Multi-Stage Balanced Distillation: Addressing Long-Tail Challenges in Sequence-Level Knowledge Distillation
2406.13114
0
0

Abstract
Large language models (LLMs) have significantly advanced various natural language processing tasks, but deploying them remains computationally expensive. Knowledge distillation (KD) is a promising solution, enabling the transfer of capabilities from larger teacher LLMs to more compact student models. Particularly, sequence-level KD, which distills rationale-based reasoning processes instead of merely final outcomes, shows great potential in enhancing students' reasoning capabilities. However, current methods struggle with sequence level KD under long-tailed data distributions, adversely affecting generalization on sparsely represented domains. We introduce the Multi-Stage Balanced Distillation (BalDistill) framework, which iteratively balances training data within a fixed computational budget. By dynamically selecting representative head domain examples and synthesizing tail domain examples, BalDistill achieves state-of-the-art performance across diverse long-tailed datasets, enhancing both the efficiency and efficacy of the distilled models.
Create account to get full access
Overview
- This paper proposes a novel approach called Multi-Stage Balanced Distillation (MSBD) to address challenges in sequence-level knowledge distillation, particularly for long-tail tokens.
- Knowledge distillation is a technique used to transfer knowledge from a large, complex model (the "teacher") to a smaller, more efficient model (the "student").
- The authors identify issues with existing sequence-level distillation methods, such as neglecting the long-tail tokens, and introduce MSBD to address these limitations.
Plain English Explanation
Knowledge distillation is a way to take the knowledge from a big, powerful machine learning model and transfer it to a smaller, more efficient model. This can be really helpful, as the smaller model can then be used in situations where the larger model might be too slow or resource-intensive.
However, the authors of this paper found that existing knowledge distillation methods often struggle with what they call the "long-tail" problem. This means that the smaller model tends to perform poorly on less common or more specialized tokens or outputs, even if the larger model is good at handling them.
To address this, the researchers developed a new approach called Multi-Stage Balanced Distillation (MSBD). The key idea behind MSBD is to break down the distillation process into multiple stages, focusing on the long-tail tokens in each stage to ensure the smaller model learns to handle them effectively.
By using this multi-stage approach and carefully balancing the training on common and rare tokens, the authors were able to create smaller models that performed much better on the long-tail challenges compared to traditional knowledge distillation methods. This could be particularly useful in applications where accurately handling a wide range of outputs is important, such as link to relevant paper on automatic scoring in science education or link to paper on paraphrase generation.
Technical Explanation
The authors begin by identifying the limitations of existing sequence-level knowledge distillation methods, which tend to neglect the long-tail tokens – the less common or more specialized outputs that the larger "teacher" model is able to handle, but the smaller "student" model struggles with.
To address this, the researchers propose Multi-Stage Balanced Distillation (MSBD), a novel approach that breaks down the distillation process into multiple stages. In each stage, the focus is on a different subset of the output tokens, with a particular emphasis on the long-tail tokens to ensure the student model learns to handle them effectively.
The key components of MSBD include:
- Token Grouping: The output tokens are divided into groups based on their frequency, with separate groups for the common and long-tail tokens.
- Staged Distillation: The distillation process is carried out in multiple stages, with each stage focusing on a different token group.
- Balanced Loss Optimization: The training loss is carefully balanced between the common and long-tail token groups to ensure the student model learns to handle both effectively.
Through extensive experiments on various sequence-to-sequence tasks, the authors demonstrate that MSBD significantly outperforms traditional knowledge distillation methods, especially in terms of handling the long-tail tokens. This includes link to paper on knowledge distillation for large language models and link to comprehensive study on sequence-level vs. token-level distillation.
Critical Analysis
The authors acknowledge that MSBD introduces additional complexity compared to traditional knowledge distillation approaches, as it requires the definition of token groups and the careful balancing of the training loss. This may increase the computational and implementation overhead, especially for large-scale models.
Additionally, the paper does not explore the impact of MSBD on the overall performance of the student model, beyond its ability to handle long-tail tokens. It would be valuable to understand how the multi-stage and balanced distillation approach affects the student model's performance on the common tokens and the overall task-level metrics.
Further research could also investigate the optimal number of stages, the criteria for defining token groups, and the tradeoffs between the complexity of the MSBD method and its practical benefits in real-world applications. Exploring the application of MSBD to other types of sequence-to-sequence tasks, such as link to paper on paraphrase generation, could also provide additional insights.
