A Multi-Source Retrieval Question Answering Framework Based on RAG
2405.19207
0
0
🧪
Abstract
With the rapid development of large-scale language models, Retrieval-Augmented Generation (RAG) has been widely adopted. However, existing RAG paradigms are inevitably influenced by erroneous retrieval information, thereby reducing the reliability and correctness of generated results. Therefore, to improve the relevance of retrieval information, this study proposes a method that replaces traditional retrievers with GPT-3.5, leveraging its vast corpus knowledge to generate retrieval information. We also propose a web retrieval based method to implement fine-grained knowledge retrieval, Utilizing the powerful reasoning capability of GPT-3.5 to realize semantic partitioning of problem.In order to mitigate the illusion of GPT retrieval and reduce noise in Web retrieval,we proposes a multi-source retrieval framework, named MSRAG, which combines GPT retrieval with web retrieval. Experiments on multiple knowledge-intensive QA datasets demonstrate that the proposed framework in this study performs better than existing RAG framework in enhancing the overall efficiency and accuracy of QA systems.
Create account to get full access
Overview
- Existing Retrieval-Augmented Generation (RAG) systems are limited by erroneous retrieval information, reducing the reliability and accuracy of generated results.
- This study proposes a method that replaces traditional retrievers with GPT-3.5, leveraging its vast corpus knowledge to generate more relevant retrieval information.
- A web retrieval-based method is also proposed to enable fine-grained knowledge retrieval, utilizing the powerful reasoning capabilities of GPT-3.5.
- To mitigate the limitations of GPT retrieval and web retrieval, a multi-source retrieval framework called MSRAG is introduced, which combines these two approaches.
Plain English Explanation
Large language models like GPT-3.5 have become increasingly powerful at generating human-like text. However, when these models are used in Retrieval-Augmented Generation (RAG) systems, the retrieval information they rely on can sometimes be inaccurate or irrelevant, leading to less reliable and correct results.
To address this issue, the researchers in this study developed a new method that uses GPT-3.5 itself as the retriever, instead of traditional retrieval systems. The idea is that GPT-3.5's vast knowledge base can generate more relevant and useful retrieval information than conventional approaches. They also proposed a web-based retrieval method that allows for more fine-grained knowledge retrieval, leveraging GPT-3.5's strong reasoning capabilities.
To further improve the quality of the retrieved information, the researchers developed a framework called MSRAG, which combines the GPT-based retrieval with the web-based retrieval. This multi-source approach helps to mitigate the limitations of each individual retrieval method, resulting in more accurate and reliable question-answering systems.
Technical Explanation
The researchers in this study recognized the limitations of existing Retrieval-Augmented Generation (RAG) systems, which are influenced by erroneous retrieval information and can reduce the reliability and correctness of generated results. To address this, they proposed a method that replaces traditional retrievers with GPT-3.5, leveraging its vast corpus knowledge to generate more relevant retrieval information.
Additionally, the researchers developed a web retrieval-based method to implement fine-grained knowledge retrieval, utilizing the powerful reasoning capability of GPT-3.5 to enable semantic partitioning of problems. To mitigate the limitations of GPT retrieval and web retrieval, the researchers proposed a multi-source retrieval framework, named MSRAG, which combines the GPT-based retrieval with the web-based retrieval.
The researchers conducted experiments on multiple knowledge-intensive question-answering datasets, and the results demonstrated that the proposed MSRAG framework performs better than existing RAG frameworks in enhancing the overall efficiency and accuracy of question-answering systems.
Critical Analysis
The researchers in this study have made a significant contribution to the field of Retrieval-Augmented Generation by addressing the limitations of existing RAG systems. The use of GPT-3.5 as the retriever, as well as the web-based retrieval method, are innovative approaches that leverage the powerful capabilities of large language models to improve the relevance and accuracy of the retrieval information.
However, the paper does not provide a detailed analysis of the limitations and potential drawbacks of the proposed methods. For example, the researchers do not discuss the computational overhead or the scalability of the MSRAG framework, which could be important considerations for real-world applications.
Additionally, the paper does not explore the potential biases or ethical implications of using a large language model like GPT-3.5 as the primary retriever. There could be concerns about the reliability and fairness of the retrieval information generated by such a model, especially in sensitive or high-stakes domains.
