Multi-Operational Mathematical Derivations in Latent Space
2311.01230
0
0
🐍
Abstract
This paper investigates the possibility of approximating multiple mathematical operations in latent space for expression derivation. To this end, we introduce different multi-operational representation paradigms, modelling mathematical operations as explicit geometric transformations. By leveraging a symbolic engine, we construct a large-scale dataset comprising 1.7M derivation steps stemming from 61K premises and 6 operators, analysing the properties of each paradigm when instantiated with state-of-the-art neural encoders. Specifically, we investigate how different encoding mechanisms can approximate expression manipulation in latent space, exploring the trade-off between learning different operators and specialising within single operations, as well as the ability to support multi-step derivations and out-of-distribution generalisation. Our empirical analysis reveals that the multi-operational paradigm is crucial for disentangling different operators, while discriminating the conclusions for a single operation is achievable in the original expression encoder. Moreover, we show that architectural choices can heavily affect the training dynamics, structural organisation, and generalisation of the latent space, resulting in significant variations across paradigms and classes of encoders.
Create account to get full access
Overview
- This paper explores the idea of approximating multiple mathematical operations in latent space for expression derivation.
- The researchers introduce different multi-operational representation paradigms, modeling mathematical operations as explicit geometric transformations.
- They build a large-scale dataset of 1.7M derivation steps from 61K premises and 6 operators, and analyze the properties of each paradigm when using state-of-the-art neural encoders.
- The goal is to understand how different encoding mechanisms can approximate expression manipulation in latent space, and the trade-offs involved.
Plain English Explanation
The researchers in this paper are interested in finding ways to represent and manipulate mathematical expressions in a computer's "mind" or internal representation. Instead of just storing the expressions as text, they want to find a way to encode the expressions into a compact, numerical format that can be easily transformed to perform mathematical operations.
Imagine you have a mathematical equation like 2 + 3 = 5. The researchers want to find a way to represent this equation as a set of numbers that a computer can understand. Then, they want to be able to take those numbers and apply different mathematical operations to them, like multiplication or division, without having to go back to the original text-based equation.
This could be useful for things like automatically deriving new mathematical expressions or proofs, or for developing AI systems that can reason about and manipulate mathematical concepts. The key challenge is finding the right way to encode the expressions so that the computer can perform these operations accurately and efficiently.
Technical Explanation
The researchers introduce different "multi-operational representation paradigms" - ways of modeling mathematical operations as geometric transformations in a latent (hidden) space. They construct a large dataset of 1.7 million derivation steps from 61,000 premises and 6 different operators.
They then analyze how well different state-of-the-art neural network encoders can approximate these expression manipulations in the latent space. The key questions they explore are:
- Can the encoders effectively "disentangle" the different mathematical operators, or do they struggle to differentiate them?
- How well can the encoders support multi-step derivations and generalization to expressions they haven't seen before?
The results show that the multi-operational paradigm is crucial for separating the different operators in the latent space. However, a single-operation encoder can still effectively discriminate the conclusions for a given operator.
The researchers also find that the architectural choices for the neural encoders heavily influence the training dynamics, the structural organization of the latent space, and the ability to generalize. Different encoder types show significant variations in these properties across the paradigms.
Critical Analysis
The paper provides a thorough investigation of the challenges in approximating mathematical operations in latent space. However, it does not address some important practical considerations:
- The experiments are conducted on a relatively small set of 6 operators. It's unclear how the models would scale to a larger, more comprehensive set of mathematical operations.
- The dataset, while large, is still synthetic and may not capture the full complexity of real-world mathematical expressions and derivations. Further testing on more diverse, real-world data would be valuable.
- The paper does not explore the potential for errors or inconsistencies in the latent space representations, which could be an important practical concern.
Additionally, the researchers do not delve into potential applications or the broader implications of this work. Understanding how these latent space representations could be leveraged in AI systems for mathematical reasoning or other domains could strengthen the impact of the research.
Conclusion
This paper presents an intriguing exploration of approximating mathematical operations in latent space, with the goal of enabling more efficient and flexible representation and manipulation of mathematical expressions. The key insights are that a multi-operational paradigm is crucial for disentangling different operators, while a single-operation encoder can still effectively handle individual operations.
The research also highlights the importance of architectural choices in the neural encoders, which can significantly impact the training dynamics, latent space organization, and generalization capabilities. While the work is primarily theoretical, it lays the groundwork for future developments in AI-powered mathematical reasoning and expression derivation. Continued research in this direction could lead to advancements in areas like automated theorem proving, symbolic computation, and the integration of mathematical knowledge into intelligent systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Operational Latent Spaces
Scott H. Hawley, Austin R. Tackett
0
0
We investigate the construction of latent spaces through self-supervised learning to support semantically meaningful operations. Analogous to operational amplifiers, these operational latent spaces (OpLaS) not only demonstrate semantic structure such as clustering but also support common transformational operations with inherent semantic meaning. Some operational latent spaces are found to have arisen unintentionally in the progress toward some (other) self-supervised learning objective, in which unintended but still useful properties are discovered among the relationships of points in the space. Other spaces may be constructed intentionally by developers stipulating certain kinds of clustering or transformations intended to produce the desired structure. We focus on the intentional creation of operational latent spaces via self-supervised learning, including the introduction of rotation operators via a novel FiLMR layer, which can be used to enable ring-like symmetries found in some musical constructions.
