Revisiting the Adversarial Robustness of Vision Language Models: a Multimodal Perspective
2404.19287
0
0
Abstract
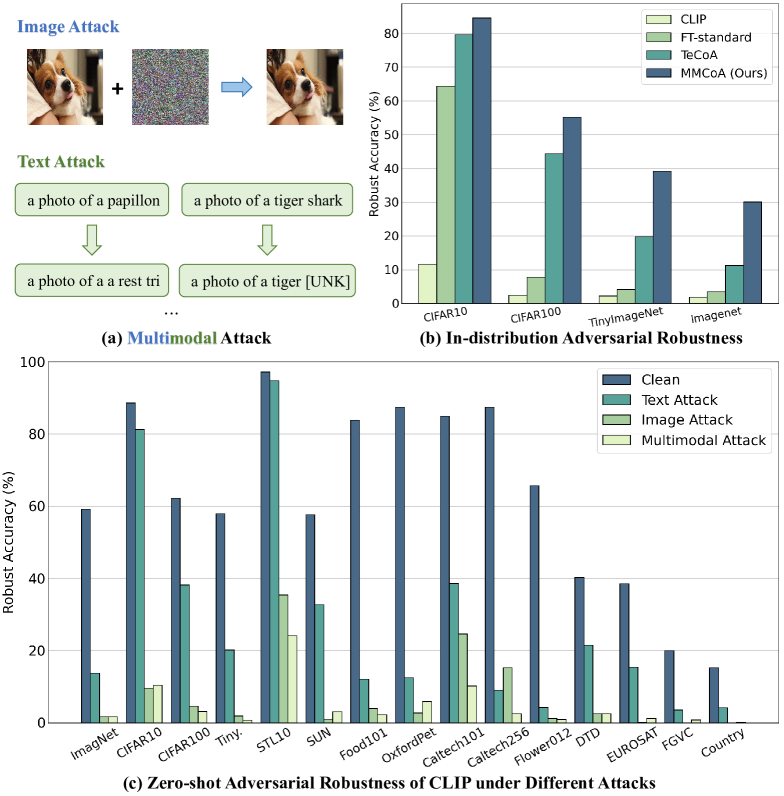
Pretrained vision-language models (VLMs) like CLIP have shown impressive generalization performance across various downstream tasks, yet they remain vulnerable to adversarial attacks. While prior research has primarily concentrated on improving the adversarial robustness of image encoders to guard against attacks on images, the exploration of text-based and multimodal attacks has largely been overlooked. In this work, we initiate the first known and comprehensive effort to study adapting vision-language models for adversarial robustness under the multimodal attack. Firstly, we introduce a multimodal attack strategy and investigate the impact of different attacks. We then propose a multimodal contrastive adversarial training loss, aligning the clean and adversarial text embeddings with the adversarial and clean visual features, to enhance the adversarial robustness of both image and text encoders of CLIP. Extensive experiments on 15 datasets across two tasks demonstrate that our method significantly improves the adversarial robustness of CLIP. Interestingly, we find that the model fine-tuned against multimodal adversarial attacks exhibits greater robustness than its counterpart fine-tuned solely against image-based attacks, even in the context of image attacks, which may open up new possibilities for enhancing the security of VLMs.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores the adversarial robustness of vision-language models, which are AI systems that can process and understand both visual and textual information.
- The researchers investigate how these models handle multimodal (visual and textual) attacks, where the adversary aims to fool the model by manipulating both the image and the accompanying text.
- The study provides insights into the vulnerabilities of state-of-the-art vision-language models and offers strategies for improving their robustness against such attacks.
Plain English Explanation
Vision-language models are a type of artificial intelligence (AI) system that can understand and process both images and text. These models are used in various applications, such as image captioning, visual question answering, and multimodal information retrieval.
