance on several benchmark tasks while being significantly more efficient than standard transformer architectures.
Plain English Explanation
The Gated Linear Attention Transformers (GLAT) paper addresses a common challenge in machine learning: how to build powerful yet efficient models that can run well on hardware with limited resources, such as smartphones or edge devices.
Transformers have become a dominant architecture for many AI tasks, but they can be computationally expensive due to the attention mechanism at their core. The authors of this paper set out to develop a new type of attention that maintains the effectiveness of transformers while dramatically reducing the computational cost.
Their key insight was to create a "gated linear attention" mechanism. This simplifies the attention calculations, making them linear in complexity rather than quadratic. This allows the GLAT model to be much more efficient than standard transformers, without sacrificing performance.
Additionally, the researchers used a "hardware-aware training" approach to further optimize the model for efficient inference on real-world hardware. This involves considering factors like memory usage and latency during the training process, not just final accuracy.
The end result is a GLAT model that can match or exceed the performance of transformer models on benchmarks, while being significantly faster and more compact. This makes GLAT a promising candidate for deploying powerful AI on resource-constrained devices, like smartphones or Internet of Things (IoT) sensors.
Technical Explanation
The core innovation in this paper is the Gated Linear Attention (GLA) mechanism, which the authors use to build their Gated Linear Attention Transformers (GLAT) model.
Typical transformer models use a quadratic-complexity attention mechanism, which can be computationally expensive, especially for large input sequences. The GLA module replaces this with a linear-complexity alternative.
GLA works by decomposing the attention computation into two steps: a linear projection to a lower-dimensional space, followed by a gating mechanism that selectively attends to the most relevant features. This gating function is trained end-to-end alongside the rest of the model.
In addition to the GLA module, the authors also introduce a "hardware-aware training" approach. This involves optimizing the model not just for accuracy, but also for hardware-relevant metrics like latency and memory usage during the training process. This helps ensure the final model is well-suited for efficient inference on target hardware.
Experiments on language modeling, machine translation, and image classification tasks show that GLAT models can match or outperform standard transformer architectures, while being significantly more efficient. For example, on the WMT'14 English-German translation task, GLAT achieved the same accuracy as a transformer baseline but with a 4x reduction in FLOPS and 2x reduction in parameters.
Critical Analysis
The authors provide a comprehensive analysis of the GLAT model's performance and efficiency across several benchmark tasks. The results demonstrate the effectiveness of the proposed gated linear attention mechanism and hardware-aware training approach.
However, the paper does not address some potential limitations or areas for further research. For instance, it would be interesting to see how GLAT performs on more complex or domain-specific tasks beyond the standard benchmarks. Additionally, the authors do not explore the model's robustness to distribution shift or its ability to generalize to novel inputs.
Another area for further investigation could be the interpretability of the gating mechanism within the GLA module. Understanding how the model selectively attends to features could provide insights into its inner workings and decision-making process.
Finally, while the hardware-aware training approach is a novel and promising idea, the paper lacks a deeper exploration of its impact on the model's deployability and real-world performance. Expanding on these practical considerations could strengthen the paper's overall contribution.
Overall, the GLAT model represents an important step forward in developing efficient transformer-based architectures. The ideas presented in this paper could have significant implications for deploying powerful AI systems on resource-constrained hardware, such as edge devices and IoT applications.
Conclusion
The Gated Linear Attention Transformers (GLAT) paper introduces a novel attention mechanism and a hardware-aware training approach to create efficient transformer-based models. The key innovations include a linear-complexity gated attention module and an optimization process that considers hardware constraints during training.
Experimental results demonstrate that GLAT can achieve strong performance on a variety of benchmark tasks while being significantly more efficient than standard transformer architectures. This makes GLAT a promising candidate for deploying powerful AI on resource-constrained devices, such as smartphones, edge computing platforms, and IoT sensors.
