MultiConfederated Learning: Inclusive Non-IID Data handling with Decentralized Federated Learning
2404.13421
0
0

Abstract
Federated Learning (FL) has emerged as a prominent privacy-preserving technique for enabling use cases like confidential clinical machine learning. FL operates by aggregating models trained by remote devices which owns the data. Thus, FL enables the training of powerful global models using crowd-sourced data from a large number of learners, without compromising their privacy. However, the aggregating server is a single point of failure when generating the global model. Moreover, the performance of the model suffers when the data is not independent and identically distributed (non-IID data) on all remote devices. This leads to vastly different models being aggregated, which can reduce the performance by as much as 50% in certain scenarios. In this paper, we seek to address the aforementioned issues while retaining the benefits of FL. We propose MultiConfederated Learning: a decentralized FL framework which is designed to handle non-IID data. Unlike traditional FL, MultiConfederated Learning will maintain multiple models in parallel (instead of a single global model) to help with convergence when the data is non-IID. With the help of transfer learning, learners can converge to fewer models. In order to increase adaptability, learners are allowed to choose which updates to aggregate from their peers.
Create account to get full access
Overview
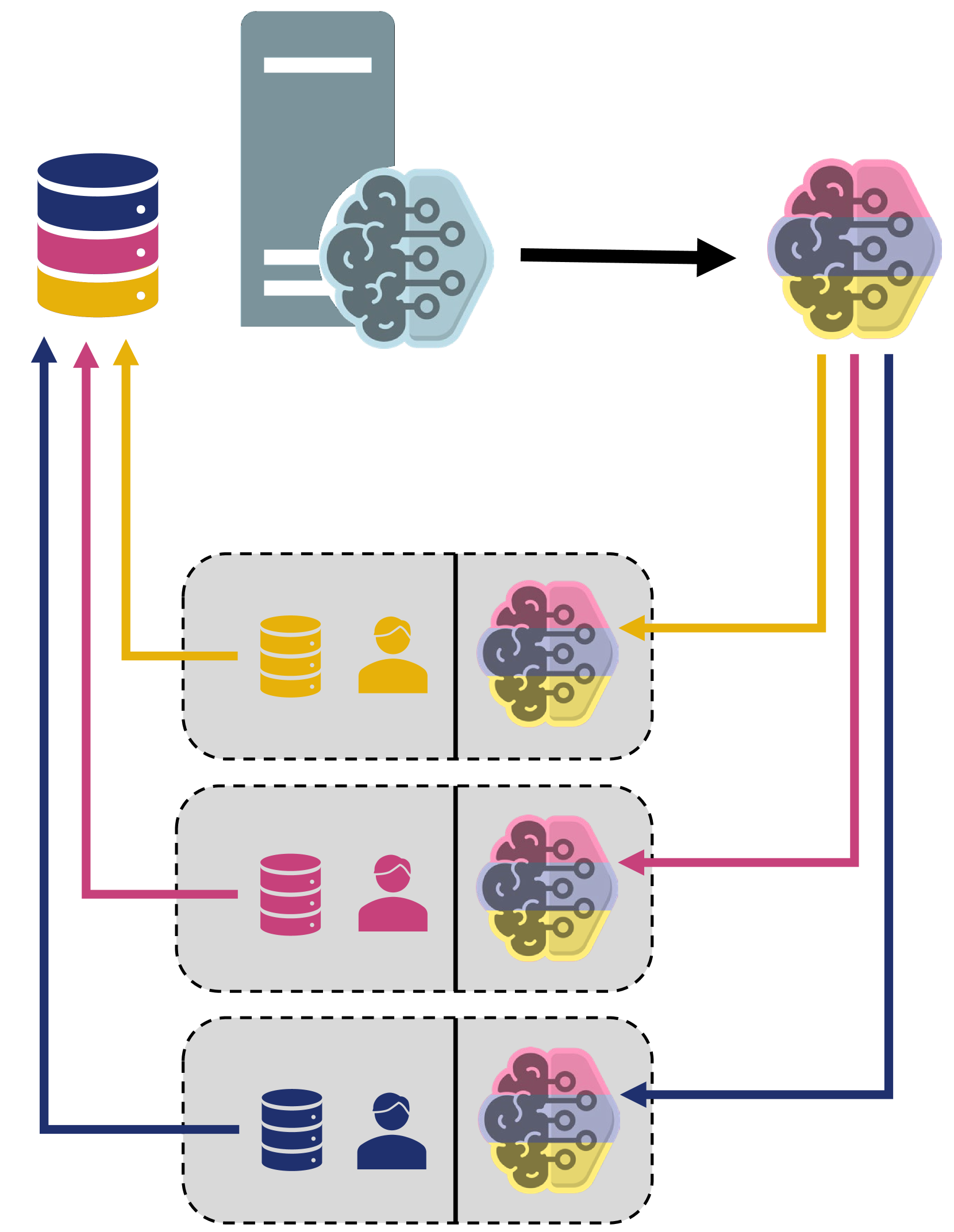
- Presents a new approach called "MultiConfederated Learning" for decentralized federated learning with non-IID (non-independently and identically distributed) data
- Aims to address challenges in handling heterogeneous data across multiple federated groups or "confederations"
- Introduces a weight divergence metric to measure the distribution shift between local models and the global model
Plain English Explanation
"MultiConfederated Learning" is a new technique for training machine learning models in a decentralized way, while dealing with the challenge of having different types of data across multiple locations or "confederations". In traditional federated learning, all the devices or participants share a single global model. However, when the data on these devices is very different (non-IID), this can lead to problems.
