Multi-Modal Adapter for Vision-Language Models

0

Sign in to get full access
Overview
- The paper proposes a "Multi-Modal Adapter" (MMA) to efficiently adapt pre-trained vision-language models to new tasks.
- MMA uses a lightweight adapter module that can be trained on top of a frozen pre-trained model, requiring minimal additional parameters.
- Experiments show MMA can match or exceed the performance of fine-tuning the entire model while being more data-efficient.
Plain English Explanation
The paper introduces a technique called "Multi-Modal Adapter" (MMA) that can help vision-language models, like the popular CLIP model, adapt to new tasks and datasets without having to completely retrain the entire model.
Vision-language models are powerful AI models that can understand and connect information from both images and text. However, fully retraining these large, complex models from scratch for every new task can be very time-consuming and data-intensive.
MMA provides a more efficient alternative. It uses a lightweight "adapter" module that can be trained on top of the pre-trained model. This adapter learns the new task while keeping the original model's core knowledge frozen. As a result, MMA can match or even exceed the performance of full fine-tuning, but with much less additional training data required.
This ability to adapt pre-trained models to new contexts in a data-efficient way is an important advancement, as it can make vision-language AI systems more practical and accessible for a wider range of applications.
Technical Explanation
The paper proposes the Multi-Modal Adapter (MMA), a lightweight module that can be trained on top of a pre-trained vision-language model to adapt it to new tasks and datasets.
The key idea is to add a small adapter module to the pre-trained model, which consists of a few additional neural network layers. This adapter module is then trained on the new task, while the core pre-trained model parameters are kept frozen.
The authors show that this approach can match or exceed the performance of fine-tuning the entire pre-trained model, but with much fewer additional training samples required. Experiments are conducted on various vision-language benchmarks, including image-text retrieval and visual question answering.
The technical innovation of MMA lies in its design. The adapter module consists of residual connection blocks that allow it to effectively "plug into" the pre-trained model without disrupting its original knowledge. Additionally, the adapter leverages cross-modal attention to capture interactions between the visual and textual inputs.
By preserving the pre-trained model's core capabilities while only updating a small number of adapter parameters, MMA enables data-efficient transfer learning for vision-language tasks.
Critical Analysis
The paper provides a compelling approach to efficient adaptation of vision-language models. The key strengths are:
- Data Efficiency: MMA requires significantly less additional training data compared to full fine-tuning, which is an important practical advantage.
- Preserving Pre-trained Knowledge: The ability to keep the core pre-trained model frozen helps retain its general capabilities.
- Modular Design: The adapter module can be easily plugged into different pre-trained models, making the approach flexible and extensible.
Some potential limitations and areas for further research include:
- Task Specificity: While MMA is shown to work well on the tested benchmarks, its generalization to a wider range of tasks remains to be explored.
- Scalability: The paper does not investigate how the approach scales as the pre-trained model size and complexity increases.
- Interpretability: The paper does not provide much insight into what the adapter module is learning and how it interacts with the pre-trained model.
Overall, the Multi-Modal Adapter is a promising technique that advances the field of data-efficient transfer learning for vision-language AI systems.
Conclusion
The paper introduces the Multi-Modal Adapter (MMA), a novel approach to efficiently adapt pre-trained vision-language models to new tasks and datasets. By training a lightweight adapter module on top of a frozen pre-trained model, MMA can match or exceed the performance of full fine-tuning while requiring significantly less additional training data.
This data-efficient transfer learning capability is an important step forward, as it can make powerful vision-language AI systems more accessible and applicable to a wider range of real-world scenarios. The modular and flexible design of MMA also suggests that it could be a valuable tool for future research and development in this rapidly advancing field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multi-Modal Adapter for Vision-Language Models
Dominykas Seputis, Serghei Mihailov, Soham Chatterjee, Zehao Xiao
Large pre-trained vision-language models, such as CLIP, have demonstrated state-of-the-art performance across a wide range of image classification tasks, without requiring retraining. Few-shot CLIP is competitive with existing specialized architectures that were trained on the downstream tasks. Recent research demonstrates that the performance of CLIP can be further improved using lightweight adaptation approaches. However, previous methods adapt different modalities of the CLIP model individually, ignoring the interactions and relationships between visual and textual representations. In this work, we propose Multi-Modal Adapter, an approach for Multi-Modal adaptation of CLIP. Specifically, we add a trainable Multi-Head Attention layer that combines text and image features to produce an additive adaptation of both. Multi-Modal Adapter demonstrates improved generalizability, based on its performance on unseen classes compared to existing adaptation methods. We perform additional ablations and investigations to validate and interpret the proposed approach.
Read more9/6/2024