While the paper provides a comprehensive technical evaluation, there are opportunities for further research to explore the model's robustness, interpretability, and real-world deployability. Nonetheless, the ideas presented in this work represent an important advancement in the field of efficient deep learning, with the potential to unlock new applications of AI in hardware-limited environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
ViG: Linear-complexity Visual Sequence Learning with Gated Linear Attention
Bencheng Liao, Xinggang Wang, Lianghui Zhu, Qian Zhang, Chang Huang
0
0
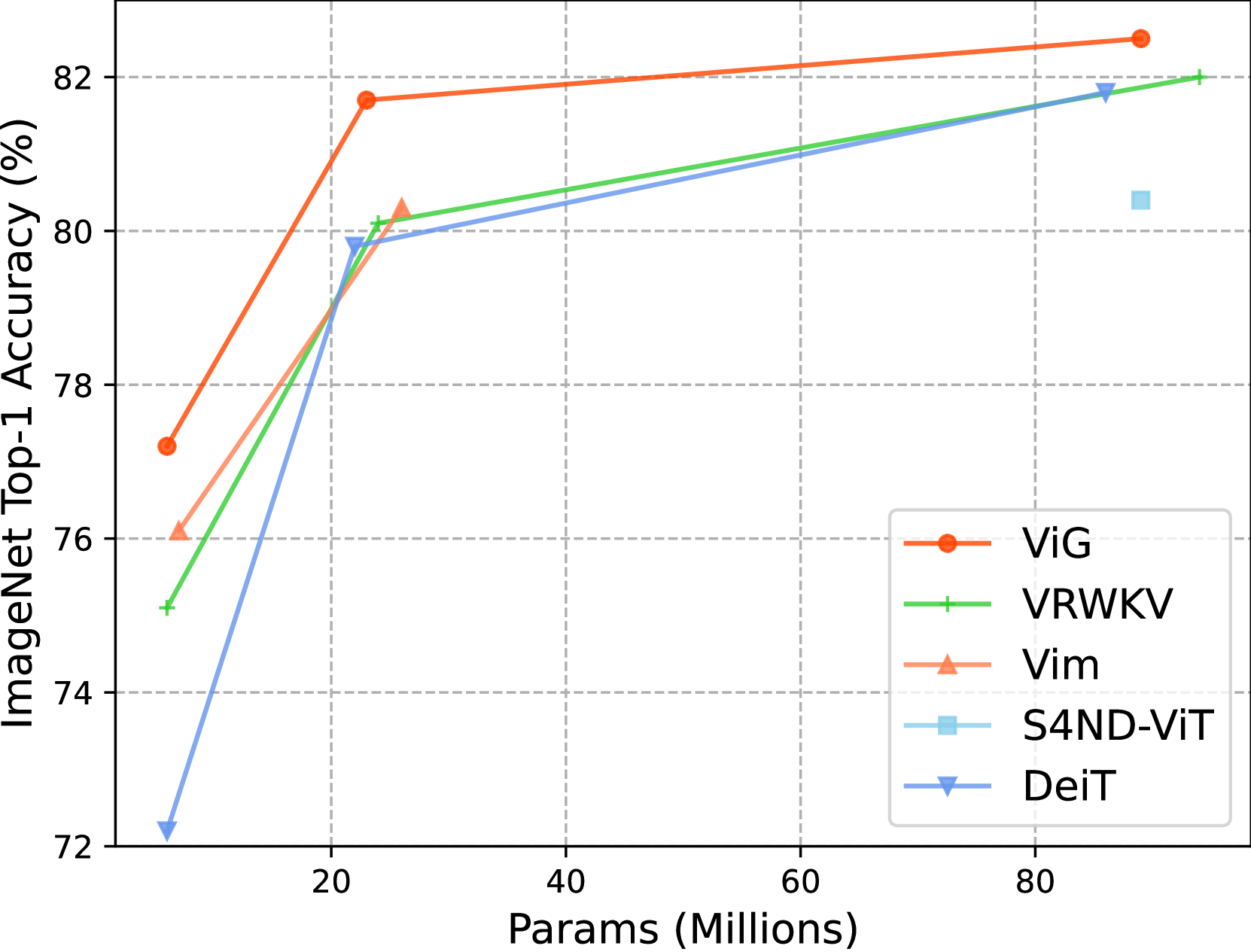
Recently, linear complexity sequence modeling networks have achieved modeling capabilities similar to Vision Transformers on a variety of computer vision tasks, while using fewer FLOPs and less memory. However, their advantage in terms of actual runtime speed is not significant. To address this issue, we introduce Gated Linear Attention (GLA) for vision, leveraging its superior hardware-awareness and efficiency. We propose direction-wise gating to capture 1D global context through bidirectional modeling and a 2D gating locality injection to adaptively inject 2D local details into 1D global context. Our hardware-aware implementation further merges forward and backward scanning into a single kernel, enhancing parallelism and reducing memory cost and latency. The proposed model, ViG, offers a favorable trade-off in accuracy, parameters, and FLOPs on ImageNet and downstream tasks, outperforming popular Transformer and CNN-based models. Notably, ViG-S matches DeiT-B's accuracy while using only 27% of the parameters and 20% of the FLOPs, running 2$times$ faster on $224times224$ images. At $1024times1024$ resolution, ViG-T uses 5.2$times$ fewer FLOPs, saves 90% GPU memory, runs 4.8$times$ faster, and achieves 20.7% higher top-1 accuracy than DeiT-T. These results position ViG as an efficient and scalable solution for visual representation learning. Code is available at url{https://github.com/hustvl/ViG}.
5/30/2024

Lean Attention: Hardware-Aware Scalable Attention Mechanism for the Decode-Phase of Transformers
Rya Sanovar, Srikant Bharadwaj, Renee St. Amant, Victor Ruhle, Saravan Rajmohan
0
0
Transformer-based models have emerged as one of the most widely used architectures for natural language processing, natural language generation, and image generation. The size of the state-of-the-art models has increased steadily reaching billions of parameters. These huge models are memory hungry and incur significant inference latency even on cutting edge AI-accelerators, such as GPUs. Specifically, the time and memory complexity of the attention operation is