The key idea of this paper is to allow for multiple "confederations" or groups, each with their own global model. This way, devices within a confederation can collaborate more effectively, since their data is more similar. The paper also introduces a way to measure how much the local models within a confederation differ from the confederation's global model, which can help monitor and address these differences.
This approach aims to make federated learning work better when the participating devices have very diverse data, which is common in real-world applications. By enabling more localized collaboration, it can lead to better model performance compared to a one-size-fits-all global model.
Technical Explanation
The paper proposes a "MultiConfederated Learning" framework to handle non-IID data in decentralized federated learning. Unlike standard federated learning which uses a single global model, this approach allows for multiple "confederations" or groups, each with their own global model.
Within each confederation, devices collaborate to train their local models, which are then aggregated into the confederation's global model. The authors introduce a "weight divergence" metric to measure the difference between each local model and the confederation's global model. This helps identify and address cases where local models are diverging too much from the global one.
The paper evaluates this approach on various non-IID image classification and language modeling tasks. The results show that MultiConfederated Learning can outperform standard federated learning, particularly as the data heterogeneity increases across devices. The authors also demonstrate the ability to dynamically adjust the number of confederations based on the observed weight divergence.
Critical Analysis
The MultiConfederated Learning approach presented in this paper is a promising step towards making federated learning more robust to non-IID data distributions across devices. By allowing for multiple collaborative groups, it can better accommodate the real-world scenario of devices having very diverse data.
However, the paper does not deeply explore the trade-offs involved in this approach. For example, it's unclear how the number of confederations should be chosen in practice, and what impact this has on overall performance and convergence. Additionally, the weight divergence metric may not fully capture all relevant aspects of model drift in heterogeneous settings.
Further research is needed to understand the optimal confederation formation and management strategies, as well as to explore alternative ways of measuring and mitigating the challenges of non-IID data in federated learning. Rigorous evaluations on large-scale, real-world datasets would also help validate the practical benefits of this approach.
Conclusion
The MultiConfederated Learning framework introduced in this paper represents an important advancement in addressing the challenge of non-IID data in decentralized federated learning. By enabling multiple collaborative groups, each with their own global model, it can better accommodate diverse data distributions across devices.
The weight divergence metric and dynamic confederation adjustment proposed in the paper are useful tools for monitoring and managing these heterogeneous settings. While further research is needed to fully understand the trade-offs and optimal strategies, this work is a valuable contribution towards making federated learning more inclusive and effective in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Federated Learning: A Cutting-Edge Survey of the Latest Advancements and Applications
Azim Akhtarshenas, Mohammad Ali Vahedifar, Navid Ayoobi, Behrouz Maham, Tohid Alizadeh, Sina Ebrahimi, David L'opez-P'erez
0
0
Robust machine learning (ML) models can be developed by leveraging large volumes of data and distributing the computational tasks across numerous devices or servers. Federated learning (FL) is a technique in the realm of ML that facilitates this goal by utilizing cloud infrastructure to enable collaborative model training among a network of decentralized devices. Beyond distributing the computational load, FL targets the resolution of privacy issues and the reduction of communication costs simultaneously. To protect user privacy, FL requires users to send model updates rather than transmitting large quantities of raw and potentially confidential data. Specifically, individuals train ML models locally using their own data and then upload the results in the form of weights and gradients to the cloud for aggregation into the global model. This strategy is also advantageous in environments with limited bandwidth or high communication costs, as it prevents the transmission of large data volumes. With the increasing volume of data and rising privacy concerns, alongside the emergence of large-scale ML models like Large Language Models (LLMs), FL presents itself as a timely and relevant solution. It is therefore essential to review current FL algorithms to guide future research that meets the rapidly evolving ML demands. This survey provides a comprehensive analysis and comparison of the most recent FL algorithms, evaluating them on various fronts including mathematical frameworks, privacy protection, resource allocation, and applications. Beyond summarizing existing FL methods, this survey identifies potential gaps, open areas, and future challenges based on the performance reports and algorithms used in recent studies. This survey enables researchers to readily identify existing limitations in the FL field for further exploration.
