Multi-scale Wasserstein Shortest-path Graph Kernels for Graph Classification

0
🏷️
Sign in to get full access
Overview
- Existing graph kernels, like R-convolution graph kernels, struggle with two key challenges: 1) Comparing graphs at multiple scales, and 2) Considering the distributions of substructures when computing the kernel matrix.
- To address these challenges, the researchers propose a new graph kernel called the Multi-scale Wasserstein Shortest-Path graph kernel (MWSP).
- The core of MWSP is the multi-scale shortest-path node feature map, which captures the number of occurrences of shortest paths around each node.
- MWSP incorporates multiple graph scales by using truncated BFS trees of different depths rooted at each node.
- The Wasserstein distance is used to compute the similarity between the multi-scale shortest-path node feature maps of two graphs, considering the distributions of shortest paths.
Plain English Explanation
Graph kernels are methods for measuring the similarity between different graphs, which are mathematical structures that can represent complex relationships. However, the existing graph kernels have two key limitations:
-
Comparing graphs at multiple scales: They can only compare graphs at a single, fixed scale, but real-world graphs often have structures and patterns that exist at different scales.
-
Considering the distribution of substructures: They don't fully account for how the different substructures (like paths or clusters) are distributed within the graphs when computing the similarity.
To address these limitations, the researchers developed a new graph kernel called the Multi-scale Wasserstein Shortest-Path graph kernel (MWSP). The core idea is to represent each node in the graph by a feature vector that captures the number of times different "shortest paths" (sequences of connected nodes) appear around that node.
To incorporate multiple scales, the researchers use "truncated BFS trees" - these are like mini-graphs that capture the local neighborhood around each node at different levels of detail. By comparing the distributions of these multi-scale shortest-path features using the Wasserstein distance, MWSP can measure the overall similarity between two graphs while considering both local and global structures.
The researchers show that MWSP outperforms existing graph kernels on a variety of benchmark datasets, demonstrating the advantages of their multi-scale, distribution-aware approach to graph comparison.
Technical Explanation
The key technical components of the MWSP graph kernel are:
-
Multi-scale Shortest-Path Node Feature Map: For each node in a graph, this feature map captures the number of occurrences of different shortest paths around that node. The shortest paths are represented by concatenating the labels of the nodes along the path.
-
Incorporating Multiple Scales: To capture graph structures at different scales, the researchers use truncated Breadth-First Search (BFS) trees rooted at each node. These trees represent the local neighborhood of each node at varying levels of detail.
-
Comparing Feature Distributions with Wasserstein Distance: To compute the similarity between two graphs, the researchers use the Wasserstein distance to compare the distributions of the multi-scale shortest-path node feature maps. This allows them to consider not just the individual features, but how they are distributed within each graph.
The researchers conducted experiments on various benchmark graph datasets and showed that MWSP achieves state-of-the-art performance compared to existing graph kernels. This demonstrates the advantages of their multi-scale, distribution-aware approach to graph comparison.
Critical Analysis
The researchers acknowledge a few limitations of their MWSP approach:
-
Computational Complexity: Computing the Wasserstein distance between the multi-scale node feature maps can be computationally expensive, especially for large graphs. The researchers mention that future work could explore ways to improve the scalability of MWSP.
-
Label Sensitivity: MWSP relies on the node labels in the graphs to construct the shortest-path features. If the node labels are not informative or do not accurately reflect the underlying graph structure, the performance of MWSP may be limited.
-
Interpretability: While MWSP achieves strong empirical performance, the researchers do not provide much insight into why the multi-scale shortest-path features and Wasserstein distance are effective for graph comparison. Further analysis of the learned representations and their connections to graph properties could improve the interpretability of the method.
Additionally, one could raise questions about the generalizability of MWSP. The researchers only evaluate it on a limited set of benchmark datasets, so its performance on more diverse or domain-specific graph data is unclear. Exploring the strengths and weaknesses of MWSP across a broader range of graph data could be an interesting area for future research.