However, these models can be vulnerable to adversarial attacks, where someone tries to trick the model by making small, barely noticeable changes to the input data. In this paper, the researchers explore how vision-language models respond to multimodal attacks, where the adversary manipulates both the image and the accompanying text to confuse the model.
The researchers tested different state-of-the-art vision-language models and found that they are indeed susceptible to these multimodal attacks. They discovered that the models can be fooled by subtle changes to the image or text, causing the model to misclassify the input or provide an incorrect response.
To address this issue, the researchers propose strategies for improving the adversarial robustness of vision-language models. This could involve techniques like Adversarial Training, where the model is trained on adversarial examples to become more resilient, or Multimodal Fusion, which could help the model better integrate and process information from both images and text.
By understanding the vulnerabilities of vision-language models, researchers can develop more robust and reliable AI systems that can better handle real-world challenges, such as Designing Scalable Vision Models and Exploring the Frontier of Vision-Language Models.
Technical Explanation
The paper first reviews the related work on adversarial attacks and defenses for both unimodal (single-modality) and multimodal AI systems. It highlights the importance of understanding the vulnerabilities of vision-language models, which combine both visual and textual information processing capabilities.
The researchers then design a set of multimodal attacks, where they manipulate both the image and the accompanying text to fool the target vision-language model. They evaluate the effectiveness of these attacks on several state-of-the-art models, including LXMERT, VisualBERT, and VL-BERT.
The results show that the tested models are indeed vulnerable to these multimodal attacks, with the models failing to correctly classify the input or provide the expected response. The researchers analyze the factors that contribute to the models' susceptibility, such as the models' reliance on certain visual or textual features and the lack of robust multimodal fusion strategies.
To address these vulnerabilities, the paper discusses potential strategies for improving the adversarial robustness of vision-language models. These include Concept-Based Analysis, where the model's internal representations are examined to identify and strengthen its understanding of relevant visual and textual concepts.
Critical Analysis