quadratic in terms of the total context length, i.e., prompt and output tokens. Thus, several optimizations such as key-value tensor caching and FlashAttention computation have been proposed to deliver the low latency demands of applications relying on such large models. However, these techniques do not cater to the computationally distinct nature of different phases during inference. To that end, we propose LeanAttention, a scalable technique of computing self-attention for the token-generation phase (decode-phase) of decoder-only transformer models. LeanAttention enables scaling the attention mechanism implementation for the challenging case of long context lengths by re-designing the execution flow for the decode-phase. We identify that the associative property of online softmax can be treated as a reduction operation thus allowing us to parallelize the attention computation over these large context lengths. We extend the stream-K style reduction of tiled calculation to self-attention to enable parallel computation resulting in an average of 2.6x attention execution speedup over FlashAttention-2 and up to 8.33x speedup for 512k context lengths.
5/20/2024
🤷
Parallelizing Linear Transformers with the Delta Rule over Sequence Length
Songlin Yang, Bailin Wang, Yu Zhang, Yikang Shen, Yoon Kim
0
0
Transformers with linear attention (i.e., linear transformers) and state-space models have recently been suggested as a viable linear-time alternative to transformers with softmax attention. However, these models still underperform transformers especially on tasks that require in-context retrieval. While more expressive variants of linear transformers which replace the additive outer-product update in linear transformers with the delta rule have been found to be more effective at associative recall, existing algorithms for training such models do not parallelize over sequence length and are thus inefficient to train on modern hardware. This work describes a hardware-efficient algorithm for training linear transformers with the delta rule, which exploits a memory-efficient representation for computing products of Householder matrices. This algorithm allows us to scale up DeltaNet to standard language modeling settings. We train a 1.3B model for 100B tokens and find that it outperforms recent linear-time baselines such as Mamba and GLA in terms of perplexity and zero-shot performance on downstream tasks (including on tasks that focus on recall). We also experiment with two hybrid models which combine DeltaNet layers with (1) sliding-window attention layers every other layer or (2) two global attention layers, and find that these hybrid models outperform strong transformer baselines.
