Multi-step Knowledge Retrieval and Inference over Unstructured Data

0

Sign in to get full access
Overview
- The paper presents a novel approach for multi-step knowledge retrieval and inference over unstructured data, which aims to enable language models to engage in more complex and contextual reasoning.
- The proposed method involves a multi-stage process of retrieving relevant information from a knowledge base, combining it with the input query, and then using a language model to generate a final answer.
- The researchers demonstrate the effectiveness of their approach through experiments on several benchmark tasks, showing improvements over existing single-stage retrieval and reasoning systems.
Plain English Explanation
The paper describes a new way for AI systems to answer complex questions that require drawing information from multiple sources. Typical language models today can only process a single query at a time and provide a direct answer. But many real-world questions involve a series of steps - first finding relevant background information, then using that to reason about the question and formulate a final response.
The researchers' approach involves breaking this process down into multiple stages. First, the system retrieves the most relevant information from a database or knowledge base to help contextualize the original query. It then combines this retrieved information with the initial question and passes it through a language model, which can use that richer context to generate a more thoughtful and comprehensive answer.
By layering these steps, the system is able to engage in more nuanced and contextual reasoning, similar to how humans might approach a complex problem. The experiments show this leads to better performance on benchmark tasks that require this kind of multi-step inference, compared to simpler single-stage systems.
Ultimately, this work represents an important step towards building AI assistants that can handle more open-ended, real-world queries, rather than just looking up facts or giving scripted responses. It suggests a path for language models to become more flexible, knowledgeable, and capable of human-like reasoning. <a href="https://aimodels.fyi/papers/arxiv/corpuslm-towards-unified-language-model-corpus-knowledge">Advances like this</a> could enable AI to be more helpful in a wide range of applications.
Technical Explanation
The key innovation in this paper is a multi-step approach to knowledge retrieval and inference, which the authors call "Multi-Step Inference" (MSI). Traditional language models typically perform a single-stage process of taking an input query, retrieving relevant information from a knowledge base or corpus, and then generating a final answer.
In contrast, the MSI framework breaks this down into a multi-step procedure. First, an initial retrieval module uses the input query to find the most relevant information from a knowledge source. This retrieved information is then combined with the original query and passed to a reasoning module, which uses a language model to generate the final output.
This staged approach allows the system to iteratively build up context and perform more nuanced reasoning, compared to a monolithic single-stage process. The authors demonstrate the effectiveness of MSI through experiments on several benchmark tasks that require complex, multi-step inference, such as open-domain question answering and multi-hop reasoning. <a href="https://aimodels.fyi/papers/arxiv/survey-rag-meeting-llms-towards-retrieval-augmented">Their results show significant improvements</a> over existing single-stage retrieval and reasoning models.
The paper also explores different architectural variations of the MSI framework, including using transformers for the retrieval and reasoning modules, as well as techniques for iteratively refining the retrieved information. <a href="https://aimodels.fyi/papers/arxiv/kg-rag-bridging-gap-between-knowledge-creativity">These insights</a> provide a foundation for future research on building more capable and flexible language models that can engage in richer, more contextual reasoning.
Critical Analysis
The authors provide a thorough evaluation of their MSI approach, demonstrating its effectiveness on a range of benchmark tasks. However, the paper does not deeply explore the limitations or potential downsides of this multi-step framework.
One area that could use further examination is the impact of compounding errors - if the initial retrieval step fails to find relevant information, or introduces some biases or incorrect assumptions, how does that affect the downstream reasoning and final output? The authors mention the potential for iterative refinement, but more analysis on error propagation and robustness would be valuable.
Additionally, the paper focuses on relatively constrained benchmark tasks, rather than open-ended, real-world scenarios. <a href="https://aimodels.fyi/papers/arxiv/empowering-large-language-models-to-set-up">As language models are deployed in more practical applications</a>, there may be unique challenges and edge cases that arise when using a multi-step inference approach that are not captured by the current experiments.
Overall, this work represents an important advance in building more capable and contextual language models. However, further research is needed to fully understand the tradeoffs, limitations, and scalability of the MSI framework, particularly as it is applied to more complex, open-ended tasks. <a href="https://aimodels.fyi/papers/arxiv/tool-calling-enhancing-medication-consultation-via-retrieval">Continued innovation in this direction</a> could lead to significant breakthroughs in AI's ability to engage in human-like reasoning and problem-solving.
