MS-IMAP -- A Multi-Scale Graph Embedding Approach for Interpretable Manifold Learning

0
Sign in to get full access
Overview
• This paper presents MS-IMAP, a multi-scale graph embedding approach for interpretable manifold learning.
• It aims to capture the inherent multi-scale structure of complex data and provide a more interpretable representation compared to traditional dimensionality reduction techniques.
• The method leverages a multi-scale graph construction and a novel optimization strategy to learn a low-dimensional embedding that preserves the intrinsic manifold structure of the data.
Plain English Explanation
High-dimensional data, such as images or sensor readings, often lie on a lower-dimensional manifold, meaning they can be represented using fewer features without losing significant information. Multi-scale graph embedding approaches like MS-IMAP can help us find this lower-dimensional representation in a more interpretable way.
The key idea is to first build a multi-scale graph that captures the relationships between data points at different levels of detail. This is like looking at a city map at different zoom levels - you can see the overall structure at a high level, but also the details of individual streets and buildings.
Then, the algorithm learns a low-dimensional embedding of the data that preserves the structure of this multi-scale graph. This embedding can be used for tasks like visualization, clustering, or anomaly detection, and it provides insights into the underlying manifold structure of the data.
Compared to traditional dimensionality reduction techniques, the multi-scale approach of MS-IMAP can uncover more interpretable representations that align with the natural hierarchies or scales present in the data. This can be particularly useful in domains like biology, where we may want to understand how different levels of organization (e.g., genes, cells, tissues) are related.
Technical Explanation
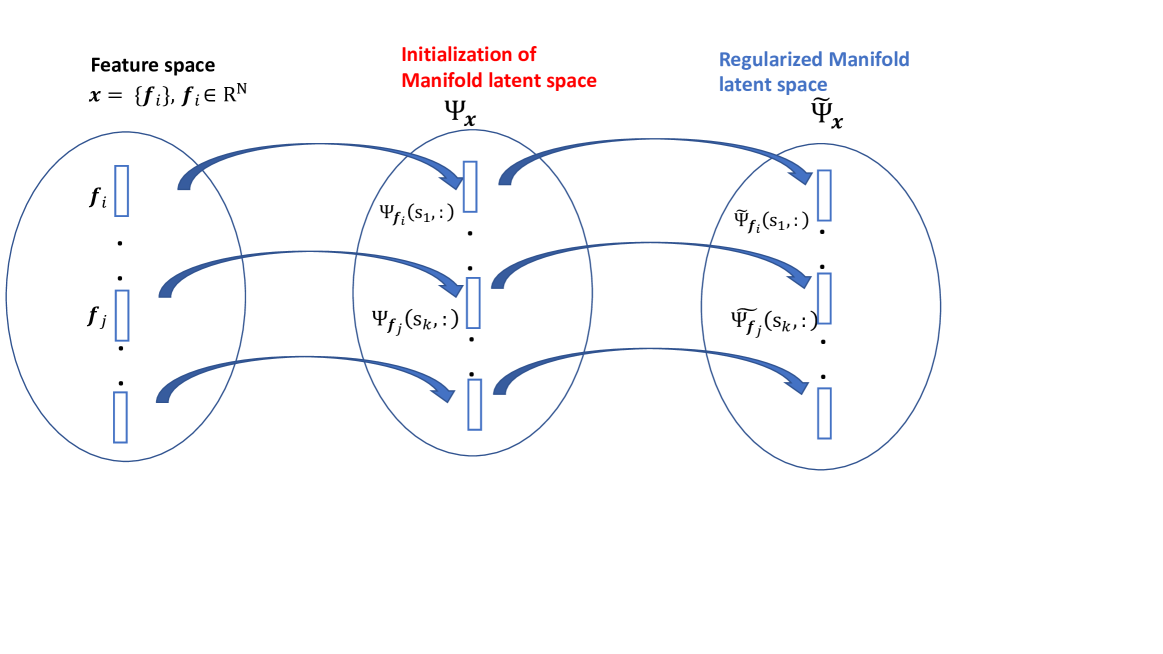
The core of MS-IMAP is a novel multi-scale graph construction process that captures the inherent multi-resolution structure of the data. This is achieved by building a hierarchy of graphs, where each level represents the data at a different scale of granularity.
To learn the final low-dimensional embedding, MS-IMAP employs a two-stage optimization strategy. First, it learns a set of local embeddings at each scale of the graph hierarchy using a modified version of Multi-Scale Wasserstein Shortest Path Graph Kernels. Then, it aligns these local embeddings into a global embedding that preserves the multi-scale structure using a novel optimization objective.
This approach has several advantages over traditional dimensionality reduction techniques, such as Spectral Clustering with Gaussian Mixture Block Models. By explicitly modeling the multi-scale structure of the data, MS-IMAP can uncover more interpretable low-dimensional representations that align with the natural hierarchies present in the data.
Critical Analysis
The authors of the paper acknowledge several limitations and areas for further research. For example, the multi-scale graph construction process relies on several hyperparameters that may need to be tuned for different datasets. Additionally, the optimization strategy, while effective, may be computationally expensive for very large datasets.
Another potential concern is the extent to which the learned embeddings are truly "interpretable." While the multi-scale approach provides more insight into the underlying manifold structure, the interpretability of the final representations may still be limited, especially for complex, high-dimensional data. Further research is needed to better understand the interpretability of the learned embeddings and how they can be used in downstream applications.
Overall, MS-IMAP represents an interesting and promising approach to interpretable manifold learning. However, as with any research, there are areas for improvement and further exploration, such as scalability, robustness, and the development of more intuitive interpretability metrics. Joint embeddings for graph and instruction tuning could be a fruitful area for extending this work.
Conclusion
The MS-IMAP paper presents a novel multi-scale graph embedding approach for interpretable manifold learning. By explicitly modeling the multi-resolution structure of complex data, the method can uncover low-dimensional representations that provide more insight into the underlying manifold structure compared to traditional dimensionality reduction techniques.
While the approach has some limitations and areas for further research, it represents an important step forward in the field of interpretable machine learning. As data becomes increasingly high-dimensional and complex, techniques like MS-IMAP will be crucial for extracting meaningful insights and supporting decision-making in a wide range of domains, from hyperspectral imaging to biological systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MS-IMAP -- A Multi-Scale Graph Embedding Approach for Interpretable Manifold Learning
Shay Deutsch, Lionel Yelibi, Alex Tong Lin, Arjun Ravi Kannan
Deriving meaningful representations from complex, high-dimensional data in unsupervised settings is crucial across diverse machine learning applications. This paper introduces a framework for multi-scale graph network embedding based on spectral graph wavelets that employs a contrastive learning approach. A significant feature of the proposed embedding is its capacity to establish a correspondence between the embedding space and the input feature space which aids in deriving feature importance of the original features. We theoretically justify our approach and demonstrate that, in Paley-Wiener spaces on combinatorial graphs, the spectral graph wavelets operator offers greater flexibility and better control over smoothness properties compared to the Laplacian operator. We validate the effectiveness of our proposed graph embedding on a variety of public datasets through a range of downstream tasks, including clustering and unsupervised feature importance.
Read more6/7/2024