5/28/2024
📈
MH-pFLID: Model Heterogeneous personalized Federated Learning via Injection and Distillation for Medical Data Analysis
Luyuan Xie, Manqing Lin, Tianyu Luan, Cong Li, Yuejian Fang, Qingni Shen, Zhonghai Wu
0
0
Federated learning is widely used in medical applications for training global models without needing local data access. However, varying computational capabilities and network architectures (system heterogeneity), across clients pose significant challenges in effectively aggregating information from non-independently and identically distributed (non-IID) data. Current federated learning methods using knowledge distillation require public datasets, raising privacy and data collection issues. Additionally, these datasets require additional local computing and storage resources, which is a burden for medical institutions with limited hardware conditions. In this paper, we introduce a novel federated learning paradigm, named Model Heterogeneous personalized Federated Learning via Injection and Distillation (MH-pFLID). Our framework leverages a lightweight messenger model that carries concentrated information to collect the information from each client. We also develop a set of receiver and transmitter modules to receive and send information from the messenger model, so that the information could be injected and distilled with efficiency.
5/14/2024
Fed-Credit: Robust Federated Learning with Credibility Management
Jiayan Chen, Zhirong Qian, Tianhui Meng, Xitong Gao, Tian Wang, Weijia Jia
0
0
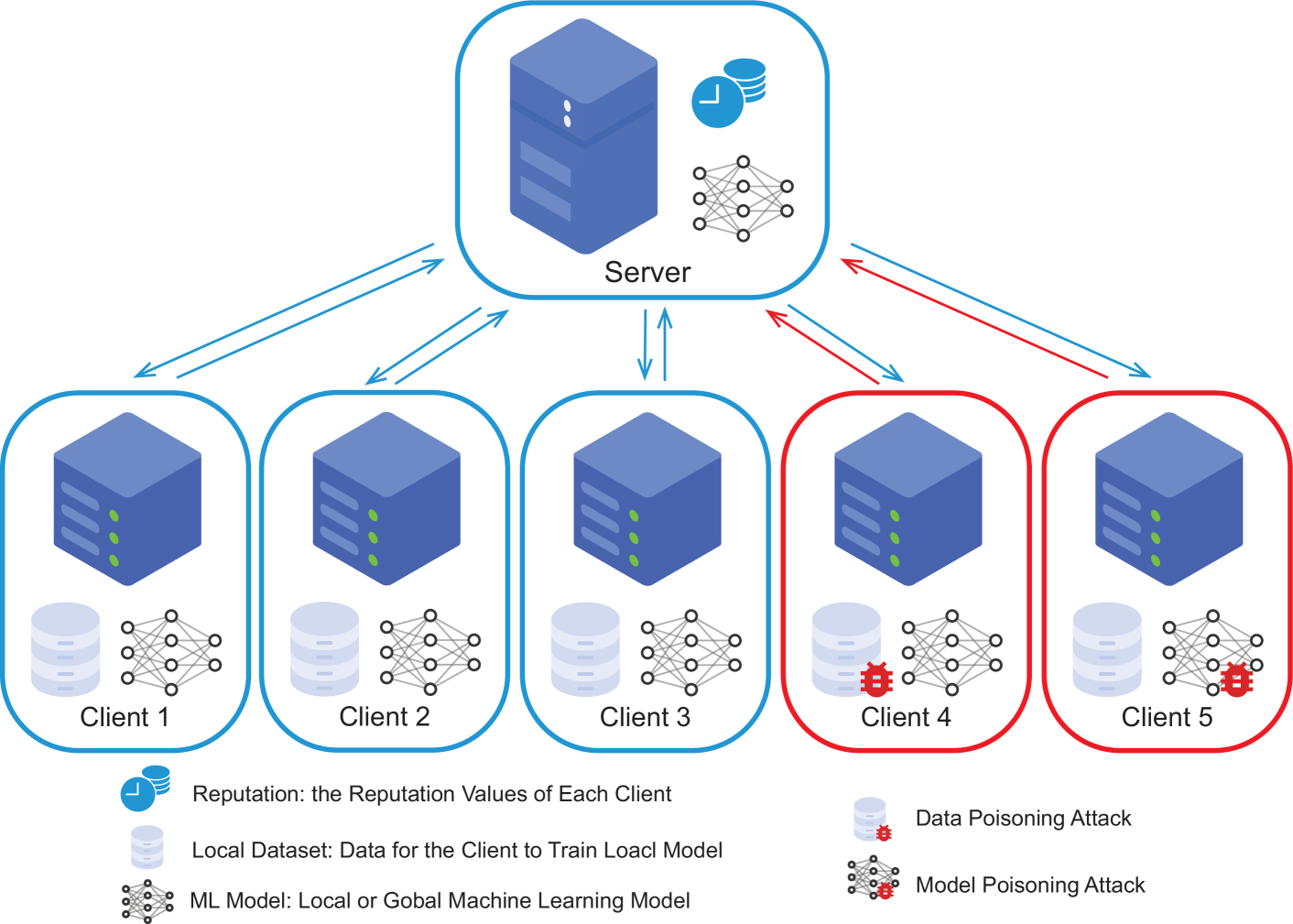
Aiming at privacy preservation, Federated Learning (FL) is an emerging machine learning approach enabling model training on decentralized devices or data sources. The learning mechanism of FL relies on aggregating parameter updates from individual clients. However, this process may pose a potential security risk due to the presence of malicious devices. Existing solutions are either costly due to the use of compute-intensive technology, or restrictive for reasons of strong assumptions such as the prior knowledge of the number of attackers and how they attack. Few methods consider both privacy constraints and uncertain attack scenarios. In this paper, we propose a robust FL approach based on the credibility management scheme, called Fed-Credit. Unlike previous studies, our approach does not require prior knowledge of the nodes and the data distribution. It maintains