Further research could also explore the generalizability of the MSRAG framework to other types of tasks and datasets, as well as the potential for combining it with other RAG approaches, such as DuetRAG or Blended-RAG, to create even more robust and effective systems.
Conclusion
This study presents a novel approach to Retrieval-Augmented Generation that addresses the limitations of existing RAG systems. By replacing traditional retrievers with GPT-3.5 and incorporating a web-based retrieval method, the researchers have developed a multi-source retrieval framework (MSRAG) that can generate more relevant and accurate retrieval information, leading to improved performance on knowledge-intensive question-answering tasks.
The findings of this study have important implications for the development of more reliable and effective AI systems, particularly in domains that require access to large and diverse knowledge bases. As the field of Retrieval-Augmented Generation continues to evolve, the MSRAG framework proposed in this study could serve as a foundation for further advancements in empowering large language models to tackle complex, knowledge-intensive problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Empowering Large Language Models to Set up a Knowledge Retrieval Indexer via Self-Learning
Xun Liang, Simin Niu, Zhiyu li, Sensen Zhang, Shichao Song, Hanyu Wang, Jiawei Yang, Feiyu Xiong, Bo Tang, Chenyang Xi
0
0
Retrieval-Augmented Generation (RAG) offers a cost-effective approach to injecting real-time knowledge into large language models (LLMs). Nevertheless, constructing and validating high-quality knowledge repositories require considerable effort. We propose a pre-retrieval framework named Pseudo-Graph Retrieval-Augmented Generation (PG-RAG), which conceptualizes LLMs as students by providing them with abundant raw reading materials and encouraging them to engage in autonomous reading to record factual information in their own words. The resulting concise, well-organized mental indices are interconnected through common topics or complementary facts to form a pseudo-graph database. During the retrieval phase, PG-RAG mimics the human behavior in flipping through notes, identifying fact paths and subsequently exploring the related contexts. Adhering to the principle of the path taken by many is the best, it integrates highly corroborated fact paths to provide a structured and refined sub-graph assisting LLMs. We validated PG-RAG on three specialized question-answering datasets. In single-document tasks, PG-RAG significantly outperformed the current best baseline, KGP-LLaMA, across all key evaluation metrics, with an average overall performance improvement of 11.6%. Specifically, its BLEU score increased by approximately 14.3%, and the QE-F1 metric improved by 23.7%. In multi-document scenarios, the average metrics of PG-RAG were at least 2.35% higher than the best baseline. Notably, the BLEU score and QE-F1 metric showed stable improvements of around 7.55% and 12.75%, respectively. Our code: https://github.com/IAAR-Shanghai/PGRAG.
5/28/2024
🛸
DuetRAG: Collaborative Retrieval-Augmented Generation
Dian Jiao, Li Cai, Jingsheng Huang, Wenqiao Zhang, Siliang Tang, Yueting Zhuang
0
0
Retrieval-Augmented Generation (RAG) methods augment the input of Large Language Models (LLMs) with relevant retrieved passages, reducing factual errors in knowledge-intensive tasks. However, contemporary RAG approaches suffer from irrelevant knowledge retrieval issues in complex domain questions (e.g., HotPot QA) due to the lack of corresponding domain knowledge, leading to low-quality generations. To address this issue, we propose a novel Collaborative Retrieval-Augmented Generation framework, DuetRAG. Our bootstrapping philosophy is to simultaneously integrate the domain fintuning and RAG models to improve the knowledge retrieval quality, thereby enhancing generation quality. Finally, we demonstrate DuetRAG' s matches with expert human researchers on HotPot QA.