The paper provides valuable insights into the adversarial vulnerabilities of state-of-the-art vision-language models. However, the researchers acknowledge that their study is limited to a specific set of models and attack scenarios. Further research is needed to understand the broader implications and generalizability of these findings.
Additionally, the paper does not delve into the potential societal impacts of these vulnerabilities, such as how they could be exploited in real-world applications or the ethical considerations around the development of more robust vision-language models.
While the proposed strategies for improving adversarial robustness are promising, the paper does not provide a comprehensive evaluation of their effectiveness. More extensive testing and validation would be necessary to assess the practical feasibility and impact of these approaches.
Conclusion
This paper highlights the need for continued research on the adversarial robustness of vision-language models. By understanding the vulnerabilities of these models to multimodal attacks, researchers can develop more robust and reliable AI systems that can better handle complex, real-world challenges.
The insights and strategies presented in this paper contribute to the ongoing efforts to Explore the Frontier of Vision-Language Models and Design Scalable Vision Models that are both capable and secure. As the field of multimodal AI continues to advance, addressing these adversarial concerns will be crucial for the successful deployment of these technologies in various applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
New!Adversarial Robustness for Visual Grounding of Multimodal Large Language Models
Kuofeng Gao, Yang Bai, Jiawang Bai, Yong Yang, Shu-Tao Xia
0
0
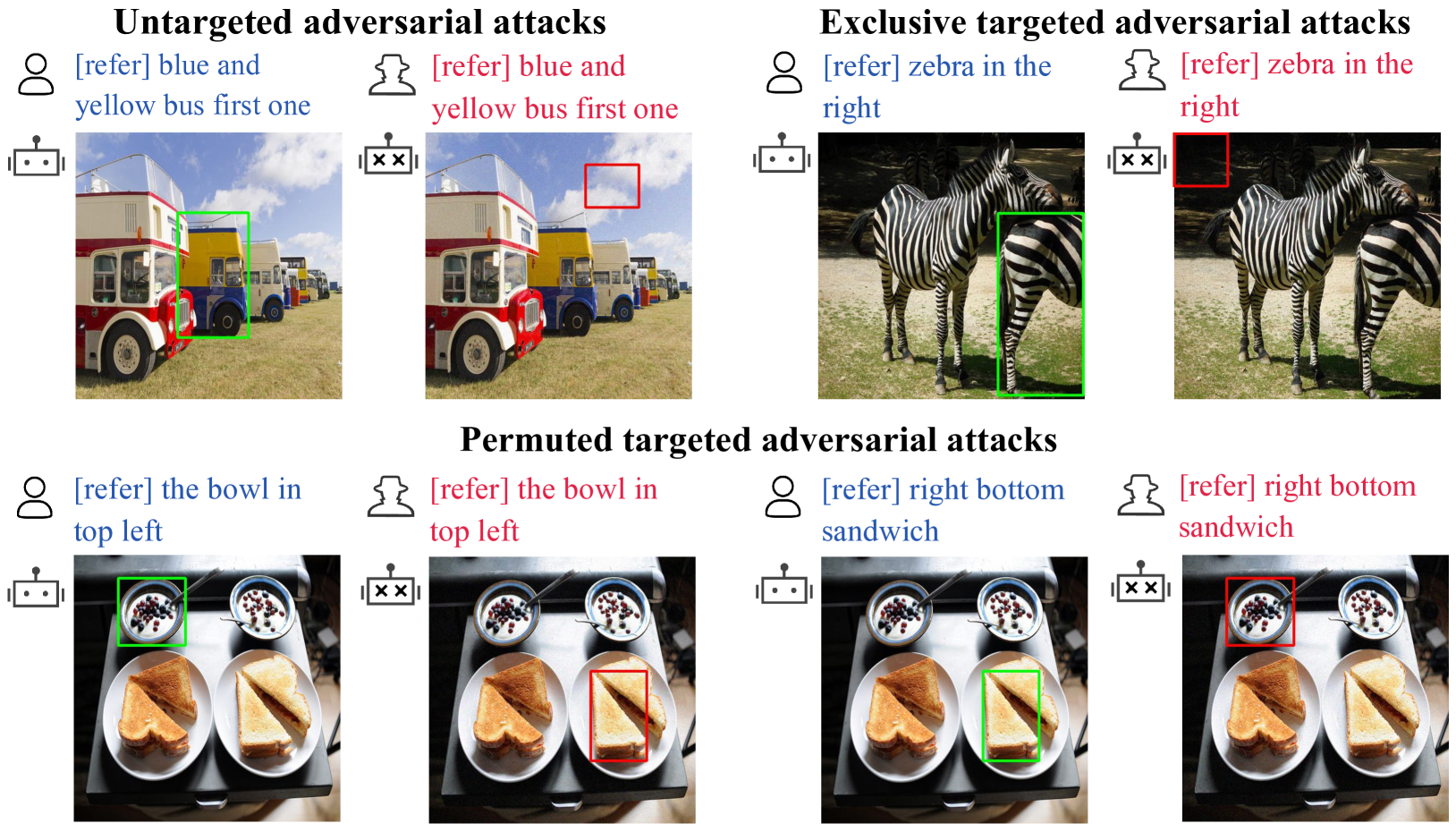
Multi-modal Large Language Models (MLLMs) have recently achieved enhanced performance across various vision-language tasks including visual grounding capabilities. However, the adversarial robustness of visual grounding remains unexplored in MLLMs. To fill this gap, we use referring expression comprehension (REC) as an example task in visual grounding and propose three adversarial attack paradigms as follows. Firstly, untargeted adversarial attacks induce MLLMs to generate incorrect bounding boxes for each object. Besides, exclusive targeted adversarial attacks cause all generated outputs to the same target bounding box. In addition, permuted targeted adversarial attacks aim to permute all bounding boxes among different objects within a single image. Extensive experiments demonstrate that the proposed methods can successfully attack visual grounding capabilities of MLLMs. Our methods not only provide a new perspective for designing novel attacks but also serve as a strong baseline for improving the adversarial robustness for visual grounding of MLLMs.