Conclusion
The MWSP graph kernel proposed in this paper addresses two key limitations of existing graph kernels: the inability to compare graphs at multiple scales and the lack of consideration for the distributions of substructures within the graphs. By introducing the multi-scale shortest-path node feature map and using the Wasserstein distance to compare these features, MWSP demonstrates state-of-the-art performance on various benchmark datasets.
This work highlights the importance of developing graph comparison methods that can capture the rich, multi-scale structure of real-world graphs. The researchers' insights could have important implications for a wide range of applications, from social network analysis to molecular biology, where understanding the relationships between complex graph-structured data is crucial. As the field of graph machine learning continues to evolve, innovations like MWSP may pave the way for more powerful and versatile graph comparison techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏷️
0
Multi-scale Wasserstein Shortest-path Graph Kernels for Graph Classification
Wei Ye, Hao Tian, Qijun Chen
Graph kernels are conventional methods for computing graph similarities. However, the existing R-convolution graph kernels cannot resolve both of the two challenges: 1) Comparing graphs at multiple different scales, and 2) Considering the distributions of substructures when computing the kernel matrix. These two challenges limit their performances. To mitigate both of the two challenges, we propose a novel graph kernel called the Multi-scale Wasserstein Shortest-Path graph kernel (MWSP), at the heart of which is the multi-scale shortest-path node feature map, of which each element denotes the number of occurrences of the shortest path around a node. The shortest path is represented by the concatenation of all the labels of nodes in it. Since the shortest-path node feature map can only compare graphs at local scales, we incorporate into it the multiple different scales of the graph structure, which are captured by the truncated BFS trees of different depths rooted at each node in a graph. We use the Wasserstein distance to compute the similarity between the multi-scale shortest-path node feature maps of two graphs, considering the distributions of shortest paths. We empirically validate MWSP on various benchmark graph datasets and demonstrate that it achieves state-of-the-art performance on most datasets.
