Aligning in a Compact Space: Contrastive Knowledge Distillation between Heterogeneous Architectures

0

Sign in to get full access
Overview
- This paper presents a novel approach called Contrastive Knowledge Distillation (CKD) for transferring knowledge between heterogeneous neural network architectures.
- The key idea is to align the representations of the student and teacher models in a compact embedding space using contrastive learning, which helps the student model mimic the behavior of the larger and more complex teacher model.
- The authors demonstrate the effectiveness of CKD on various tasks and model configurations, showing significant performance improvements over standard knowledge distillation techniques.
Plain English Explanation
The paper is about a method called Contrastive Knowledge Distillation (CKD) that can help smaller, simpler machine learning models perform better by learning from larger, more complex models. The basic idea is to have the smaller model learn to produce similar "representations" or internal encodings as the larger model, even though their architectures are quite different.
To do this, the researchers use a technique called contrastive learning, which encourages the representations of the smaller and larger models to be close together for the same input, but far apart for different inputs. This helps the smaller model capture the key insights and patterns that the larger model has learned, even though it has a much more compact and efficient architecture.
The researchers show that this CKD approach leads to significant performance improvements compared to traditional knowledge distillation techniques, across a variety of different tasks and model configurations. In other words, the smaller models trained with CKD can achieve higher accuracy and performance, while still being much more compact and efficient than the larger teacher models.
This is an important result, as it provides a way to effectively "distill" the knowledge from large, complex models into smaller, more practical models that can be deployed in real-world applications with constraints on memory, compute, or power consumption. The CKD approach builds on prior work in knowledge distillation and contrastive learning, but introduces a novel way to align the representations of the student and teacher models in a compact embedding space.
Technical Explanation
The key technical innovation presented in this paper is the Contrastive Knowledge Distillation (CKD) framework for transferring knowledge between heterogeneous neural network architectures. The core idea is to align the representations of the student and teacher models in a compact embedding space using contrastive learning.
Specifically, the authors define a contrastive loss function that encourages the student model to produce representations that are similar to the teacher model for the same input, but dissimilar for different inputs. This contrastive objective helps the student model capture the key semantic patterns and relationships learned by the larger, more complex teacher model, even though their architectural configurations are quite different.
The authors evaluate CKD on a range of tasks and model configurations, including image classification, object detection, and natural language processing. Across these diverse settings, they demonstrate that CKD significantly outperforms standard knowledge distillation techniques, leading to higher accuracy and performance for the student models.
The authors also provide theoretical analysis to better understand the properties and behavior of CKD. They show that the contrastive objective encourages the student model to learn a more generalizable and transferable representation, which can lead to improved performance on downstream tasks.
Overall, the CKD approach represents an important advancement in the field of knowledge distillation, providing a effective way to distill the knowledge from large, complex models into smaller, more efficient architectures. This has significant practical implications for deploying high-performing machine learning models in resource-constrained environments, such as on edge devices or mobile applications.
Critical Analysis
The paper presents a well-designed and thorough empirical evaluation of the proposed CKD framework, demonstrating its effectiveness across a range of tasks and model configurations. The authors also provide a solid theoretical grounding for the contrastive objective and its desirable properties.
However, the paper does not address several important limitations and areas for further research. For example, the authors do not investigate the sensitivity of CKD to hyperparameter settings or the training data used for the student and teacher models. It would be valuable to understand how robust the CKD approach is to these factors, as this would inform its practical applicability in real-world scenarios.
Additionally, the paper does not explore the scalability of CKD to larger and more complex model architectures. As deep learning models continue to grow in size and complexity, it will be important to understand how well CKD can handle the transfer of knowledge between truly massive teacher and student models.
Another potential area for further research is the interaction between CKD and other knowledge distillation techniques, such as FreeKD or target-aware distillation. Combining CKD with other complementary approaches could potentially lead to even greater performance gains for the student models.
Overall, the CKD framework represents an important and promising step forward in the field of knowledge distillation. However, further research is needed to fully understand its capabilities, limitations, and potential for real-world applications.
Conclusion
This paper introduces a novel Contrastive Knowledge Distillation (CKD) framework for transferring knowledge between heterogeneous neural network architectures. The key innovation is the use of contrastive learning to align the representations of the student and teacher models in a compact embedding space, which helps the student model effectively mimic the behavior of the larger and more complex teacher model.
The authors demonstrate the effectiveness of CKD across a range of tasks and model configurations, showing significant performance improvements over standard knowledge distillation techniques. This suggests that CKD is a powerful tool for distilling the knowledge from large, complex models into smaller, more efficient architectures, with important implications for deploying high-performing machine learning models in resource-constrained environments.