Conclusion
The Multi-Stage Balanced Distillation (MSBD) approach proposed in this paper offers a promising solution to the long-tail challenges in sequence-level knowledge distillation. By breaking down the distillation process into multiple stages and carefully balancing the training on common and rare tokens, the authors demonstrate significant improvements in the student model's ability to handle long-tail outputs.
This work has implications for a wide range of applications where accurate handling of diverse outputs is important, such as link to paper on automatic scoring in science education and link to paper on paraphrase generation. The MSBD approach could help bridge the gap between the capabilities of large, complex models and the practical constraints of smaller, more efficient models, expanding the reach of powerful machine learning techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

New!MLKD-BERT: Multi-level Knowledge Distillation for Pre-trained Language Models
Ying Zhang, Ziheng Yang, Shufan Ji
0
0
Knowledge distillation is an effective technique for pre-trained language model compression. Although existing knowledge distillation methods perform well for the most typical model BERT, they could be further improved in two aspects: the relation-level knowledge could be further explored to improve model performance; and the setting of student attention head number could be more flexible to decrease inference time. Therefore, we are motivated to propose a novel knowledge distillation method MLKD-BERT to distill multi-level knowledge in teacher-student framework. Extensive experiments on GLUE benchmark and extractive question answering tasks demonstrate that our method outperforms state-of-the-art knowledge distillation methods on BERT. In addition, MLKD-BERT can flexibly set student attention head number, allowing for substantial inference time decrease with little performance drop.
7/4/2024
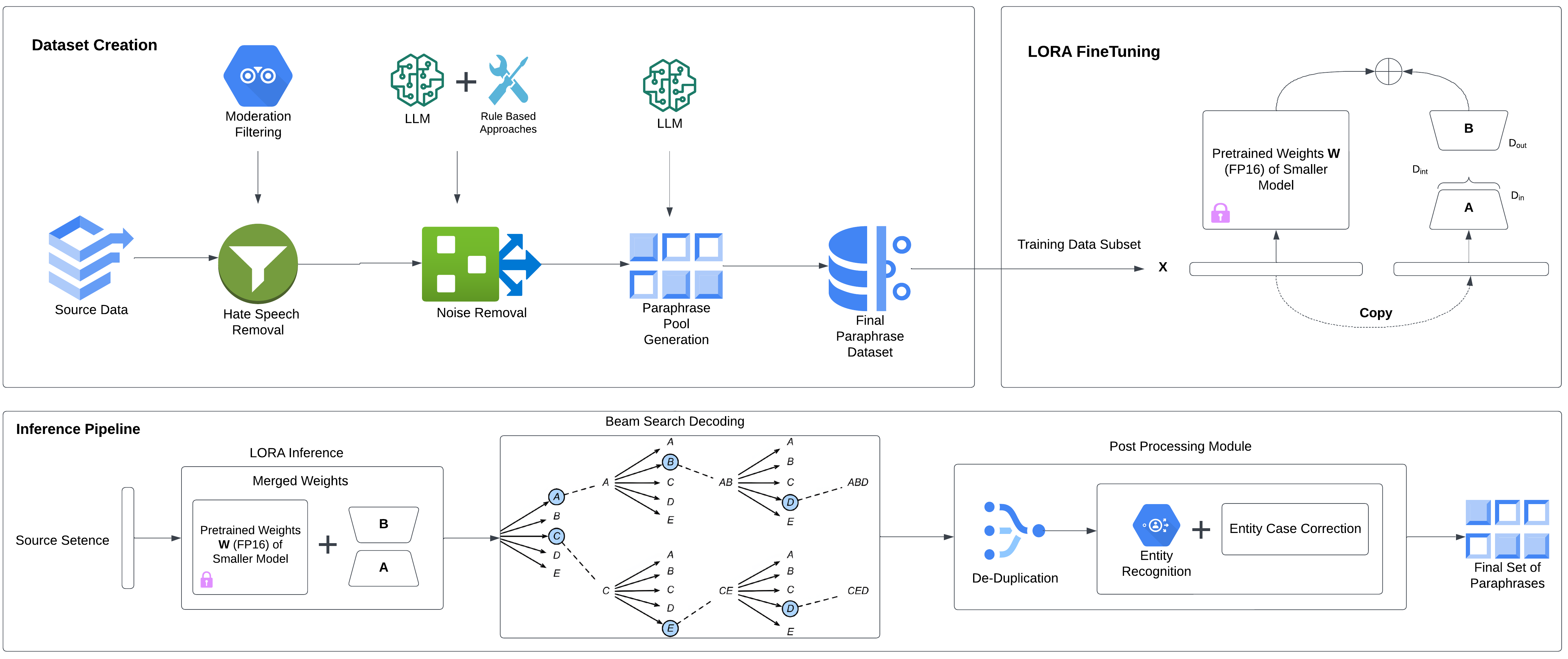
Parameter Efficient Diverse Paraphrase Generation Using Sequence-Level Knowledge Distillation
Lasal Jayawardena, Prasan Yapa
0
0
Over the past year, the field of Natural Language Generation (NLG) has experienced an exponential surge, largely due to the introduction of Large Language Models (LLMs). These models have exhibited the most effective performance in a range of domains within the Natural Language Processing and Generation domains. However, their application in domain-specific tasks, such as paraphrasing, presents significant challenges. The extensive number of parameters makes them difficult to operate on commercial hardware, and they require substantial time for inference, leading to high costs in a production setting. In this study, we tackle these obstacles by employing LLMs to develop three distinct models for the paraphrasing field, applying a method referred to as sequence-level knowledge distillation. These distilled models are capable of maintaining the quality of paraphrases generated by the LLM. They demonstrate faster inference times and the ability to generate diverse paraphrases of comparable quality. A notable characteristic of these models is their ability to exhibit syntactic diversity while also preserving lexical diversity, features previously uncommon due to existing data quality issues in datasets and not typically observed in neural-based approaches. Human evaluation of our models shows that there is only a 4% drop in performance compared to the LLM teacher model used in the distillation process, despite being 1000 times smaller. This research provides a significant contribution to the NLG field, offering a more efficient and cost-effective solution for paraphrasing tasks.