5/17/2024
Demonstration of an Adversarial Attack Against a Multimodal Vision Language Model for Pathology Imaging
Poojitha Thota, Jai Prakash Veerla, Partha Sai Guttikonda, Mohammad S. Nasr, Shirin Nilizadeh, Jacob M. Luber
0
0
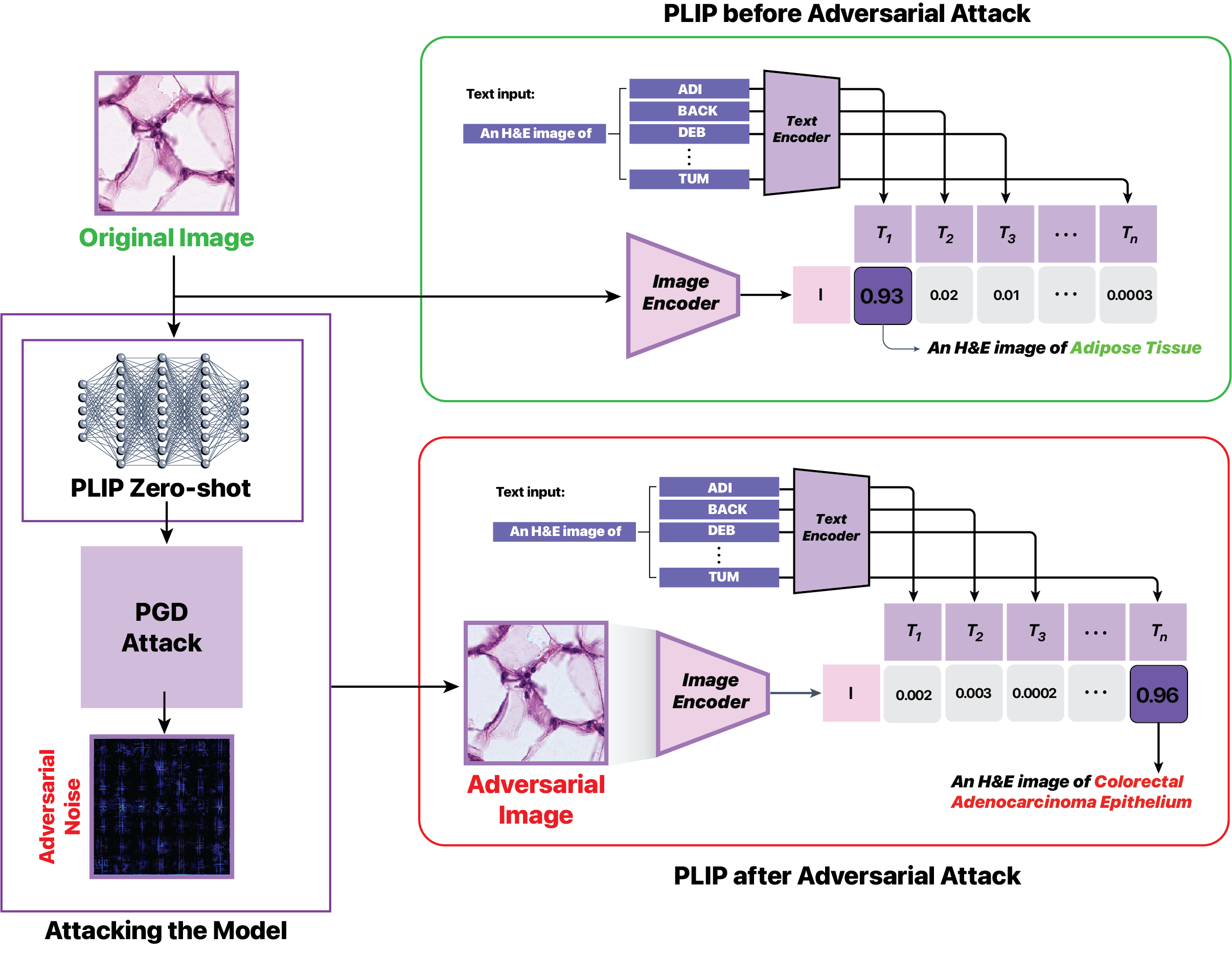
In the context of medical artificial intelligence, this study explores the vulnerabilities of the Pathology Language-Image Pretraining (PLIP) model, a Vision Language Foundation model, under targeted attacks. Leveraging the Kather Colon dataset with 7,180 H&E images across nine tissue types, our investigation employs Projected Gradient Descent (PGD) adversarial perturbation attacks to induce misclassifications intentionally. The outcomes reveal a 100% success rate in manipulating PLIP's predictions, underscoring its susceptibility to adversarial perturbations. The qualitative analysis of adversarial examples delves into the interpretability challenges, shedding light on nuanced changes in predictions induced by adversarial manipulations. These findings contribute crucial insights into the interpretability, domain adaptation, and trustworthiness of Vision Language Models in medical imaging. The study emphasizes the pressing need for robust defenses to ensure the reliability of AI models. The source codes for this experiment can be found at https://github.com/jaiprakash1824/VLM_Adv_Attack.
5/9/2024

Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs
Shengbang Tong, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, Saining Xie
0
0
Is vision good enough for language? Recent advancements in multimodal models primarily stem from the powerful reasoning abilities of large language models (LLMs). However, the visual component typically depends only on the instance-level contrastive language-image pre-training (CLIP). Our research reveals that the visual capabilities in recent multimodal LLMs (MLLMs) still exhibit systematic shortcomings. To understand the roots of these errors, we explore the gap between the visual embedding space of CLIP and vision-only self-supervised learning. We identify ''CLIP-blind pairs'' - images that CLIP perceives as similar despite their clear visual differences. With these pairs, we construct