While the paper presents a strong technical contribution, it also identifies several important areas for further research, such as understanding the sensitivity of CKD to hyperparameters and data, exploring its scalability to larger models, and investigating its interaction with other knowledge distillation approaches. Addressing these open questions will be crucial for realizing the full potential of CKD and advancing the state of the art in model compression and efficient deep learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Aligning in a Compact Space: Contrastive Knowledge Distillation between Heterogeneous Architectures
Hongjun Wu, Li Xiao, Xingkuo Zhang, Yining Miao
Knowledge distillation is commonly employed to compress neural networks, reducing the inference costs and memory footprint. In the scenario of homogenous architecture, feature-based methods have been widely validated for their effectiveness. However, in scenarios where the teacher and student models are of heterogeneous architectures, the inherent differences in feature representation significantly degrade the performance of these methods. Recent studies have highlighted that low-frequency components constitute the majority of image features. Motivated by this, we propose a Low-Frequency Components-based Contrastive Knowledge Distillation (LFCC) framework that significantly enhances the performance of feature-based distillation between heterogeneous architectures. Specifically, we designe a set of multi-scale low-pass filters to extract the low-frequency components of intermediate features from both the teacher and student models, aligning them in a compact space to overcome architectural disparities. Moreover, leveraging the intrinsic pairing characteristic of the teacher-student framework, we design an innovative sample-level contrastive learning framework that adeptly restructures the constraints of within-sample feature similarity and between-sample feature divergence into a contrastive learning task. This strategy enables the student model to capitalize on intra-sample feature congruence while simultaneously enhancing the discrimination of features among disparate samples. Consequently, our LFCC framework accurately captures the commonalities in feature representation across heterogeneous architectures. Extensive evaluations and empirical analyses across three architectures (CNNs, Transformers, and MLPs) demonstrate that LFCC achieves superior performance on the challenging benchmarks of ImageNet-1K and CIFAR-100. All codes will be publicly available.
Read more5/30/2024
🖼️
0
Multi-Task Multi-Scale Contrastive Knowledge Distillation for Efficient Medical Image Segmentation
Risab Biswas
This thesis aims to investigate the feasibility of knowledge transfer between neural networks for medical image segmentation tasks, specifically focusing on the transfer from a larger multi-task Teacher network to a smaller Student network. In the context of medical imaging, where the data volumes are often limited, leveraging knowledge from a larger pre-trained network could be useful. The primary objective is to enhance the performance of a smaller student model by incorporating knowledge representations acquired by a teacher model that adopts a multi-task pre-trained architecture trained on CT images, to a more resource-efficient student network, which can essentially be a smaller version of the same, trained on a mere 50% of the data than that of the teacher model. To facilitate knowledge transfer between the two models, we devised an architecture incorporating multi-scale feature distillation and supervised contrastive learning. Our study aims to improve the student model's performance by integrating knowledge representations from the teacher model. We investigate whether this approach is particularly effective in scenarios with limited computational resources and limited training data availability. To assess the impact of multi-scale feature distillation, we conducted extensive experiments. We also conducted a detailed ablation study to determine whether it is essential to distil knowledge at various scales, including low-level features from encoder layers, for effective knowledge transfer. In addition, we examine different losses in the knowledge distillation process to gain insights into their effects on overall performance.