Read more5/14/2024
0
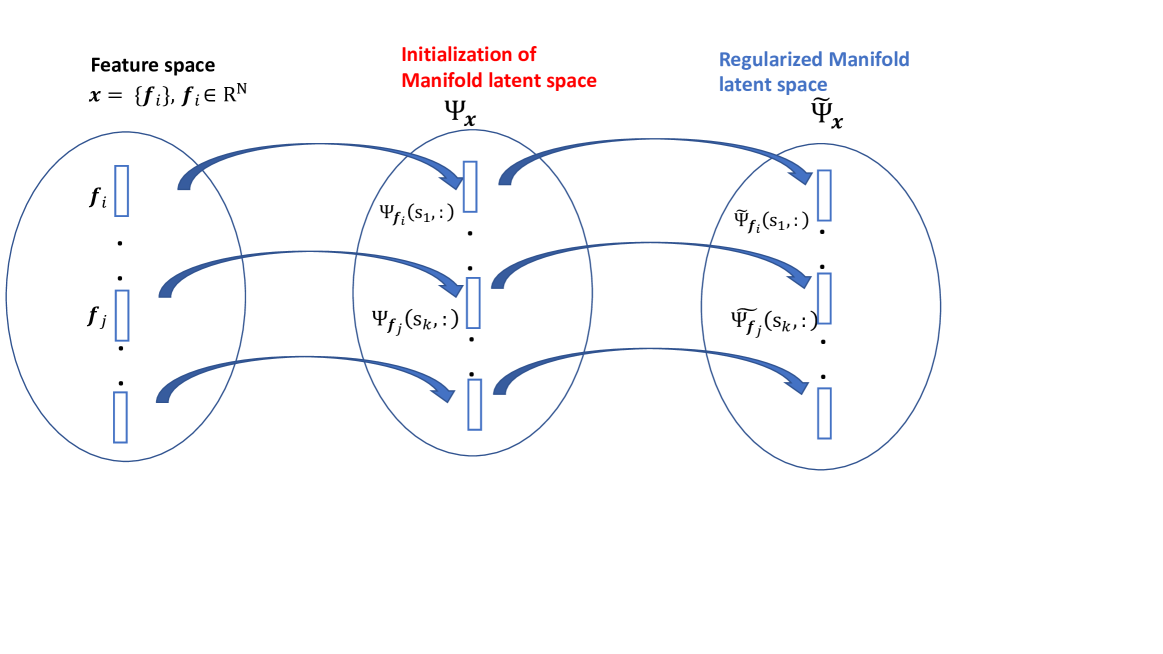
MS-IMAP -- A Multi-Scale Graph Embedding Approach for Interpretable Manifold Learning
Shay Deutsch, Lionel Yelibi, Alex Tong Lin, Arjun Ravi Kannan
Deriving meaningful representations from complex, high-dimensional data in unsupervised settings is crucial across diverse machine learning applications. This paper introduces a framework for multi-scale graph network embedding based on spectral graph wavelets that employs a contrastive learning approach. A significant feature of the proposed embedding is its capacity to establish a correspondence between the embedding space and the input feature space which aids in deriving feature importance of the original features. We theoretically justify our approach and demonstrate that, in Paley-Wiener spaces on combinatorial graphs, the spectral graph wavelets operator offers greater flexibility and better control over smoothness properties compared to the Laplacian operator. We validate the effectiveness of our proposed graph embedding on a variety of public datasets through a range of downstream tasks, including clustering and unsupervised feature importance.
Read more6/7/2024

0
Statistical and Computational Guarantees of Kernel Max-Sliced Wasserstein Distances
Jie Wang, March Boedihardjo, Yao Xie
Optimal transport has been very successful for various machine learning tasks; however, it is known to suffer from the curse of dimensionality. Hence, dimensionality reduction is desirable when applied to high-dimensional data with low-dimensional structures. The kernel max-sliced (KMS) Wasserstein distance is developed for this purpose by finding an optimal nonlinear mapping that reduces data into $1$ dimensions before computing the Wasserstein distance. However, its theoretical properties have not yet been fully developed. In this paper, we provide sharp finite-sample guarantees under milder technical assumptions compared with state-of-the-art for