Knowledge Distillation via the Target-aware Transformer
2205.10793
0
0
✨
Abstract
Knowledge distillation becomes a de facto standard to improve the performance of small neural networks. Most of the previous works propose to regress the representational features from the teacher to the student in a one-to-one spatial matching fashion. However, people tend to overlook the fact that, due to the architecture differences, the semantic information on the same spatial location usually vary. This greatly undermines the underlying assumption of the one-to-one distillation approach. To this end, we propose a novel one-to-all spatial matching knowledge distillation approach. Specifically, we allow each pixel of the teacher feature to be distilled to all spatial locations of the student features given its similarity, which is generated from a target-aware transformer. Our approach surpasses the state-of-the-art methods by a significant margin on various computer vision benchmarks, such as ImageNet, Pascal VOC and COCOStuff10k. Code is available at https://github.com/sihaoevery/TaT.
Create account to get full access
Overview
- This paper proposes a novel approach to knowledge distillation, which is a technique used to improve the performance of small neural networks.
- Most previous work on knowledge distillation has focused on a one-to-one spatial matching approach, where the student network learns to match the feature representations of the teacher network in a one-to-one spatial manner.
- The authors argue that this approach is limited because the semantic information at the same spatial locations can vary between the teacher and student networks due to architectural differences.
- To address this, the authors propose a one-to-all spatial matching knowledge distillation approach, where each pixel in the teacher's feature map is distilled to all spatial locations in the student's feature map based on their similarity.
Plain English Explanation
In machine learning, knowledge distillation is a technique used to improve the performance of small neural networks. The basic idea is to train a smaller "student" network to mimic the behavior of a larger "teacher" network, which is typically more accurate but also more computationally expensive.
Most previous approaches to knowledge distillation have tried to match the feature representations of the teacher network to the student network in a one-to-one fashion. This means that each spatial location in the teacher's feature map is matched to the corresponding spatial location in the student's feature map.
However, the authors of this paper argue that this approach has a key limitation: due to architectural differences between the teacher and student networks, the semantic information at the same spatial locations can actually be quite different. This undermines the assumptions behind the one-to-one matching approach.
To address this, the authors propose a new one-to-all spatial matching knowledge distillation approach. Instead of just matching the features at the same spatial locations, their method allows each pixel in the teacher's feature map to be distilled to all spatial locations in the student's feature map, based on the similarity between them. This is achieved using a target-aware transformer that generates these spatial similarities.
The authors show that their approach outperforms state-of-the-art knowledge distillation methods on several computer vision benchmarks, such as ImageNet, Pascal VOC, and COCOStuff10k. This suggests that their one-to-all spatial matching strategy is a more effective way to transfer knowledge from a large teacher network to a smaller student network.
Technical Explanation
The key innovation in this paper is the one-to-all spatial matching knowledge distillation approach. Rather than the typical one-to-one spatial matching, the authors propose a method that allows each pixel in the teacher's feature map to be distilled to all spatial locations in the student's feature map.
This is achieved by first using a target-aware transformer to generate a spatial similarity matrix between the teacher and student feature maps. This similarity matrix is then used to weight the distillation loss, so that each pixel in the teacher's features is distilled to the student's features based on their similarity.
The authors hypothesize that this one-to-all approach is more effective than one-to-one matching because it can better handle the semantic differences that can arise between the teacher and student networks due to architectural differences.
In their experiments, the authors evaluate their approach on several computer vision benchmarks, including ImageNet for image classification, Pascal VOC for object detection, and COCOStuff10k for semantic segmentation. They show that their method significantly outperforms state-of-the-art knowledge distillation techniques across these tasks.
Critical Analysis
The authors make a compelling case for the limitations of the traditional one-to-one spatial matching approach to knowledge distillation, and their proposed one-to-all strategy seems to be an effective solution. However, there are a few potential caveats and areas for further research that could be explored:
-
Computational Complexity: The use of a transformer module to generate the spatial similarity matrix may add significant computational overhead, especially for larger networks. The authors should examine the trade-offs between the performance gains and the additional computational cost.
-
Interpretability: While the one-to-all approach seems to improve performance, it may be less interpretable than the one-to-one method. It could be interesting to investigate ways to make the distillation process more transparent and understandable.