0
IsUMap: Manifold Learning and Data Visualization leveraging Vietoris-Rips filtrations
Lukas Silvester Barth (Hannaneh), Fatemeh (Hannaneh), Fahimi, Parvaneh Joharinad, Jurgen Jost, Janis Keck
This work introduces IsUMap, a novel manifold learning technique that enhances data representation by integrating aspects of UMAP and Isomap with Vietoris-Rips filtrations. We present a systematic and detailed construction of a metric representation for locally distorted metric spaces that captures complex data structures more accurately than the previous schemes. Our approach addresses limitations in existing methods by accommodating non-uniform data distributions and intricate local geometries. We validate its performance through extensive experiments on examples of various geometric objects and benchmark real-world datasets, demonstrating significant improvements in representation quality.
Read more7/26/2024

0
Multi-level Graph Subspace Contrastive Learning for Hyperspectral Image Clustering
Jingxin Wang, Renxiang Guan, Kainan Gao, Zihao Li, Hao Li, Xianju Li, Chang Tang
Hyperspectral image (HSI) clustering is a challenging task due to its high complexity. Despite subspace clustering shows impressive performance for HSI, traditional methods tend to ignore the global-local interaction in HSI data. In this study, we proposed a multi-level graph subspace contrastive learning (MLGSC) for HSI clustering. The model is divided into the following main parts. Graph convolution subspace construction: utilizing spectral and texture feautures to construct two graph convolution views. Local-global graph representation: local graph representations were obtained by step-by-step convolutions and a more representative global graph representation was obtained using an attention-based pooling strategy. Multi-level graph subspace contrastive learning: multi-level contrastive learning was conducted to obtain local-global joint graph representations, to improve the consistency of the positive samples between views, and to obtain more robust graph embeddings. Specifically, graph-level contrastive learning is used to better learn global representations of HSI data. Node-level intra-view and inter-view contrastive learning is designed to learn joint representations of local regions of HSI. The proposed model is evaluated on four popular HSI datasets: Indian Pines, Pavia University, Houston, and Xu Zhou. The overall accuracies are 97.75%, 99.96%, 92.28%, and 95.73%, which significantly outperforms the current state-of-the-art clustering methods.
Read more4/9/2024
🏷️
0
Multi-scale Wasserstein Shortest-path Graph Kernels for Graph Classification
Wei Ye, Hao Tian, Qijun Chen
Graph kernels are conventional methods for computing graph similarities. However, the existing R-convolution graph kernels cannot resolve both of the two challenges: 1) Comparing graphs at multiple different scales, and 2) Considering the distributions of substructures when computing the kernel matrix. These two challenges limit their performances. To mitigate both of the two challenges, we propose a novel graph kernel called the Multi-scale Wasserstein Shortest-Path graph kernel (MWSP), at the heart of which is the multi-scale shortest-path node feature map, of which each element denotes the number of occurrences of the shortest path around a node. The shortest path is represented by the concatenation of all the labels of nodes in it. Since the shortest-path node feature map can only compare graphs at local scales, we incorporate into it the multiple different scales of the graph structure, which are captured by the truncated BFS trees of different depths rooted at each node in a graph. We use the Wasserstein distance to compute the similarity between the multi-scale shortest-path node feature maps of two graphs, considering the distributions of shortest paths. We empirically validate MWSP on various benchmark graph datasets and demonstrate that it achieves state-of-the-art performance on most datasets.
Read more5/14/2024