0
CapS-Adapter: Caption-based MultiModal Adapter in Zero-Shot Classification
Qijie Wang, Guandu Liu, Bin Wang
Recent advances in vision-language foundational models, such as CLIP, have demonstrated significant strides in zero-shot classification. However, the extensive parameterization of models like CLIP necessitates a resource-intensive fine-tuning process. In response, TIP-Adapter and SuS-X have introduced training-free methods aimed at bolstering the efficacy of downstream tasks. While these approaches incorporate support sets to maintain data distribution consistency between knowledge cache and test sets, they often fall short in terms of generalization on the test set, particularly when faced with test data exhibiting substantial distributional variations. In this work, we present CapS-Adapter, an innovative method that employs a caption-based support set, effectively harnessing both image and caption features to exceed existing state-of-the-art techniques in training-free scenarios. CapS-Adapter adeptly constructs support sets that closely mirror target distributions, utilizing instance-level distribution features extracted from multimodal large models. By leveraging CLIP's single and cross-modal strengths, CapS-Adapter enhances predictive accuracy through the use of multimodal support sets. Our method achieves outstanding zero-shot classification results across 19 benchmark datasets, improving accuracy by 2.19% over the previous leading method. Our contributions are substantiated through extensive validation on multiple benchmark datasets, demonstrating superior performance and robust generalization capabilities. Our code is made publicly available at https://github.com/WLuLi/CapS-Adapter.
Read more5/28/2024
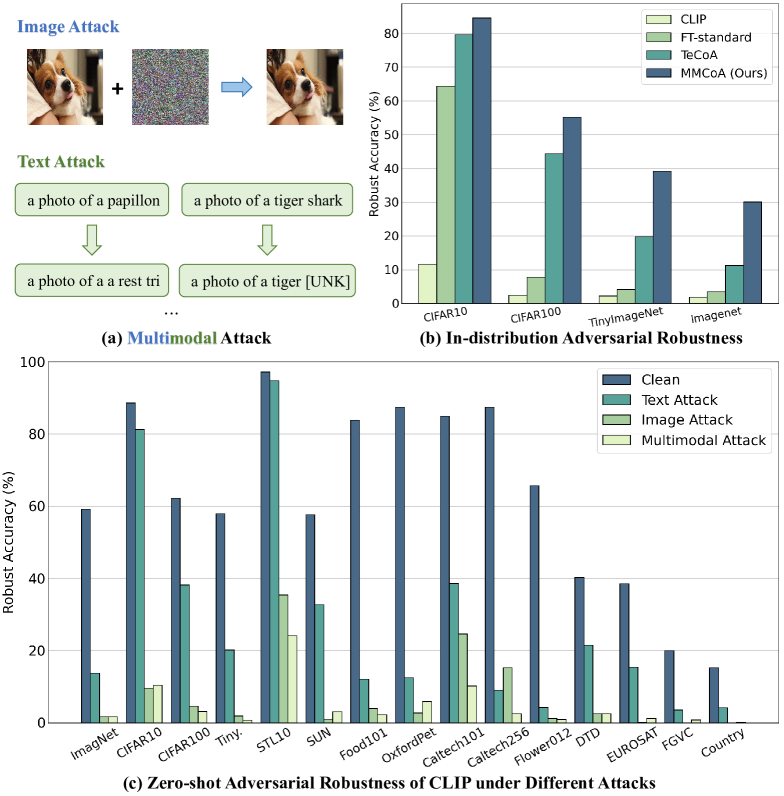
0
Revisiting the Adversarial Robustness of Vision Language Models: a Multimodal Perspective
Wanqi Zhou, Shuanghao Bai, Qibin Zhao, Badong Chen
Pretrained vision-language models (VLMs) like CLIP have shown impressive generalization performance across various downstream tasks, yet they remain vulnerable to adversarial attacks. While prior research has primarily concentrated on improving the adversarial robustness of image encoders to guard against attacks on images, the exploration of text-based and multimodal attacks has largely been overlooked. In this work, we initiate the first known and comprehensive effort to study adapting vision-language models for adversarial robustness under the multimodal attack. Firstly, we introduce a multimodal attack strategy and investigate the impact of different attacks. We then propose a multimodal contrastive adversarial training loss, aligning the clean and adversarial text embeddings with the adversarial and clean visual features, to enhance the adversarial robustness of both image and text encoders of CLIP. Extensive experiments on 15 datasets across two tasks demonstrate that our method significantly improves the adversarial robustness of CLIP. Interestingly, we find that the model fine-tuned against multimodal adversarial attacks exhibits greater robustness than its counterpart fine-tuned solely against image-based attacks, even in the context of image attacks, which may open up new possibilities for enhancing the security of VLMs.
Read more7/18/2024

0
Multi-modal Attribute Prompting for Vision-Language Models
Xin Liu, Jiamin Wu, and Wenfei Yang, Xu Zhou, Tianzhu Zhang
Pre-trained Vision-Language Models (VLMs), like CLIP, exhibit strong generalization ability to downstream tasks but struggle in few-shot scenarios. Existing prompting techniques primarily focus on global text and image representations, yet overlooking multi-modal attribute characteristics. This limitation hinders the model's ability to perceive fine-grained visual details and restricts its generalization ability to a broader range of unseen classes. To address this issue, we propose a Multi-modal Attribute Prompting method (MAP) by jointly exploring textual attribute prompting, visual attribute prompting, and attribute-level alignment. The proposed MAP enjoys several merits. First, we introduce learnable visual attribute prompts enhanced by textual attribute semantics to adaptively capture visual attributes for images from unknown categories, boosting fine-grained visual perception capabilities for CLIP. Second, the proposed attribute-level alignment complements the global alignment to enhance the robustness of cross-modal alignment for open-vocabulary objects. To our knowledge, this is the first work to establish cross-modal attribute-level alignment for CLIP-based few-shot adaptation. Extensive experimental results on 11 datasets demonstrate that our method performs favorably against state-of-the-art approaches.
Read more7/12/2024