Read more6/6/2024
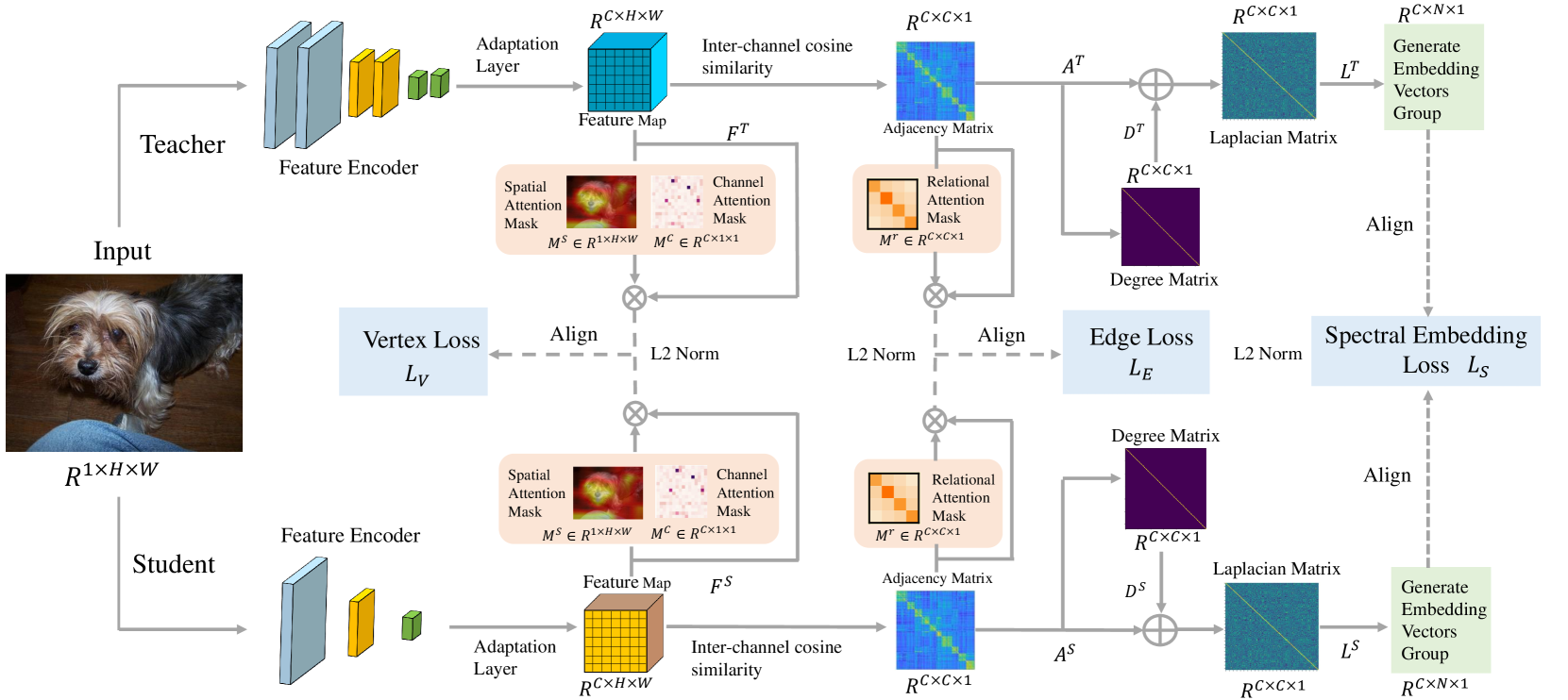
0
Exploring Graph-based Knowledge: Multi-Level Feature Distillation via Channels Relational Graph
Zhiwei Wang, Jun Huang, Longhua Ma, Chengyu Wu, Hongyu Ma
In visual tasks, large teacher models capture essential features and deep information, enhancing performance. However, distilling this information into smaller student models often leads to performance loss due to structural differences and capacity limitations. To tackle this, we propose a distillation framework based on graph knowledge, including a multi-level feature alignment strategy and an attention-guided mechanism to provide a targeted learning trajectory for the student model. We emphasize spectral embedding (SE) as a key technique in our distillation process, which merges the student's feature space with the relational knowledge and structural complexities similar to the teacher network. This method captures the teacher's understanding in a graph-based representation, enabling the student model to more accurately mimic the complex structural dependencies present in the teacher model. Compared to methods that focus only on specific distillation areas, our strategy not only considers key features within the teacher model but also endeavors to capture the relationships and interactions among feature sets, encoding these complex pieces of information into a graph structure to understand and utilize the dynamic relationships among these pieces of information from a global perspective. Experiments show that our method outperforms previous feature distillation methods on the CIFAR-100, MS-COCO, and Pascal VOC datasets, proving its efficiency and applicability.
