Multi-modal Speech Transformer Decoders: When Do Multiple Modalities Improve Accuracy?

0

Sign in to get full access
Overview
- Examines when using multiple modalities (e.g., audio, video, text) can improve the accuracy of speech recognition models
- Compares the performance of a standard speech transformer decoder to a multi-modal speech transformer decoder
- Finds that multi-modal inputs can improve accuracy, but the benefits depend on factors like the task complexity and the quality of the individual modalities
Plain English Explanation
Multi-modal speech recognition systems use information from multiple sources, such as audio, video, and text, to improve the accuracy of transcribing speech. This paper investigates when multiple modalities can actually help improve accuracy.
The researchers compared a standard speech transformer decoder, which only uses audio input, to a multi-modal speech transformer decoder that can leverage additional modalities like video or text. They found that multi-modal inputs can enhance performance, but the benefits depend on factors like the complexity of the task and the quality of the individual modalities.
For example, video information may help improve accuracy for noisy audio, but if the video is low quality, it could actually hurt performance. The paper provides insights into how to effectively combine multiple modalities to get the best results for different speech recognition scenarios.
Technical Explanation
The paper proposes a multi-modal speech transformer decoder that can incorporate additional modalities beyond just audio input. They evaluate this model on a variety of speech recognition tasks and compare its performance to a standard audio-only speech transformer decoder.
The key components of their approach include:
- Multi-modal Encoder: Encodes audio, video, and/or text inputs into a joint representation
- Transformer Decoder: Decodes the multi-modal encoder outputs into a text transcript
- Task-specific Heads: Includes separate heads for different speech recognition tasks like transcription, translation, and dialogue
Through extensive experiments, the researchers found that multi-modal inputs can improve accuracy compared to audio-only in certain scenarios. The benefits depend on factors like:
- Task Complexity: Multi-modal inputs had the largest gains on more complex tasks like dialogue
- Modality Quality: If a modality (e.g. video) was low-quality, it could actually hurt performance
Overall, the paper provides a detailed analysis of when and how multi-modal speech recognition systems can outperform standard audio-only approaches.
Critical Analysis
The paper provides a thorough experimental evaluation of when multi-modal speech recognition can be beneficial. However, it does not deeply explore the limitations of their approach.
For example, the paper does not discuss how the multi-modal model would perform in real-world scenarios with unpredictable and noisy inputs across modalities. The experiments were conducted in relatively controlled lab settings, so further research is needed to understand the robustness of the multi-modal approach.
Additionally, the paper does not examine the computational costs and practical implementation challenges of deploying a multi-modal system at scale. The increased model complexity and need for multiple sensor inputs could create significant engineering hurdles.
Overall, the paper makes a strong case for the potential benefits of multi-modal speech recognition, but additional research is needed to fully understand the limitations and tradeoffs compared to simpler audio-only approaches.
Conclusion
This paper investigates when using multiple modalities, such as audio, video, and text, can improve the accuracy of speech recognition models. The key finding is that multi-modal inputs can enhance performance, but the benefits depend on factors like task complexity and the quality of the individual modalities.
The researchers developed a multi-modal speech transformer decoder and showed it can outperform a standard audio-only speech transformer in certain scenarios. This suggests that effectively combining multiple information sources has promise for advancing the state-of-the-art in speech recognition.
However, the paper also highlights that multi-modal approaches come with additional complexity and potential limitations that require further exploration. Ultimately, this work provides valuable insights into the tradeoffs of multi-modal speech recognition and sets the stage for future research in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Multi-modal Speech Transformer Decoders: When Do Multiple Modalities Improve Accuracy?
Yiwen Guan, Viet Anh Trinh, Vivek Voleti, Jacob Whitehill
Decoder-only discrete-token language models have recently achieved significant success in automatic speech recognition. However, systematic analyses of how different modalities impact performance in specific scenarios remain limited. In this paper, we investigate the effects of multiple modalities on recognition accuracy on both synthetic and real-world datasets. Our experiments suggest that: (1) Integrating more modalities can increase accuracy; in particular, our paper is, to our best knowledge, the first to show the benefit of combining audio, image context, and lip information; (2) Images as a supplementary modality for speech recognition provide the greatest benefit at moderate noise levels, moreover, they exhibit a different trend compared to inherently synchronized modalities like lip movements; (3) Performance improves on both synthetic and real-world datasets when the most relevant visual information is filtered as a preprocessing step.
Read more9/17/2024
📈
0
Multimodal Input Aids a Bayesian Model of Phonetic Learning
Sophia Zhi, Roger P. Levy, Stephan C. Meylan
One of the many tasks facing the typically-developing child language learner is learning to discriminate between the distinctive sounds that make up words in their native language. Here we investigate whether multimodal information--specifically adult speech coupled with video frames of speakers' faces--benefits a computational model of phonetic learning. We introduce a method for creating high-quality synthetic videos of speakers' faces for an existing audio corpus. Our learning model, when both trained and tested on audiovisual inputs, achieves up to a 8.1% relative improvement on a phoneme discrimination battery compared to a model trained and tested on audio-only input. It also outperforms the audio model by up to 3.9% when both are tested on audio-only data, suggesting that visual information facilitates the acquisition of acoustic distinctions. Visual information is especially beneficial in noisy audio environments, where an audiovisual model closes 67% of the loss in discrimination performance of the audio model in noise relative to a non-noisy environment. These results demonstrate that visual information benefits an ideal learner and illustrate some of the ways that children might be able to leverage visual cues when learning to discriminate speech sounds.