the Multimodal Visual Patterns (MMVP) benchmark. MMVP exposes areas where state-of-the-art systems, including GPT-4V, struggle with straightforward questions across nine basic visual patterns, often providing incorrect answers and hallucinated explanations. We further evaluate various CLIP-based vision-and-language models and found a notable correlation between visual patterns that challenge CLIP models and those problematic for multimodal LLMs. As an initial effort to address these issues, we propose a Mixture of Features (MoF) approach, demonstrating that integrating vision self-supervised learning features with MLLMs can significantly enhance their visual grounding capabilities. Together, our research suggests visual representation learning remains an open challenge, and accurate visual grounding is crucial for future successful multimodal systems.
4/26/2024

Contrasting Intra-Modal and Ranking Cross-Modal Hard Negatives to Enhance Visio-Linguistic Compositional Understanding
Le Zhang, Rabiul Awal, Aishwarya Agrawal
0
0
Vision-Language Models (VLMs), such as CLIP, exhibit strong image-text comprehension abilities, facilitating advances in several downstream tasks such as zero-shot image classification, image-text retrieval, and text-to-image generation. However, the compositional reasoning abilities of existing VLMs remains subpar. The root of this limitation lies in the inadequate alignment between the images and captions in the pretraining datasets. Additionally, the current contrastive learning objective fails to focus on fine-grained grounding components like relations, actions, and attributes, resulting in bag-of-words representations. We introduce a simple and effective method to improve compositional reasoning in VLMs. Our method better leverages available datasets by refining and expanding the standard image-text contrastive learning framework. Our approach does not require specific annotations and does not incur extra parameters. When integrated with CLIP, our technique yields notable improvement over state-of-the-art baselines across five vision-language compositional benchmarks. We open-source our code at https://github.com/lezhang7/Enhance-FineGrained.
4/26/2024