MH-pFLID: Model Heterogeneous personalized Federated Learning via Injection and Distillation for Medical Data Analysis
2405.06822
0
0
📈
Abstract
Federated learning is widely used in medical applications for training global models without needing local data access. However, varying computational capabilities and network architectures (system heterogeneity), across clients pose significant challenges in effectively aggregating information from non-independently and identically distributed (non-IID) data. Current federated learning methods using knowledge distillation require public datasets, raising privacy and data collection issues. Additionally, these datasets require additional local computing and storage resources, which is a burden for medical institutions with limited hardware conditions. In this paper, we introduce a novel federated learning paradigm, named Model Heterogeneous personalized Federated Learning via Injection and Distillation (MH-pFLID). Our framework leverages a lightweight messenger model that carries concentrated information to collect the information from each client. We also develop a set of receiver and transmitter modules to receive and send information from the messenger model, so that the information could be injected and distilled with efficiency.
Create account to get full access
Overview
- This paper presents the appendix of a study on Heterogeneous Multi-task Federated Learning with Implicit Diversity (HM-FLID), which is a novel federated learning framework.
- The appendix covers additional details and experiments that complement the main paper.
Plain English Explanation
The main paper introduced HM-FLID, a new approach to federated learning that can handle data heterogeneity across devices. This appendix provides more information to support the claims made in the main paper.
For example, it includes a review of related work in the field of federated learning and model distillation. It also describes the baseline methods used for comparison, as well as details about the datasets employed in the experiments. Additionally, it delves deeper into the experimental setup and results, offering a more comprehensive understanding of the proposed HM-FLID approach and its performance.
Technical Explanation
The appendix begins with a Related Works Supplement that provides an overview of prior research relevant to the HM-FLID framework. This includes work on federated learning and model distillation, as well as approaches for handling data heterogeneity in federated settings.
The next section, Baselines, describes the benchmark methods used to evaluate the performance of HM-FLID. These include standard federated learning algorithms, as well as personalized and multi-task variants, to provide a comprehensive comparison.
The Datasets section outlines the characteristics of the real-world datasets used in the experiments, including details on the level of data heterogeneity and task diversity.
Finally, the Experimental Details section delves deeper into the experimental setup and results. It provides additional information on the model architectures, hyperparameter tuning, and training procedures used in the evaluation of HM-FLID and the baseline methods.
Critical Analysis
The appendix provides valuable supplementary information to support the claims made in the main paper. By including a detailed review of related work, a comprehensive set of baseline methods, and a thorough description of the experimental setup, the authors demonstrate a robust and well-designed study.
However, the appendix does not address any potential limitations or caveats of the HM-FLID approach. While the extensive experimentation provides a strong foundation, there may be scenarios or dataset characteristics where the performance of HM-FLID could be less favorable, and these aspects are not explicitly discussed.
Additionally, the appendix could have included a more critical analysis of the results, highlighting areas where HM-FLID outperforms the baselines and exploring potential reasons for its success. This could have provided deeper insights into the strengths and weaknesses of the proposed framework.
Conclusion