the KMS $p$-Wasserstein distance between two empirical distributions with $n$ samples for general $pin[1,infty)$. Algorithm-wise, we show that computing the KMS $2$-Wasserstein distance is NP-hard, and then we further propose a semidefinite relaxation (SDR) formulation (which can be solved efficiently in polynomial time) and provide a relaxation gap for the SDP solution. We provide numerical examples to demonstrate the good performance of our scheme for high-dimensional two-sample testing.
Read more5/31/2024
0
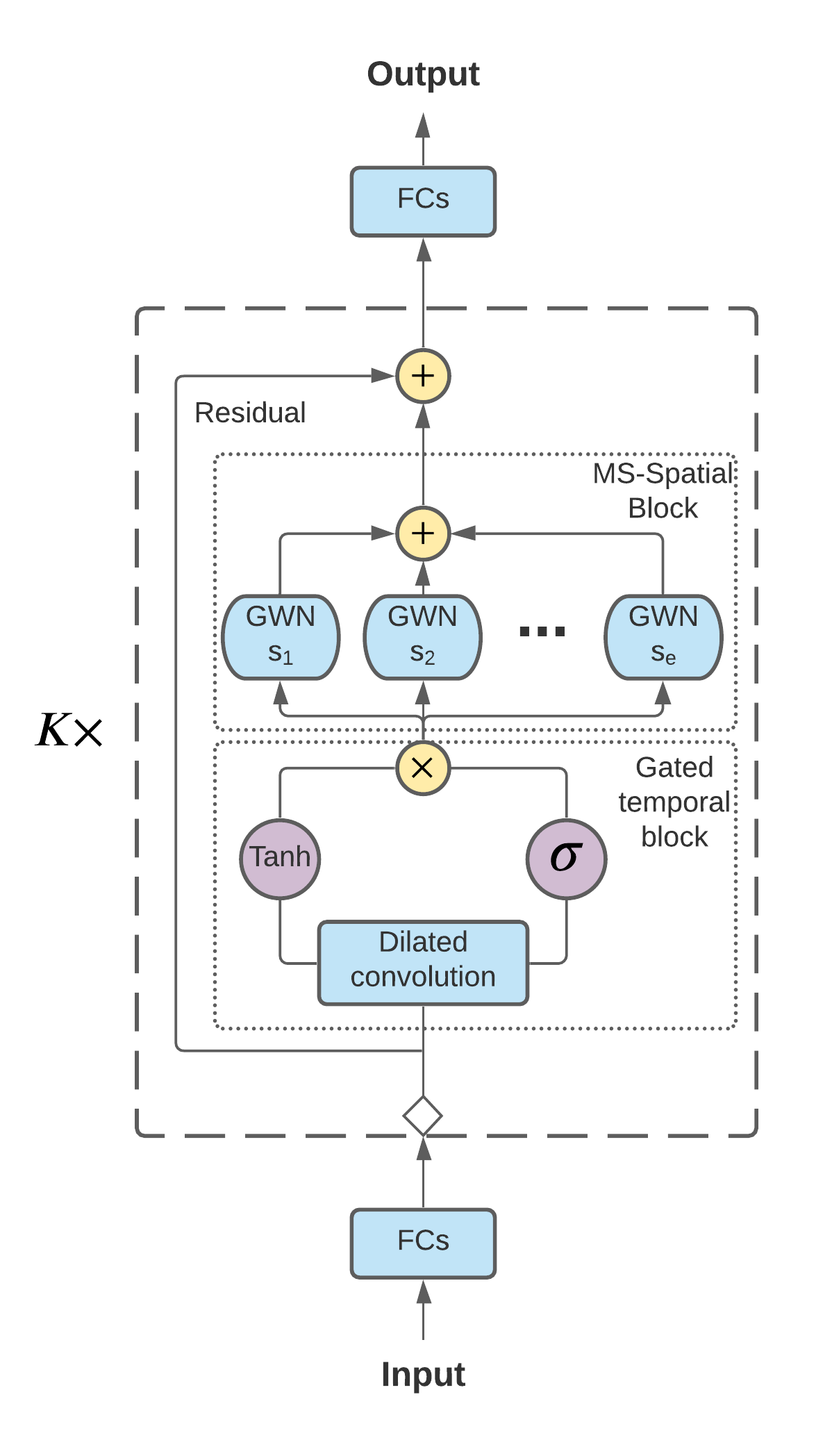
Traffic Prediction considering Multiple Levels of Spatial-temporal Information: A Multi-scale Graph Wavelet-based Approach
Zilin Bian, Jingqin Gao, Kaan Ozbay, Zhenning Li
Although traffic prediction has been receiving considerable attention with a number of successes in the context of intelligent transportation systems, the prediction of traffic states over a complex transportation network that contains different road types has remained a challenge. This study proposes a multi-scale graph wavelet temporal convolution network (MSGWTCN) to predict the traffic states in complex transportation networks. Specifically, a multi-scale spatial block is designed to simultaneously capture the spatial information at different levels, and the gated temporal convolution network is employed to extract the temporal dependencies of the data. The model jointly learns to mount multiple levels of the spatial interactions by stacking graph wavelets with different scales. Two real-world datasets are used in this study to investigate the model performance, including a highway network in Seattle and a dense road network of Manhattan in New York City. Experiment results show that the proposed model outperforms other baseline models. Furthermore, different scales of graph wavelets are found to be effective in extracting local, intermediate and global information at the same time and thus enable the model to learn a complex transportation network topology with various types of road segments. By carefully customizing the scales of wavelets, the model is able to improve the prediction performance and better adapt to different network configurations.
Read more6/21/2024