Multi-OCT-SelfNet: Integrating Self-Supervised Learning with Multi-Source Data Fusion for Enhanced Multi-Class Retinal Disease Classification

0

Sign in to get full access
Overview
- The paper proposes a novel deep learning model called "Multi-OCT-SelfNet" for enhanced multi-class retinal disease classification.
- It integrates self-supervised learning with multi-source data fusion to improve the model's performance.
- The model leverages Optical Coherence Tomography (OCT) images from multiple sources and combines them with self-supervised pretraining.
Plain English Explanation
The researchers developed a new artificial intelligence (AI) system that can better identify different eye diseases by analyzing Optical Coherence Tomography (OCT) scans of the retina.
The key idea is to combine two powerful machine learning techniques:
-
Self-supervised learning: The AI system first learns general visual features from the OCT scan data on its own, without being explicitly told what the images represent. This allows it to build a strong foundation of knowledge.
-
Data fusion: The system then takes OCT scans from multiple sources and combines them to further boost its performance. Using diverse data helps the AI become more robust and accurate at identifying different eye diseases.
By integrating these two approaches, the researchers were able to create an AI model called "Multi-OCT-SelfNet" that outperforms previous methods for classifying multiple types of retinal diseases from OCT images. This could lead to more accurate and reliable diagnosis of eye conditions, which is important for providing the best possible medical care.
Technical Explanation
The Multi-OCT-SelfNet model builds on recent advancements in self-supervised learning and multi-modal data fusion to enhance multi-class retinal disease classification from Optical Coherence Tomography (OCT) images.
The architecture of Multi-OCT-SelfNet consists of two main components:
-
Self-supervised Transformer Encoder: This module pre-trains on the OCT data using a self-supervised Masked Auto-Encoder (MAE) approach to learn powerful visual representations.
-
Multi-Modal Fusion Network: This component takes the pre-trained features from the Transformer Encoder and fuses them with OCT scans from multiple sources to boost classification performance.
The researchers evaluated their model on a large dataset of OCT images spanning multiple retinal diseases. They showed that Multi-OCT-SelfNet outperforms previous state-of-the-art methods, demonstrating the value of integrating self-supervised learning and multi-source data fusion for this task.
Critical Analysis
The paper provides a comprehensive technical approach and thorough evaluation of the proposed Multi-OCT-SelfNet model. However, a few potential limitations and areas for future research are worth considering:
-
Data Diversity: While the model leverages OCT scans from multiple sources, the dataset may still lack diversity in terms of patient demographics, image quality, and disease prevalence. Expanding the dataset could further improve the model's generalization capabilities.
-
Interpretability: As with many deep learning models, the internal workings of Multi-OCT-SelfNet may be difficult to interpret. Incorporating explainable AI techniques could help provide more insights into the model's decision-making process.
-
Clinical Validation: The paper focuses on the technical performance of the model, but more research is needed to assess its real-world clinical applicability and impact on patient outcomes.
Overall, the Multi-OCT-SelfNet model presents a promising approach to leveraging self-supervised learning and multi-modal data fusion for enhanced retinal disease classification. Further research and development in this direction could lead to more accurate and reliable computer-aided diagnosis tools for ophthalmology.
Conclusion
The Multi-OCT-SelfNet model proposed in this paper demonstrates the potential of integrating self-supervised learning and multi-source data fusion for improving multi-class retinal disease classification from Optical Coherence Tomography (OCT) images. By combining these two powerful techniques, the researchers were able to create a more robust and accurate AI system for diagnosing various eye conditions.
This work highlights the ongoing advancements in the field of medical image analysis using deep learning, particularly in the context of ophthalmology. As these technologies continue to evolve, they may lead to more efficient and reliable tools for early detection and management of retinal diseases, ultimately benefiting patients and healthcare providers alike.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multi-OCT-SelfNet: Integrating Self-Supervised Learning with Multi-Source Data Fusion for Enhanced Multi-Class Retinal Disease Classification
Fatema-E- Jannat, Sina Gholami, Jennifer I. Lim, Theodore Leng, Minhaj Nur Alam, Hamed Tabkhi
In the medical domain, acquiring large datasets poses significant challenges due to privacy concerns. Nonetheless, the development of a robust deep-learning model for retinal disease diagnosis necessitates a substantial dataset for training. The capacity to generalize effectively on smaller datasets remains a persistent challenge. The scarcity of data presents a significant barrier to the practical implementation of scalable medical AI solutions. To address this issue, we've combined a wide range of data sources to improve performance and generalization to new data by giving it a deeper understanding of the data representation from multi-modal datasets and developed a self-supervised framework based on large language models (LLMs), SwinV2 to gain a deeper understanding of multi-modal dataset representations, enhancing the model's ability to extrapolate to new data for the detection of eye diseases using optical coherence tomography (OCT) images. We adopt a two-phase training methodology, self-supervised pre-training, and fine-tuning on a downstream supervised classifier. An ablation study conducted across three datasets employing various encoder backbones, without data fusion, with low data availability setting, and without self-supervised pre-training scenarios, highlights the robustness of our method. Our findings demonstrate consistent performance across these diverse conditions, showcasing superior generalization capabilities compared to the baseline model, ResNet-50.