and employs a credibility set, which weighs the historical clients' contributions based on the similarity between the local models and global model, to adjust the global model update. The subtlety of Fed-Credit is that the time decay and attitudinal value factor are incorporated into the dynamic adjustment of the reputation weights and it boasts a computational complexity of O(n) (n is the number of the clients). We conducted extensive experiments on the MNIST and CIFAR-10 datasets under 5 types of attacks. The results exhibit superior accuracy and resilience against adversarial attacks, all while maintaining comparatively low computational complexity. Among these, on the Non-IID CIFAR-10 dataset, our algorithm exhibited performance enhancements of 19.5% and 14.5%, respectively, in comparison to the state-of-the-art algorithm when dealing with two types of data poisoning attacks.
5/21/2024

One-Shot Sequential Federated Learning for Non-IID Data by Enhancing Local Model Diversity
Naibo Wang, Yuchen Deng, Wenjie Feng, Shichen Fan, Jianwei Yin, See-Kiong Ng
0
0
Traditional federated learning mainly focuses on parallel settings (PFL), which can suffer significant communication and computation costs. In contrast, one-shot and sequential federated learning (SFL) have emerged as innovative paradigms to alleviate these costs. However, the issue of non-IID (Independent and Identically Distributed) data persists as a significant challenge in one-shot and SFL settings, exacerbated by the restricted communication between clients. In this paper, we improve the one-shot sequential federated learning for non-IID data by proposing a local model diversity-enhancing strategy. Specifically, to leverage the potential of local model diversity for improving model performance, we introduce a local model pool for each client that comprises diverse models generated during local training, and propose two distance measurements to further enhance the model diversity and mitigate the effect of non-IID data. Consequently, our proposed framework can improve the global model performance while maintaining low communication costs. Extensive experiments demonstrate that our method exhibits superior performance to existing one-shot PFL methods and achieves better accuracy compared with state-of-the-art one-shot SFL methods on both label-skew and domain-shift tasks (e.g., 6%+ accuracy improvement on the CIFAR-10 dataset).
4/19/2024