Conclusion
This paper presents a novel multi-step approach to knowledge retrieval and inference, which aims to enable language models to engage in more contextual and nuanced reasoning. By breaking down the process into iterative stages of retrieval, combination, and reasoning, the system is able to outperform traditional single-stage models on benchmark tasks requiring complex, multi-hop inference.
The insights and techniques described in this work represent an important step towards building more capable and flexible language models that can handle open-ended, real-world queries. While further research is needed to fully understand the limitations and scaling challenges of this multi-step framework, this paper lays the groundwork for continued advancements in AI's ability to engage in human-like reasoning and problem-solving.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multi-step Knowledge Retrieval and Inference over Unstructured Data
Aditya Kalyanpur, Kailash Karthik Saravanakumar, Victor Barres, CJ McFate, Lori Moon, Nati Seifu, Maksim Eremeev, Jose Barrera, Abraham Bautista-Castillo, Eric Brown, David Ferrucci
The advent of Large Language Models (LLMs) and Generative AI has revolutionized natural language applications across various domains. However, high-stakes decision-making tasks in fields such as medical, legal and finance require a level of precision, comprehensiveness, and logical consistency that pure LLM or Retrieval-Augmented-Generation (RAG) approaches often fail to deliver. At Elemental Cognition (EC), we have developed a neuro-symbolic AI platform to tackle these problems. The platform integrates fine-tuned LLMs for knowledge extraction and alignment with a robust symbolic reasoning engine for logical inference, planning and interactive constraint solving. We describe Cora, a Collaborative Research Assistant built on this platform, that is designed to perform complex research and discovery tasks in high-stakes domains. This paper discusses the multi-step inference challenges inherent in such domains, critiques the limitations of existing LLM-based methods, and demonstrates how Cora's neuro-symbolic approach effectively addresses these issues. We provide an overview of the system architecture, key algorithms for knowledge extraction and formal reasoning, and present preliminary evaluation results that highlight Cora's superior performance compared to well-known LLM and RAG baselines.
Read more7/26/2024
0
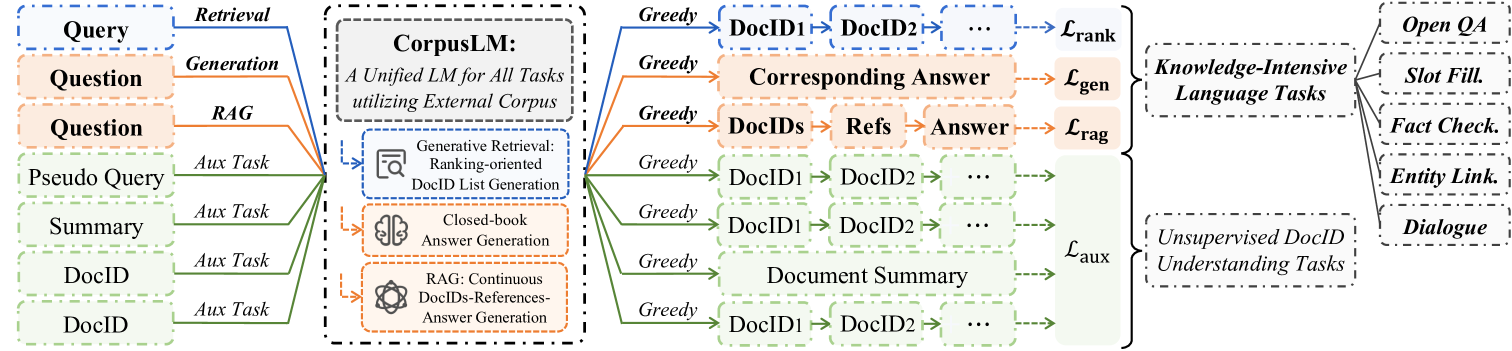
CorpusLM: Towards a Unified Language Model on Corpus for Knowledge-Intensive Tasks
Xiaoxi Li, Zhicheng Dou, Yujia Zhou, Fangchao Liu
Large language models (LLMs) have gained significant attention in various fields but prone to hallucination, especially in knowledge-intensive (KI) tasks. To address this, retrieval-augmented generation (RAG) has emerged as a popular solution to enhance factual accuracy. However, traditional retrieval modules often rely on large document index and disconnect with generative tasks. With the advent of generative retrieval (GR), language models can retrieve by directly generating document identifiers (DocIDs), offering superior performance in retrieval tasks. However, the potential relationship between GR and downstream tasks remains unexplored. In this paper, we propose textbf{CorpusLM}, a unified language model that leverages external corpus to tackle various knowledge-intensive tasks by integrating generative retrieval, closed-book generation, and RAG through a unified greedy decoding process. We design the following mechanisms to facilitate effective retrieval and generation, and improve the end-to-end effectiveness of KI tasks: (1) We develop a ranking-oriented DocID list generation strategy, which refines GR by directly learning from a DocID ranking list, to improve retrieval quality. (2) We design a continuous DocIDs-References-Answer generation strategy, which facilitates effective and efficient RAG. (3) We employ well-designed unsupervised DocID understanding tasks, to comprehend DocID semantics and their relevance to downstream tasks. We evaluate our approach on the widely used KILT benchmark with two variants of backbone models, i.e., T5 and Llama2. Experimental results demonstrate the superior performance of our models in both retrieval and downstream tasks.