Read more9/18/2024
🔮
0
New!Local-to-Global Self-Supervised Representation Learning for Diabetic Retinopathy Grading
Mostafa Hajighasemloua, Samad Sheikhaei, Hamid Soltanian-Zadeha
Artificial intelligence algorithms have demonstrated their image classification and segmentation ability in the past decade. However, artificial intelligence algorithms perform less for actual clinical data than those used for simulations. This research aims to present a novel hybrid learning model using self-supervised learning and knowledge distillation, which can achieve sufficient generalization and robustness. The self-attention mechanism and tokens employed in ViT, besides the local-to-global learning approach used in the hybrid model, enable the proposed algorithm to extract a high-dimensional and high-quality feature space from images. To demonstrate the proposed neural network's capability in classifying and extracting feature spaces from medical images, we use it on a dataset of Diabetic Retinopathy images, specifically the EyePACS dataset. This dataset is more complex structurally and challenging regarding damaged areas than other medical images. For the first time in this study, self-supervised learning and knowledge distillation are used to classify this dataset. In our algorithm, for the first time among all self-supervised learning and knowledge distillation models, the test dataset is 50% larger than the training dataset. Unlike many studies, we have not removed any images from the dataset. Finally, our algorithm achieved an accuracy of 79.1% in the linear classifier and 74.36% in the k-NN algorithm for multiclass classification. Compared to a similar state-of-the-art model, our results achieved higher accuracy and more effective representation spaces.
Read more10/2/2024
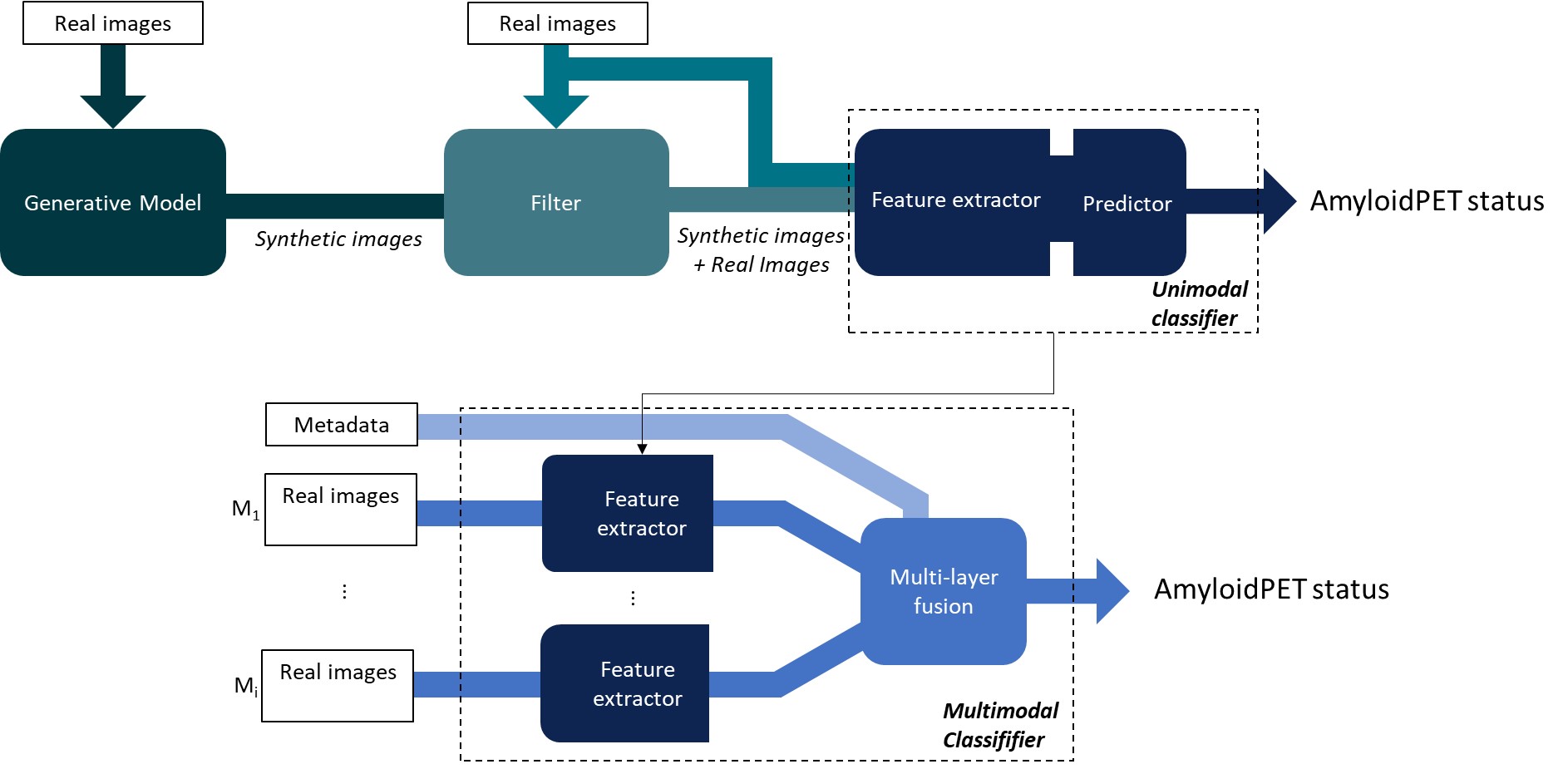
0
Generative artificial intelligence in ophthalmology: multimodal retinal images for the diagnosis of Alzheimer's disease with convolutional neural networks
I. R. Slootweg, M. Thach, K. R. Curro-Tafili, F. D. Verbraak, F. H. Bouwman, Y. A. L. Pijnenburg, J. F. Boer, J. H. P. de Kwisthout, L. Bagheriye, P. J. Gonz'alez
Background/Aim. This study aims to predict Amyloid Positron Emission Tomography (AmyloidPET) status with multimodal retinal imaging and convolutional neural networks (CNNs) and to improve the performance through pretraining with synthetic data. Methods. Fundus autofluorescence, optical coherence tomography (OCT), and OCT angiography images from 328 eyes of 59 AmyloidPET positive subjects and 108 AmyloidPET negative subjects were used for classification. Denoising Diffusion Probabilistic Models (DDPMs) were trained to generate synthetic images and unimodal CNNs were pretrained on synthetic data and finetuned on real data or trained solely on real data. Multimodal classifiers were developed to