-
Generalization: The authors have primarily evaluated their method on computer vision tasks, but it would be valuable to see how it performs on other domains, such as natural language processing or speech recognition, where knowledge distillation is also widely used.
-
Broader Context: The authors could situate their work more explicitly within the broader context of knowledge distillation research, highlighting how it builds upon or differs from other state-of-the-art approaches.
Overall, this paper presents a novel and promising approach to knowledge distillation that appears to offer significant performance improvements. However, as with any research, there are opportunities for further exploration and refinement.
Conclusion
This paper introduces a novel one-to-all spatial matching knowledge distillation approach that addresses the limitations of the traditional one-to-one matching method. By allowing each pixel in the teacher's feature map to be distilled to all spatial locations in the student's feature map based on their similarity, the authors demonstrate significant performance gains on various computer vision benchmarks.
The key innovation is the use of a target-aware transformer to generate the spatial similarity matrix, which enables more effective transfer of semantic information between the teacher and student networks.
This work contributes to the ongoing efforts to improve the efficiency and effectiveness of neural networks, particularly in resource-constrained settings where small, fast models are desirable. The authors' one-to-all distillation approach represents an important step forward in the field of knowledge distillation and could have significant implications for a wide range of practical applications in computer vision and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
Multi-Task Multi-Scale Contrastive Knowledge Distillation for Efficient Medical Image Segmentation
Risab Biswas
0
0
This thesis aims to investigate the feasibility of knowledge transfer between neural networks for medical image segmentation tasks, specifically focusing on the transfer from a larger multi-task Teacher network to a smaller Student network. In the context of medical imaging, where the data volumes are often limited, leveraging knowledge from a larger pre-trained network could be useful. The primary objective is to enhance the performance of a smaller student model by incorporating knowledge representations acquired by a teacher model that adopts a multi-task pre-trained architecture trained on CT images, to a more resource-efficient student network, which can essentially be a smaller version of the same, trained on a mere 50% of the data than that of the teacher model. To facilitate knowledge transfer between the two models, we devised an architecture incorporating multi-scale feature distillation and supervised contrastive learning. Our study aims to improve the student model's performance by integrating knowledge representations from the teacher model. We investigate whether this approach is particularly effective in scenarios with limited computational resources and limited training data availability. To assess the impact of multi-scale feature distillation, we conducted extensive experiments. We also conducted a detailed ablation study to determine whether it is essential to distil knowledge at various scales, including low-level features from encoder layers, for effective knowledge transfer. In addition, we examine different losses in the knowledge distillation process to gain insights into their effects on overall performance.