Read more4/23/2024

0
Think-on-Graph 2.0: Deep and Interpretable Large Language Model Reasoning with Knowledge Graph-guided Retrieval
Shengjie Ma, Chengjin Xu, Xuhui Jiang, Muzhi Li, Huaren Qu, Jian Guo
Retrieval-augmented generation (RAG) has significantly advanced large language models (LLMs) by enabling dynamic information retrieval to mitigate knowledge gaps and hallucinations in generated content. However, these systems often falter with complex reasoning and consistency across diverse queries. In this work, we present Think-on-Graph 2.0, an enhanced RAG framework that aligns questions with the knowledge graph and uses it as a navigational tool, which deepens and refines the RAG paradigm for information collection and integration. The KG-guided navigation fosters deep and long-range associations to uphold logical consistency and optimize the scope of retrieval for precision and interoperability. In conjunction, factual consistency can be better ensured through semantic similarity guided by precise directives. ToG${2.0}$ not only improves the accuracy and reliability of LLMs' responses but also demonstrates the potential of hybrid structured knowledge systems to significantly advance LLM reasoning, aligning it closer to human-like performance. We conducted extensive experiments on four public datasets to demonstrate the advantages of our method compared to the baseline.
Read more8/7/2024
💬
0
A Survey on RAG Meets LLMs: Towards Retrieval-Augmented Large Language Models
Wenqi Fan, Yujuan Ding, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat-Seng Chua, Qing Li
As one of the most advanced techniques in AI, Retrieval-Augmented Generation (RAG) can offer reliable and up-to-date external knowledge, providing huge convenience for numerous tasks. Particularly in the era of AI-Generated Content (AIGC), the powerful capacity of retrieval in providing additional knowledge enables RAG to assist existing generative AI in producing high-quality outputs. Recently, Large Language Models (LLMs) have demonstrated revolutionary abilities in language understanding and generation, while still facing inherent limitations, such as hallucinations and out-of-date internal knowledge. Given the powerful abilities of RAG in providing the latest and helpful auxiliary information, Retrieval-Augmented Large Language Models (RA-LLMs) have emerged to harness external and authoritative knowledge bases, rather than solely relying on the model's internal knowledge, to augment the generation quality of LLMs. In this survey, we comprehensively review existing research studies in RA-LLMs, covering three primary technical perspectives: architectures, training strategies, and applications. As the preliminary knowledge, we briefly introduce the foundations and recent advances of LLMs. Then, to illustrate the practical significance of RAG for LLMs, we systematically review mainstream relevant work by their architectures, training strategies, and application areas, detailing specifically the challenges of each and the corresponding capabilities of RA-LLMs. Finally, to deliver deeper insights, we discuss current limitations and several promising directions for future research. Updated information about this survey can be found at https://advanced-recommender-systems.github.io/RAG-Meets-LLMs/
Read more6/18/2024