6/14/2024
📉
Transport of Algebraic Structure to Latent Embeddings
Samuel Pfrommer, Brendon G. Anderson, Somayeh Sojoudi
0
0
Machine learning often aims to produce latent embeddings of inputs which lie in a larger, abstract mathematical space. For example, in the field of 3D modeling, subsets of Euclidean space can be embedded as vectors using implicit neural representations. Such subsets also have a natural algebraic structure including operations (e.g., union) and corresponding laws (e.g., associativity). How can we learn to union two sets using only their latent embeddings while respecting associativity? We propose a general procedure for parameterizing latent space operations that are provably consistent with the laws on the input space. This is achieved by learning a bijection from the latent space to a carefully designed mirrored algebra which is constructed on Euclidean space in accordance with desired laws. We evaluate these structural transport nets for a range of mirrored algebras against baselines that operate directly on the latent space. Our experiments provide strong evidence that respecting the underlying algebraic structure of the input space is key for learning accurate and self-consistent operations.
5/28/2024
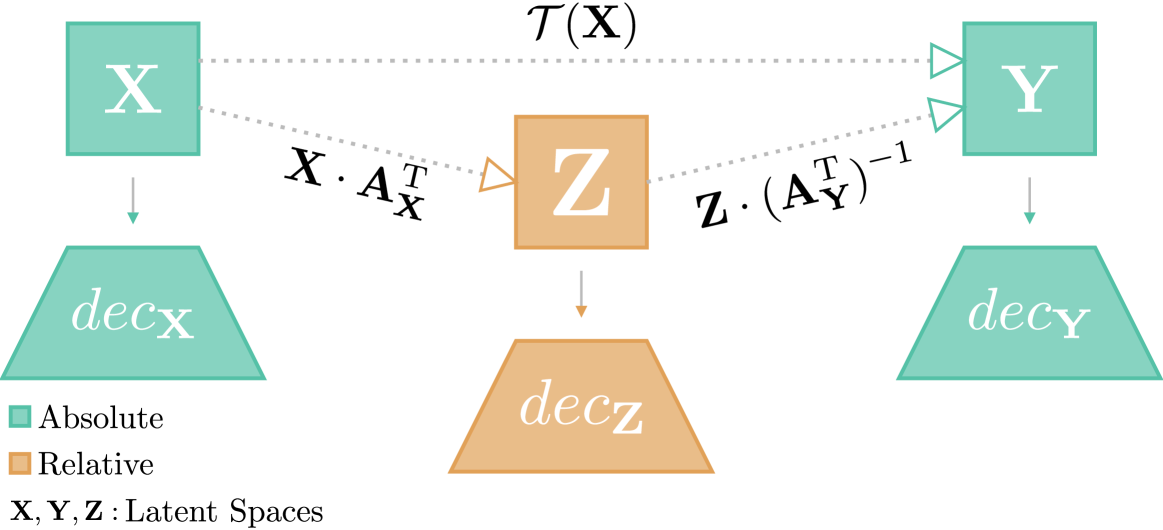
Latent Space Translation via Inverse Relative Projection
Valentino Maiorca, Luca Moschella, Marco Fumero, Francesco Locatello, Emanuele Rodol`a
0
0
The emergence of similar representations between independently trained neural models has sparked significant interest in the representation learning community, leading to the development of various methods to obtain communication between latent spaces. Latent space communication can be achieved in two ways: i) by independently mapping the original spaces to a shared or relative one; ii) by directly estimating a transformation from a source latent space to a target one. In this work, we combine the two into a novel method to obtain latent space translation through the relative space. By formalizing the invertibility of angle-preserving relative representations and assuming the scale invariance of decoder modules in neural models, we can effectively use the relative space as an intermediary, independently projecting onto and from other semantically similar spaces. Extensive experiments over various architectures and datasets validate our scale invariance assumption and demonstrate the high accuracy of our method in latent space translation. We also apply our method to zero-shot stitching between arbitrary pre-trained text and image encoders and their classifiers, even across modalities. Our method has significant potential for facilitating the reuse of models in a practical manner via compositionality.
6/24/2024
🧠
Latent Space Representations of Neural Algorithmic Reasoners
Vladimir V. Mirjani'c, Razvan Pascanu, Petar Veliv{c}kovi'c
0
0
Neural Algorithmic Reasoning (NAR) is a research area focused on designing neural architectures that can reliably capture classical computation, usually by learning to execute algorithms. A typical approach is to rely on Graph Neural Network (GNN) architectures, which encode inputs in high-dimensional latent spaces that are repeatedly transformed during the execution of the algorithm. In this work we perform a detailed analysis of the structure of the latent space induced by the GNN when executing algorithms. We identify two possible failure modes: (i) loss of resolution, making it hard to distinguish similar values; (ii) inability to deal with values outside the range observed during training. We propose to solve the first issue by relying on a softmax aggregator, and propose to decay the latent space in order to deal with out-of-range values. We show that these changes lead to improvements on the majority of algorithms in the standard CLRS-30 benchmark when using the state-of-the-art Triplet-GMPNN processor. Our code is available at https://github.com/mirjanic/nar-latent-spaces
4/30/2024