4/22/2024

Knowledge Distillation of LLM for Automatic Scoring of Science Education Assessments
Ehsan Latif, Luyang Fang, Ping Ma, Xiaoming Zhai
0
0
This study proposes a method for knowledge distillation (KD) of fine-tuned Large Language Models (LLMs) into smaller, more efficient, and accurate neural networks. We specifically target the challenge of deploying these models on resource-constrained devices. Our methodology involves training the smaller student model (Neural Network) using the prediction probabilities (as soft labels) of the LLM, which serves as a teacher model. This is achieved through a specialized loss function tailored to learn from the LLM's output probabilities, ensuring that the student model closely mimics the teacher's performance. To validate the performance of the KD approach, we utilized a large dataset, 7T, containing 6,684 student-written responses to science questions and three mathematical reasoning datasets with student-written responses graded by human experts. We compared accuracy with state-of-the-art (SOTA) distilled models, TinyBERT, and artificial neural network (ANN) models. Results have shown that the KD approach has 3% and 2% higher scoring accuracy than ANN and TinyBERT, respectively, and comparable accuracy to the teacher model. Furthermore, the student model size is 0.03M, 4,000 times smaller in parameters and x10 faster in inferencing than the teacher model and TinyBERT, respectively. The significance of this research lies in its potential to make advanced AI technologies accessible in typical educational settings, particularly for automatic scoring.
6/13/2024

New!DistiLLM: Towards Streamlined Distillation for Large Language Models
Jongwoo Ko, Sungnyun Kim, Tianyi Chen, Se-Young Yun
0
0
Knowledge distillation (KD) is widely used for compressing a teacher model to a smaller student model, reducing its inference cost and memory footprint while preserving model capabilities. However, current KD methods for auto-regressive sequence models (e.g., large language models) suffer from missing a standardized objective function. Moreover, the recent use of student-generated outputs to address training-inference mismatches has significantly escalated computational costs. To tackle these issues, we introduce DistiLLM, a more effective and efficient KD framework for auto-regressive language models. DistiLLM comprises two components: (1) a novel skew Kullback-Leibler divergence loss, where we unveil and leverage its theoretical properties, and (2) an adaptive off-policy approach designed to enhance the efficiency in utilizing student-generated outputs. Extensive experiments, including instruction-following tasks, demonstrate the effectiveness of DistiLLM in building high-performing student models while achieving up to 4.3$times$ speedup compared to recent KD methods.
7/4/2024