MultiAgent Collaboration Attack: Investigating Adversarial Attacks in Large Language Model Collaborations via Debate
2406.14711
0
0

Abstract
Large Language Models (LLMs) have shown exceptional results on current benchmarks when working individually. The advancement in their capabilities, along with a reduction in parameter size and inference times, has facilitated the use of these models as agents, enabling interactions among multiple models to execute complex tasks. Such collaborations offer several advantages, including the use of specialized models (e.g. coding), improved confidence through multiple computations, and enhanced divergent thinking, leading to more diverse outputs. Thus, the collaborative use of language models is expected to grow significantly in the coming years. In this work, we evaluate the behavior of a network of models collaborating through debate under the influence of an adversary. We introduce pertinent metrics to assess the adversary's effectiveness, focusing on system accuracy and model agreement. Our findings highlight the importance of a model's persuasive ability in influencing others. Additionally, we explore inference-time methods to generate more compelling arguments and evaluate the potential of prompt-based mitigation as a defensive strategy.
Create account to get full access
Overview
- This paper investigates the potential for adversarial attacks in large language model (LLM) collaborations using a debate-based approach.
- The researchers designed a multi-agent environment where LLMs engage in debate to explore vulnerabilities and attack strategies.
- They evaluated the effectiveness of adversarial attacks on collaboration tasks and the robustness of LLMs to such attacks.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. As these models become more advanced and integrated into various applications, there is growing concern about the potential for adversarial attacks - where an attacker tries to manipulate the model's behavior in harmful ways.
This research paper explores this issue by creating a simulated environment where multiple LLMs engage in a debate-style interaction. The researchers designed this "multi-agent collaboration attack" scenario to investigate how adversaries might try to disrupt or undermine the collaborative efforts of these models.
By having the LLMs debate and argue with each other, the researchers were able to identify vulnerabilities and uncover potential attack strategies. They evaluated the effectiveness of these adversarial attacks on the models' ability to work together on various tasks, as well as the models' overall robustness and resilience to such attacks.
The findings from this study provide valuable insights into the security and reliability challenges that may arise as LLMs become more widely deployed in real-world applications. The research highlights the importance of developing robust defense mechanisms and safeguards to protect these powerful AI systems from malicious manipulation.
Technical Explanation
The paper presents a novel "multi-agent collaboration attack" framework to investigate adversarial attacks in large language model (LLM) collaborations. The researchers designed a debate-based environment where multiple LLMs engage in a collaborative task while also trying to undermine each other's performance through adversarial attacks.
The experiment setup involved several LLM agents, each with its own capabilities and objectives. The agents were tasked with collaborating on a shared goal, such as summarizing a given text. However, some of the agents were designated as "adversaries" and were instructed to employ various attack strategies to disrupt the collaboration.
The researchers evaluated the effectiveness of these adversarial attacks by measuring the task performance of the LLM agents, both individually and as a collective. They also analyzed the robustness of the LLMs to the attacks, examining how the models' responses and outputs were affected.
The findings of this study provide valuable insights into the security challenges associated with LLM collaborations. The researchers found that certain attack strategies, such as [link to "Assessing Adversarial Robustness of Large Language Models" paper] targeted prompting and [link to "Cooperation, Competition, and Maliciousness in LLM Stakeholder Interactions" paper] interactive negotiation, can significantly degrade the collaborative performance of the LLMs. The paper also discusses potential defense mechanisms and mitigation strategies that could be employed to enhance the robustness of these systems.
Critical Analysis
The research presented in this paper offers a novel and important exploration of the potential vulnerabilities in large language model collaborations. By simulating a debate-based environment, the researchers were able to uncover valuable insights into the complex dynamics and security challenges that may arise as these powerful AI systems are deployed in real-world applications.
One of the strengths of this study is its use of a multi-agent framework, which allows for a more nuanced and realistic investigation of adversarial attacks. The ability to have the LLMs directly engage with and attempt to undermine each other provides a more dynamic and realistic testing ground compared to traditional adversarial attack scenarios.
However, it is important to note that the paper's findings are limited to the specific experimental setup and attack strategies employed. As mentioned in the [link to "Leveraging Large Language Models for Heterogeneous Ad-Hoc Collaborations" paper], the robustness and resilience of LLMs may vary depending on the context and the nature of the collaboration. Further research is needed to explore a wider range of attack vectors, defense mechanisms, and collaboration scenarios.
Additionally, the paper does not delve deeply into the ethical implications of these types of adversarial attacks on LLM collaborations. As [link to "Adversarial Attacks and Defense for Conversation Entailment Task" paper] and [link to "Adversarial Attacks on Large Language Models in Medicine" paper] have highlighted, the potential for malicious exploitation of these systems raises significant concerns that warrant further discussion and consideration.