6/6/2024
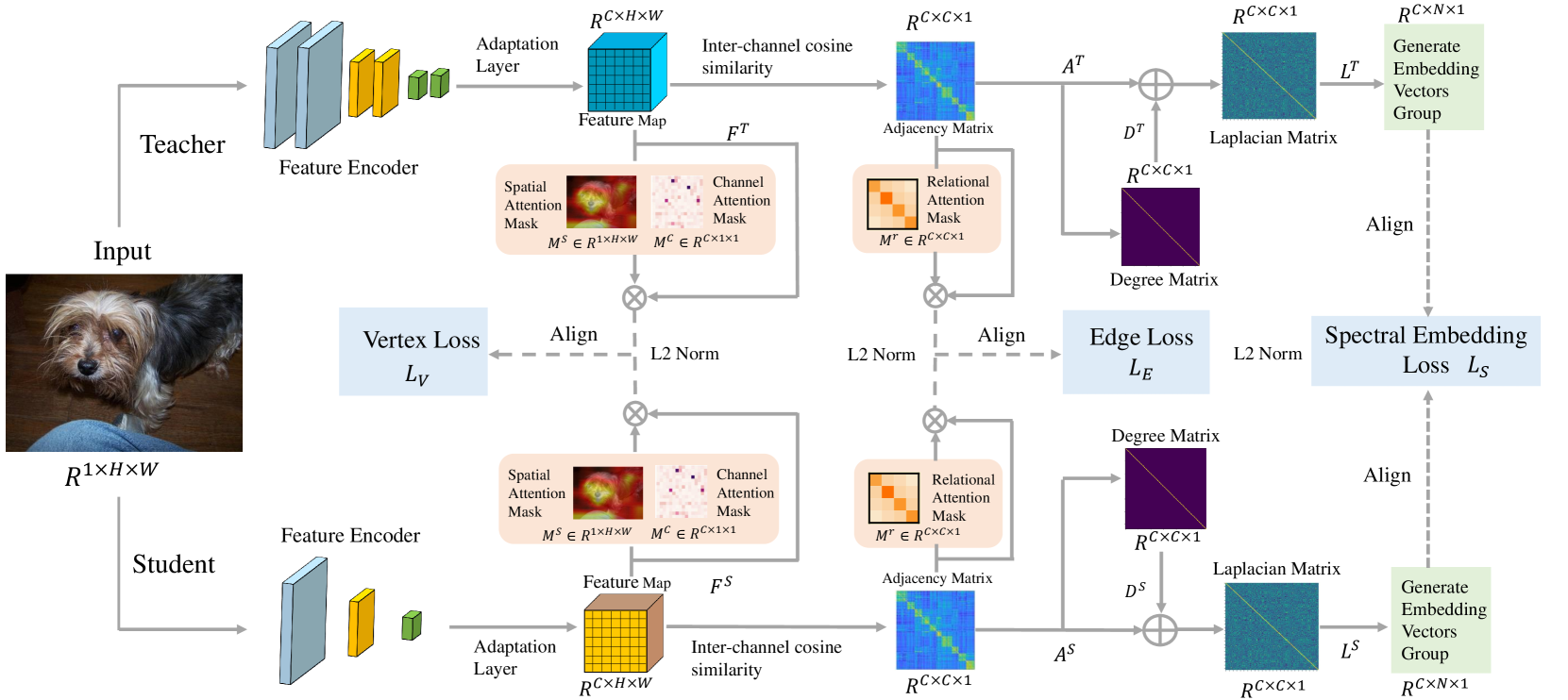
Exploring Graph-based Knowledge: Multi-Level Feature Distillation via Channels Relational Graph
Zhiwei Wang, Jun Huang, Longhua Ma, Chengyu Wu, Hongyu Ma
0
0
In visual tasks, large teacher models capture essential features and deep information, enhancing performance. However, distilling this information into smaller student models often leads to performance loss due to structural differences and capacity limitations. To tackle this, we propose a distillation framework based on graph knowledge, including a multi-level feature alignment strategy and an attention-guided mechanism to provide a targeted learning trajectory for the student model. We emphasize spectral embedding (SE) as a key technique in our distillation process, which merges the student's feature space with the relational knowledge and structural complexities similar to the teacher network. This method captures the teacher's understanding in a graph-based representation, enabling the student model to more accurately mimic the complex structural dependencies present in the teacher model. Compared to methods that focus only on specific distillation areas, our strategy not only considers key features within the teacher model but also endeavors to capture the relationships and interactions among feature sets, encoding these complex pieces of information into a graph structure to understand and utilize the dynamic relationships among these pieces of information from a global perspective. Experiments show that our method outperforms previous feature distillation methods on the CIFAR-100, MS-COCO, and Pascal VOC datasets, proving its efficiency and applicability.
5/17/2024
🌐
Toward Student-Oriented Teacher Network Training For Knowledge Distillation
Chengyu Dong, Liyuan Liu, Jingbo Shang
0
0
How to conduct teacher training for knowledge distillation is still an open problem. It has been widely observed that a best-performing teacher does not necessarily yield the best-performing student, suggesting a fundamental discrepancy between the current teacher training practice and the ideal teacher training strategy. To fill this gap, we explore the feasibility of training a teacher that is oriented toward student performance with empirical risk minimization (ERM). Our analyses are inspired by the recent findings that the effectiveness of knowledge distillation hinges on the teacher's capability to approximate the true label distribution of training inputs. We theoretically establish that the ERM minimizer can approximate the true label distribution of training data as long as the feature extractor of the learner network is Lipschitz continuous and is robust to feature transformations. In light of our theory, we propose a teacher training method SoTeacher which incorporates Lipschitz regularization and consistency regularization into ERM. Experiments on benchmark datasets using various knowledge distillation algorithms and teacher-student pairs confirm that SoTeacher can improve student accuracy consistently.