combine predictions of the four unimodal CNNs with patient metadata. Class activation maps of the unimodal classifiers provided insight into the network's attention to inputs. Results. DDPMs generated diverse, realistic images without memorization. Pretraining unimodal CNNs with synthetic data improved AUPR at most from 0.350 to 0.579. Integration of metadata in multimodal CNNs improved AUPR from 0.486 to 0.634, which was the best overall best classifier. Class activation maps highlighted relevant retinal regions which correlated with AD. Conclusion. Our method for generating and leveraging synthetic data has the potential to improve AmyloidPET prediction from multimodal retinal imaging. A DDPM can generate realistic and unique multimodal synthetic retinal images. Our best performing unimodal and multimodal classifiers were not pretrained on synthetic data, however pretraining with synthetic data slightly improved classification performance for two out of the four modalities.
Read more6/27/2024
🤿
0
A Multi-Dataset Classification-Based Deep Learning Framework for Electronic Health Records and Predictive Analysis in Healthcare
Syed Mohd Faisal Malik, Md Tabrez Nafis, Mohd Abdul Ahad, Safdar Tanweer
In contemporary healthcare, to protect patient data, electronic health records have become invaluable repositories, creating vast opportunities to leverage deep learning techniques for predictive analysis. Retinal fundus images, cirrhosis stages, and heart disease diagnostic predictions have shown promising results through the integration of deep learning techniques for classifying diverse datasets. This study proposes a novel deep learning predictive analysis framework for classifying multiple datasets by pre-processing data from three distinct sources. A hybrid deep learning model combining Residual Networks and Artificial Neural Networks is proposed to detect acute and chronic diseases such as heart diseases, cirrhosis, and retinal conditions, outperforming existing models. Dataset preparation involves aspects such as categorical data transformation, dimensionality reduction, and missing data synthesis. Feature extraction is effectively performed using scaler transformation for categorical datasets and ResNet architecture for image datasets. The resulting features are integrated into a unified classification model. Rigorous experimentation and evaluation resulted in high accuracies of 93%, 99%, and 95% for retinal fundus images, cirrhosis stages, and heart disease diagnostic predictions, respectively. The efficacy of the proposed method is demonstrated through a detailed analysis of F1-score, precision, and recall metrics. This study offers a comprehensive exploration of methodologies and experiments, providing in-depth knowledge of deep learning predictive analysis in electronic health records.
Read more9/26/2024