Read more5/17/2024
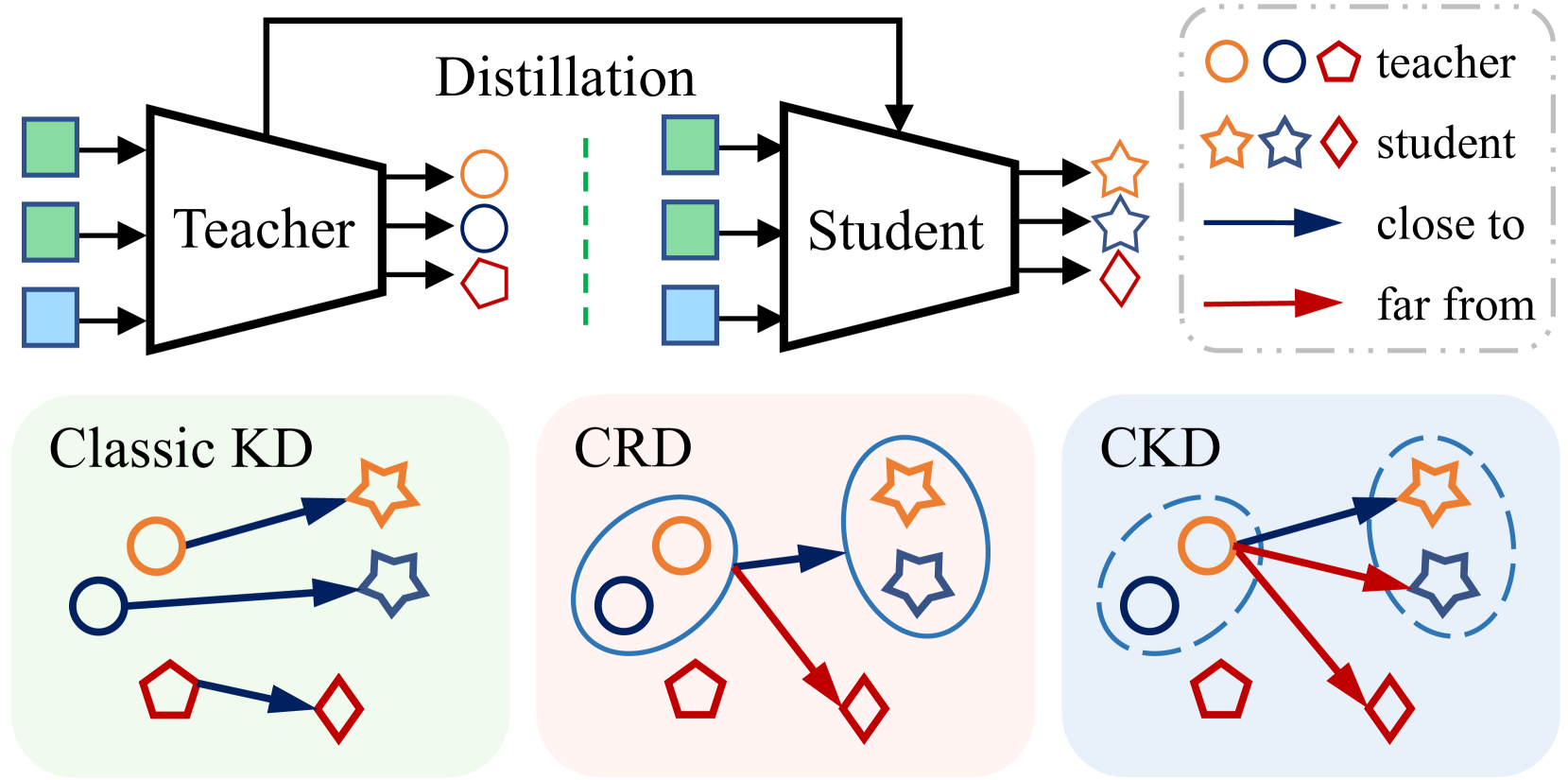
0
CKD: Contrastive Knowledge Distillation from A Sample-wise Perspective
Wencheng Zhu, Xin Zhou, Pengfei Zhu, Yu Wang, Qinghua Hu
In this paper, we present a simple yet effective contrastive knowledge distillation approach, which can be formulated as a sample-wise alignment problem with intra- and inter-sample constraints. Unlike traditional knowledge distillation methods that concentrate on maximizing feature similarities or preserving class-wise semantic correlations between teacher and student features, our method attempts to recover the dark knowledge by aligning sample-wise teacher and student logits. Specifically, our method first minimizes logit differences within the same sample by considering their numerical values, thus preserving intra-sample similarities. Next, we bridge semantic disparities by leveraging dissimilarities across different samples. Note that constraints on intra-sample similarities and inter-sample dissimilarities can be efficiently and effectively reformulated into a contrastive learning framework with newly designed positive and negative pairs. The positive pair consists of the teacher's and student's logits derived from an identical sample, while the negative pairs are formed by using logits from different samples. With this formulation, our method benefits from the simplicity and efficiency of contrastive learning through the optimization of InfoNCE, yielding a run-time complexity that is far less than $O(n^2)$, where $n$ represents the total number of training samples. Furthermore, our method can eliminate the need for hyperparameter tuning, particularly related to temperature parameters and large batch sizes. We conduct comprehensive experiments on three datasets including CIFAR-100, ImageNet-1K, and MS COCO. Experimental results clearly confirm the effectiveness of the proposed method on both image classification and object detection tasks. Our source codes will be publicly available at https://github.com/wencheng-zhu/CKD.
Read more4/23/2024