6/11/2024
A Unified Implicit Attention Formulation for Gated-Linear Recurrent Sequence Models
Itamar Zimerman, Ameen Ali, Lior Wolf
0
0
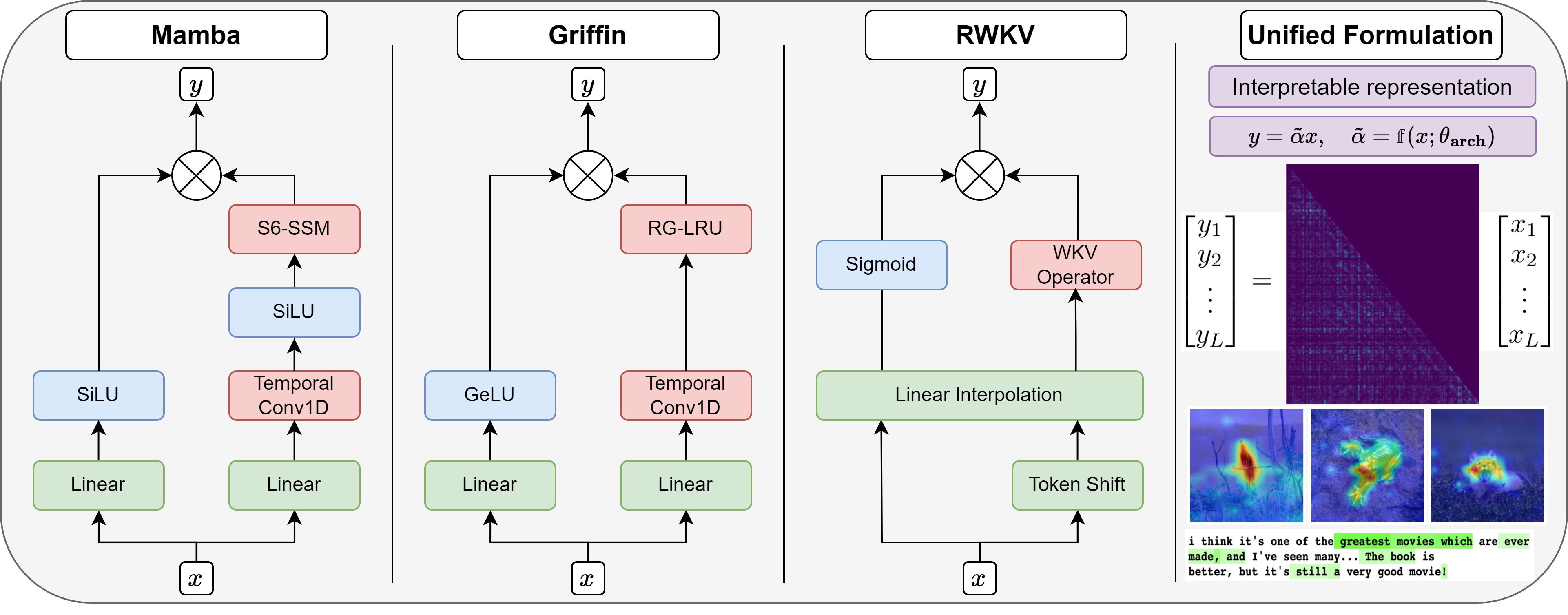
Recent advances in efficient sequence modeling have led to attention-free layers, such as Mamba, RWKV, and various gated RNNs, all featuring sub-quadratic complexity in sequence length and excellent scaling properties, enabling the construction of a new type of foundation models. In this paper, we present a unified view of these models, formulating such layers as implicit causal self-attention layers. The formulation includes most of their sub-components and is not limited to a specific part of the architecture. The framework compares the underlying mechanisms on similar grounds for different layers and provides a direct means for applying explainability methods. Our experiments show that our attention matrices and attribution method outperform an alternative and a more limited formulation that was recently proposed for Mamba. For the other architectures for which our method is the first to provide such a view, our method is effective and competitive in the relevant metrics compared to the results obtained by state-of-the-art transformer explainability methods. Our code is publicly available.
5/28/2024