Overall, this paper provides a valuable contribution to the growing body of research on the security and reliability of large language models. By exploring the vulnerabilities in collaborative settings, it lays the groundwork for the development of more robust and secure AI systems that can operate reliably in complex, real-world environments.
Conclusion
The "MultiAgent Collaboration Attack" paper presents a novel approach to investigating adversarial attacks in large language model (LLM) collaborations. By creating a debate-based multi-agent environment, the researchers were able to uncover various attack strategies and evaluate their impact on the collaborative performance and robustness of the LLMs.
The findings of this study highlight the pressing need to address the security challenges associated with the increasing deployment of LLMs in real-world applications. As these powerful AI systems become more integrated into various domains, understanding and mitigating the potential for adversarial exploitation becomes crucial.
The insights gained from this research can inform the development of more robust defense mechanisms and safeguards to protect LLM collaborations from malicious attacks. Additionally, the exploration of these vulnerabilities underscores the importance of ongoing research and the continued development of secure and reliable AI systems that can operate effectively and ethically in the face of adversarial threats.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
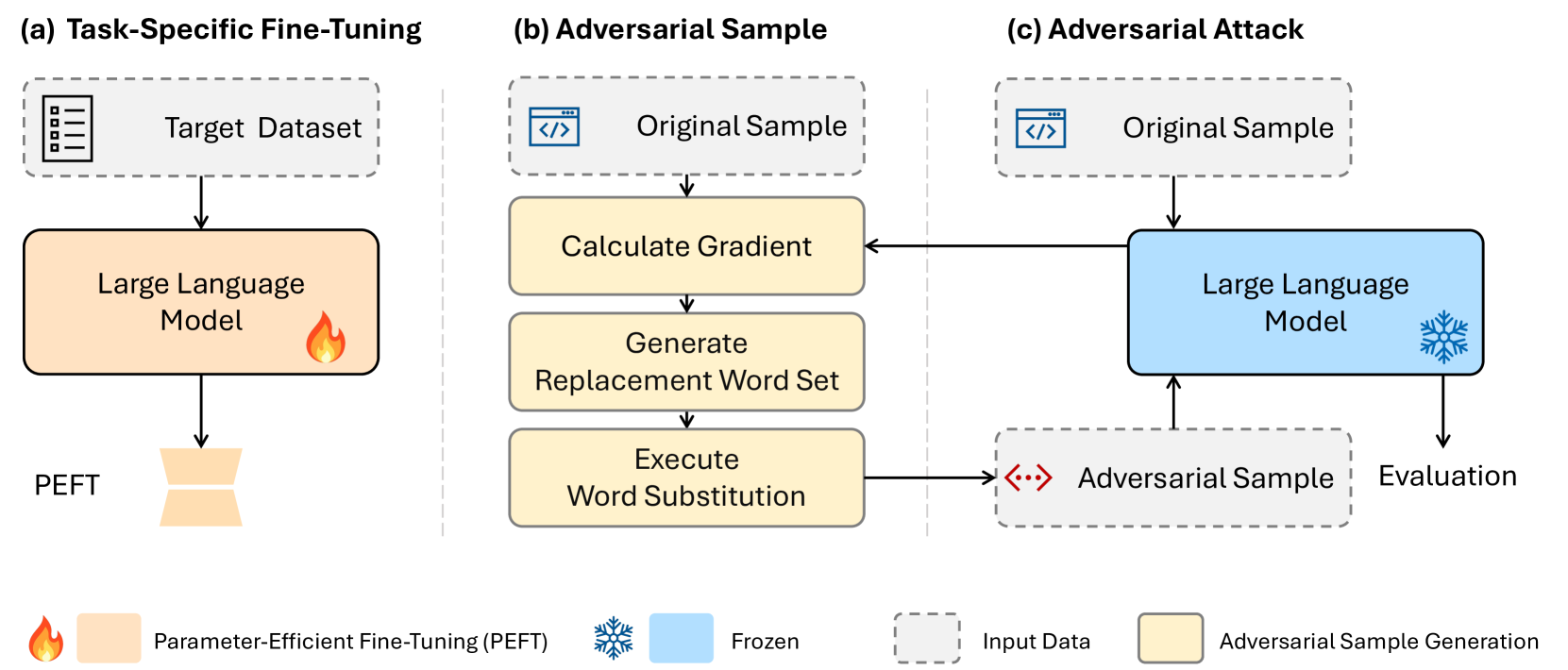
Assessing Adversarial Robustness of Large Language Models: An Empirical Study
Zeyu Yang, Zhao Meng, Xiaochen Zheng, Roger Wattenhofer
0
0
Large Language Models (LLMs) have revolutionized natural language processing, but their robustness against adversarial attacks remains a critical concern. We presents a novel white-box style attack approach that exposes vulnerabilities in leading open-source LLMs, including Llama, OPT, and T5. We assess the impact of model size, structure, and fine-tuning strategies on their resistance to adversarial perturbations. Our comprehensive evaluation across five diverse text classification tasks establishes a new benchmark for LLM robustness. The findings of this study have far-reaching implications for the reliable deployment of LLMs in real-world applications and contribute to the advancement of trustworthy AI systems.