5/10/2024
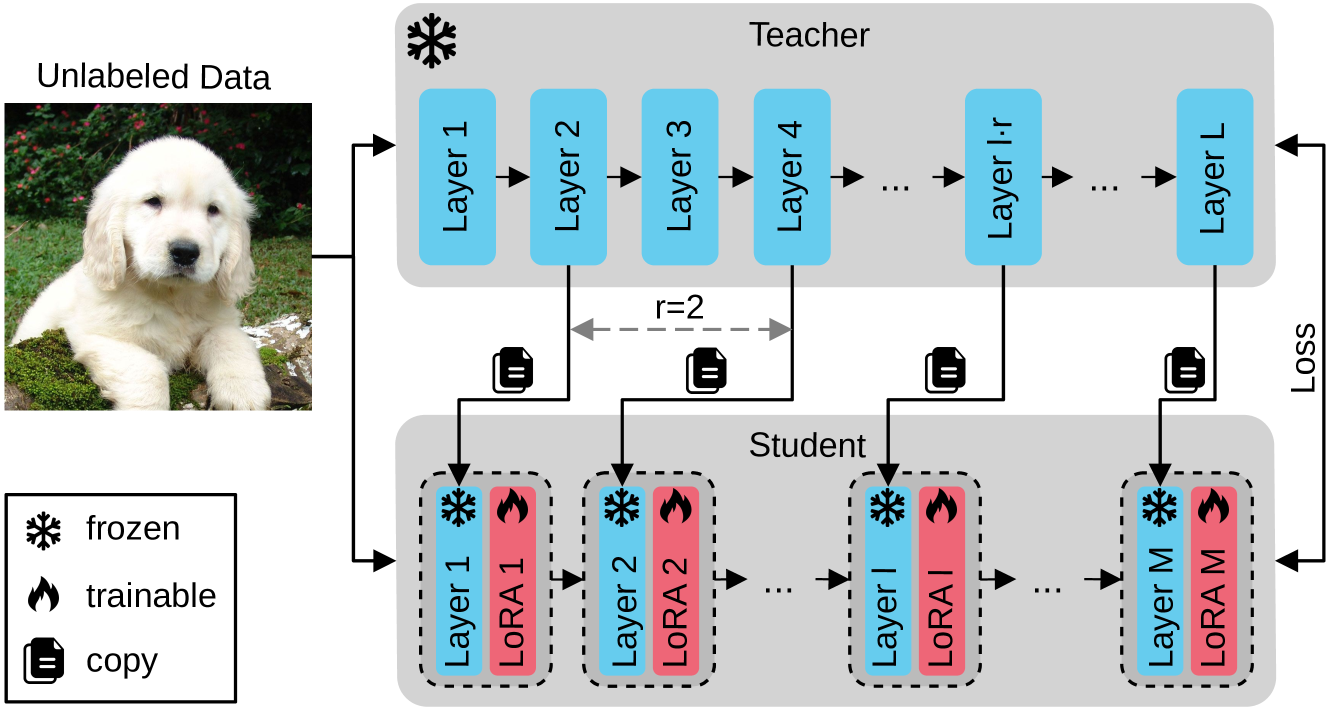
Weight Copy and Low-Rank Adaptation for Few-Shot Distillation of Vision Transformers
Diana-Nicoleta Grigore, Mariana-Iuliana Georgescu, Jon Alvarez Justo, Tor Johansen, Andreea Iuliana Ionescu, Radu Tudor Ionescu
0
0
Few-shot knowledge distillation recently emerged as a viable approach to harness the knowledge of large-scale pre-trained models, using limited data and computational resources. In this paper, we propose a novel few-shot feature distillation approach for vision transformers. Our approach is based on two key steps. Leveraging the fact that vision transformers have a consistent depth-wise structure, we first copy the weights from intermittent layers of existing pre-trained vision transformers (teachers) into shallower architectures (students), where the intermittence factor controls the complexity of the student transformer with respect to its teacher. Next, we employ an enhanced version of Low-Rank Adaptation (LoRA) to distill knowledge into the student in a few-shot scenario, aiming to recover the information processing carried out by the skipped teacher layers. We present comprehensive experiments with supervised and self-supervised transformers as teachers, on five data sets from various domains, including natural, medical and satellite images. The empirical results confirm the superiority of our approach over competitive baselines. Moreover, the ablation results demonstrate the usefulness of each component of the proposed pipeline.
4/16/2024