5/24/2024
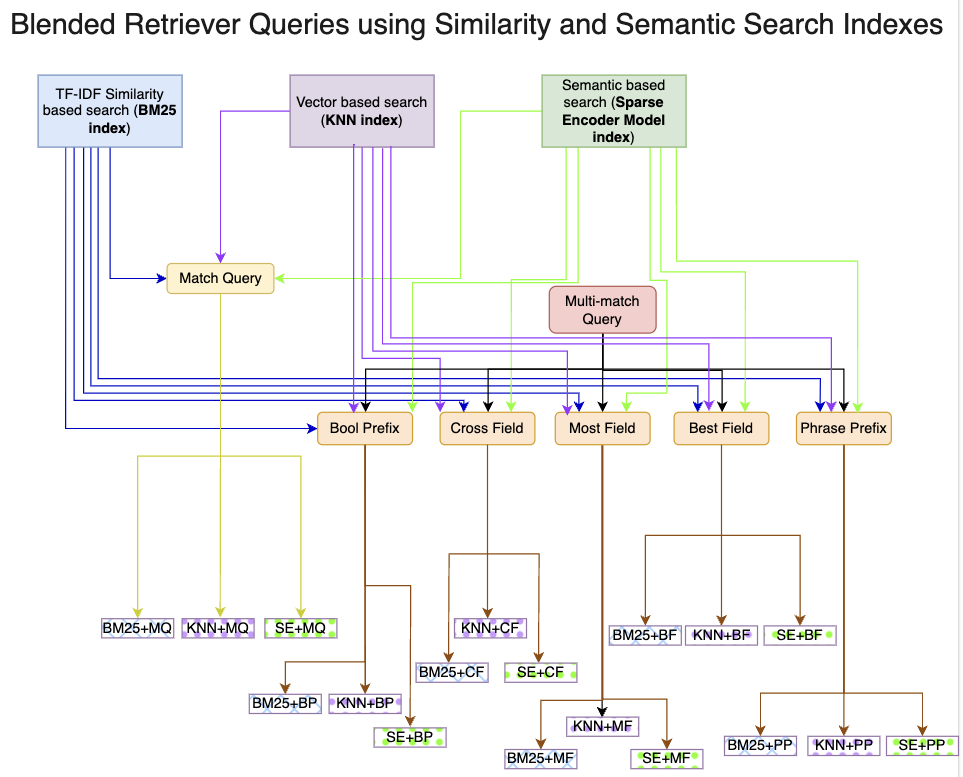
Blended RAG: Improving RAG (Retriever-Augmented Generation) Accuracy with Semantic Search and Hybrid Query-Based Retrievers
Kunal Sawarkar, Abhilasha Mangal, Shivam Raj Solanki
0
0
Retrieval-Augmented Generation (RAG) is a prevalent approach to infuse a private knowledge base of documents with Large Language Models (LLM) to build Generative Q&A (Question-Answering) systems. However, RAG accuracy becomes increasingly challenging as the corpus of documents scales up, with Retrievers playing an outsized role in the overall RAG accuracy by extracting the most relevant document from the corpus to provide context to the LLM. In this paper, we propose the 'Blended RAG' method of leveraging semantic search techniques, such as Dense Vector indexes and Sparse Encoder indexes, blended with hybrid query strategies. Our study achieves better retrieval results and sets new benchmarks for IR (Information Retrieval) datasets like NQ and TREC-COVID datasets. We further extend such a 'Blended Retriever' to the RAG system to demonstrate far superior results on Generative Q&A datasets like SQUAD, even surpassing fine-tuning performance.
4/12/2024
⛏️
Evaluation of Retrieval-Augmented Generation: A Survey
Hao Yu, Aoran Gan, Kai Zhang, Shiwei Tong, Qi Liu, Zhaofeng Liu
0
0
Retrieval-Augmented Generation (RAG) has emerged as a pivotal innovation in natural language processing, enhancing generative models by incorporating external information retrieval. Evaluating RAG systems, however, poses distinct challenges due to their hybrid structure and reliance on dynamic knowledge sources. We consequently enhanced an extensive survey and proposed an analysis framework for benchmarks of RAG systems, RAGR (Retrieval, Generation, Additional Requirement), designed to systematically analyze RAG benchmarks by focusing on measurable outputs and established truths. Specifically, we scrutinize and contrast multiple quantifiable metrics of the Retrieval and Generation component, such as relevance, accuracy, and faithfulness, of the internal links within the current RAG evaluation methods, covering the possible output and ground truth pairs. We also analyze the integration of additional requirements of different works, discuss the limitations of current benchmarks, and propose potential directions for further research to address these shortcomings and advance the field of RAG evaluation. In conclusion, this paper collates the challenges associated with RAG evaluation. It presents a thorough analysis and examination of existing methodologies for RAG benchmark design based on the proposed RGAR framework.
5/14/2024