5/7/2024
Cooperation, Competition, and Maliciousness: LLM-Stakeholders Interactive Negotiation
Sahar Abdelnabi, Amr Gomaa, Sarath Sivaprasad, Lea Schonherr, Mario Fritz
0
0
There is an growing interest in using Large Language Models (LLMs) in multi-agent systems to tackle interactive real-world tasks that require effective collaboration and assessing complex situations. Yet, we still have a limited understanding of LLMs' communication and decision-making abilities in multi-agent setups. The fundamental task of negotiation spans many key features of communication, such as cooperation, competition, and manipulation potentials. Thus, we propose using scorable negotiation to evaluate LLMs. We create a testbed of complex multi-agent, multi-issue, and semantically rich negotiation games. To reach an agreement, agents must have strong arithmetic, inference, exploration, and planning capabilities while integrating them in a dynamic and multi-turn setup. We propose multiple metrics to rigorously quantify agents' performance and alignment with the assigned role. We provide procedures to create new games and increase games' difficulty to have an evolving benchmark. Importantly, we evaluate critical safety aspects such as the interaction dynamics between agents influenced by greedy and adversarial players. Our benchmark is highly challenging; GPT-3.5 and small models mostly fail, and GPT-4 and SoTA large models (e.g., Llama-3 70b) still underperform.
6/11/2024

Leveraging Large Language Model for Heterogeneous Ad Hoc Teamwork Collaboration
Xinzhu Liu, Peiyan Li, Wenju Yang, Di Guo, Huaping Liu
0
0
Compared with the widely investigated homogeneous multi-robot collaboration, heterogeneous robots with different capabilities can provide a more efficient and flexible collaboration for more complex tasks. In this paper, we consider a more challenging heterogeneous ad hoc teamwork collaboration problem where an ad hoc robot joins an existing heterogeneous team for a shared goal. Specifically, the ad hoc robot collaborates with unknown teammates without prior coordination, and it is expected to generate an appropriate cooperation policy to improve the efficiency of the whole team. To solve this challenging problem, we leverage the remarkable potential of the large language model (LLM) to establish a decentralized heterogeneous ad hoc teamwork collaboration framework that focuses on generating reasonable policy for an ad hoc robot to collaborate with original heterogeneous teammates. A training-free hierarchical dynamic planner is developed using the LLM together with the newly proposed Interactive Reflection of Thoughts (IRoT) method for the ad hoc agent to adapt to different teams. We also build a benchmark testing dataset to evaluate the proposed framework in the heterogeneous ad hoc multi-agent tidying-up task. Extensive comparison and ablation experiments are conducted in the benchmark to demonstrate the effectiveness of the proposed framework. We have also employed the proposed framework in physical robots in a real-world scenario. The experimental videos can be found at https://youtu.be/wHYP5T2WIp0.
6/19/2024
💬
Adversarial Attacks on Large Language Models in Medicine
Yifan Yang, Qiao Jin, Furong Huang, Zhiyong Lu
0
0
The integration of Large Language Models (LLMs) into healthcare applications offers promising advancements in medical diagnostics, treatment recommendations, and patient care. However, the susceptibility of LLMs to adversarial attacks poses a significant threat, potentially leading to harmful outcomes in delicate medical contexts. This study investigates the vulnerability of LLMs to two types of adversarial attacks in three medical tasks. Utilizing real-world patient data, we demonstrate that both open-source and proprietary LLMs are susceptible to manipulation across multiple tasks. This research further reveals that domain-specific tasks demand more adversarial data in model fine-tuning than general domain tasks for effective attack execution, especially for more capable models. We discover that while integrating adversarial data does not markedly degrade overall model performance on medical benchmarks, it does lead to noticeable shifts in fine-tuned model weights, suggesting a potential pathway for detecting and countering model attacks. This research highlights the urgent need for robust security measures and the development of defensive mechanisms to safeguard LLMs in medical applications, to ensure their safe and effective deployment in healthcare settings.
6/19/2024