Read more7/24/2024
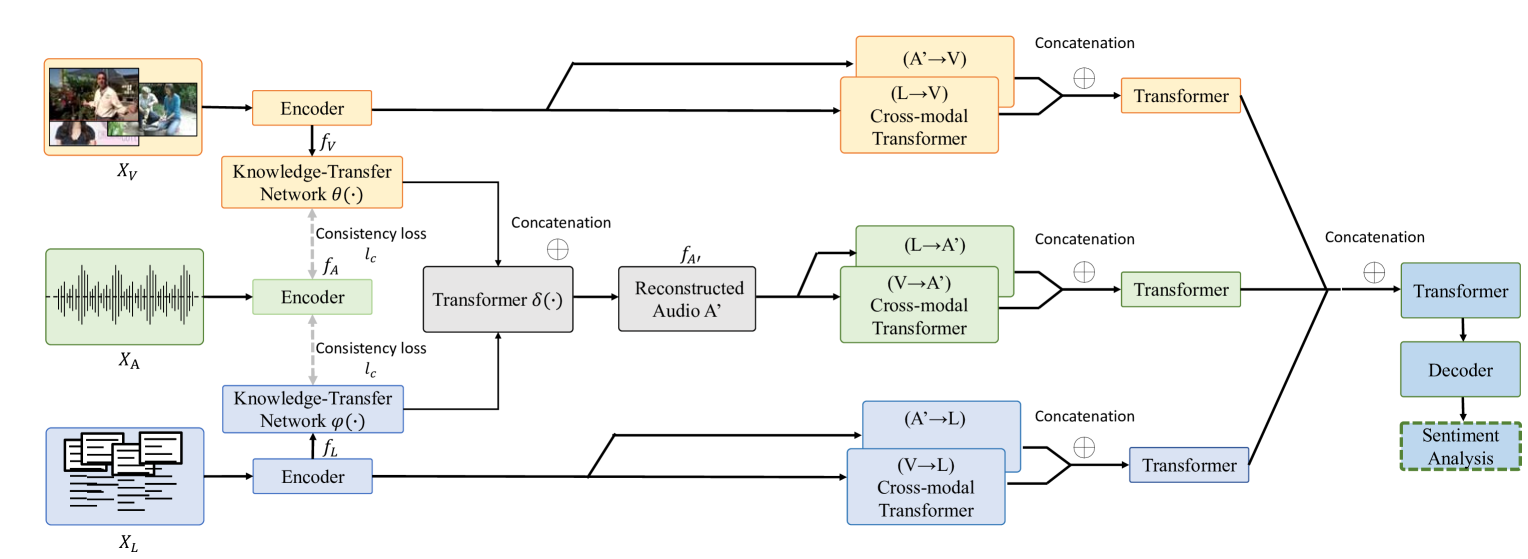
0
Multimodal Sentiment Analysis with Missing Modality: A Knowledge-Transfer Approach
Weide Liu, Huijing Zhan, Hao Chen, Fengmao Lv
Multimodal sentiment analysis aims to identify the emotions expressed by individuals through visual, language, and acoustic cues. However, most of the existing research efforts assume that all modalities are available during both training and testing, making their algorithms susceptible to the missing modality scenario. In this paper, we propose a novel knowledge-transfer network to translate between different modalities to reconstruct the missing audio modalities. Moreover, we develop a cross-modality attention mechanism to retain the maximal information of the reconstructed and observed modalities for sentiment prediction. Extensive experiments on three publicly available datasets demonstrate significant improvements over baselines and achieve comparable results to the previous methods with complete multi-modality supervision.
Read more7/12/2024
📈
0
Improving Multimodal Learning with Multi-Loss Gradient Modulation
Konstantinos Kontras, Christos Chatzichristos, Matthew Blaschko, Maarten De Vos
Learning from multiple modalities, such as audio and video, offers opportunities for leveraging complementary information, enhancing robustness, and improving contextual understanding and performance. However, combining such modalities presents challenges, especially when modalities differ in data structure, predictive contribution, and the complexity of their learning processes. It has been observed that one modality can potentially dominate the learning process, hindering the effective utilization of information from other modalities and leading to sub-optimal model performance. To address this issue the vast majority of previous works suggest to assess the unimodal contributions and dynamically adjust the training to equalize them. We improve upon previous work by introducing a multi-loss objective and further refining the balancing process, allowing it to dynamically adjust the learning pace of each modality in both directions, acceleration and deceleration, with the ability to phase out balancing effects upon convergence. We achieve superior results across three audio-video datasets: on CREMA-D, models with ResNet backbone encoders surpass the previous best by 1.9% to 12.4%, and Conformer backbone models deliver improvements ranging from 2.8% to 14.1% across different fusion methods. On AVE, improvements range from 2.7% to 7.7%, while on UCF101, gains reach up to 6.1%.
Read more5/14/2024