The appendix of the HM-FLID paper provides a comprehensive supplement to the main research, covering additional details and experiments that support the claims made in the original paper. By delving into the related work, baselines, datasets, and experimental setup, the authors have created a thorough and transparent documentation of their research.
While the appendix does not address potential limitations or caveats of the HM-FLID approach, the extensive experimentation and detailed reporting contribute to the overall quality and credibility of the study. The insights gained from this appendix can help researchers and practitioners better understand the capabilities and applications of the HM-FLID framework in federated learning scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
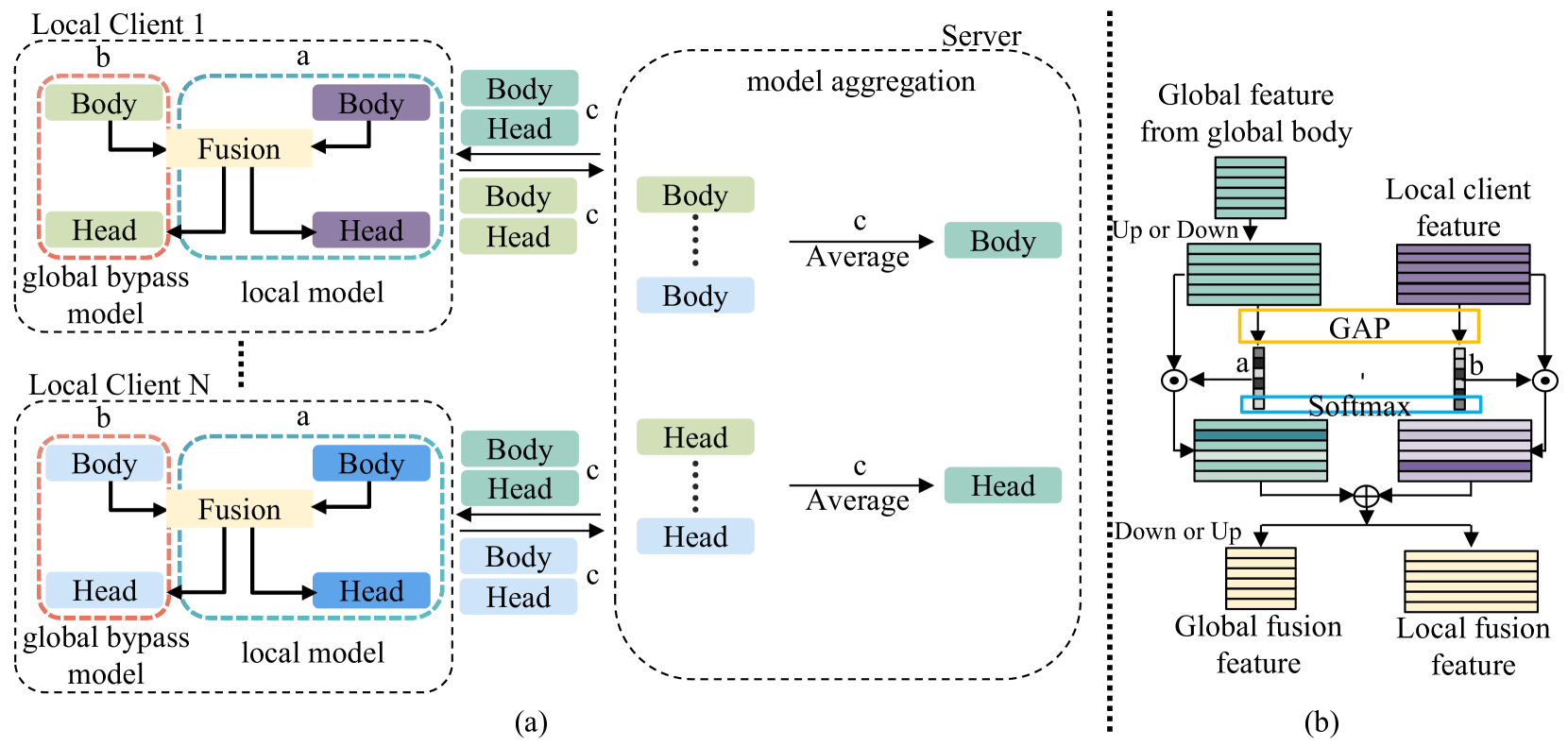
New!MH-pFLGB: Model Heterogeneous personalized Federated Learning via Global Bypass for Medical Image Analysis
Luyuan Xie, Manqing Lin, ChenMing Xu, Tianyu Luan, Zhipeng Zeng, Wenjun Qian, Cong Li, Yuejian Fang, Qingni Shen, Zhonghai Wu
0
0
In the evolving application of medical artificial intelligence, federated learning is notable for its ability to protect training data privacy. Federated learning facilitates collaborative model development without the need to share local data from healthcare institutions. Yet, the statistical and system heterogeneity among these institutions poses substantial challenges, which affects the effectiveness of federated learning and hampers the exchange of information between clients. To address these issues, we introduce a novel approach, MH-pFLGB, which employs a global bypass strategy to mitigate the reliance on public datasets and navigate the complexities of non-IID data distributions. Our method enhances traditional federated learning by integrating a global bypass model, which would share the information among the clients, but also serves as part of the network to enhance the performance on each client. Additionally, MH-pFLGB provides a feature fusion module to better combine the local and global features. We validate model{}'s effectiveness and adaptability through extensive testing on different medical tasks, demonstrating superior performance compared to existing state-of-the-art methods.
7/2/2024

Federated Distillation: A Survey
Lin Li, Jianping Gou, Baosheng Yu, Lan Du, Zhang Yiand Dacheng Tao
0
0
Federated Learning (FL) seeks to train a model collaboratively without sharing private training data from individual clients. Despite its promise, FL encounters challenges such as high communication costs for large-scale models and the necessity for uniform model architectures across all clients and the server. These challenges severely restrict the practical applications of FL. To address these limitations, the integration of knowledge distillation (KD) into FL has been proposed, forming what is known as Federated Distillation (FD). FD enables more flexible knowledge transfer between clients and the server, surpassing the mere sharing of model parameters. By eliminating the need for identical model architectures across clients and the server, FD mitigates the communication costs associated with training large-scale models. This paper aims to offer a comprehensive overview of FD, highlighting its latest advancements. It delves into the fundamental principles underlying the design of FD frameworks, delineates FD approaches for tackling various challenges, and provides insights into the diverse applications of FD across different scenarios.
4/15/2024
📊
Multi-level Personalized Federated Learning on Heterogeneous and Long-Tailed Data
Rongyu Zhang, Yun Chen, Chenrui Wu, Fangxin Wang, Bo Li
0
0
Federated learning (FL) offers a privacy-centric distributed learning framework, enabling model training on individual clients and central aggregation without necessitating data exchange. Nonetheless, FL implementations often suffer from non-i.i.d. and long-tailed class distributions across mobile applications, e.g., autonomous vehicles, which leads models to overfitting as local training may converge to sub-optimal. In our study, we explore the impact of data heterogeneity on model bias and introduce an innovative personalized FL framework, Multi-level Personalized Federated Learning (MuPFL), which leverages the hierarchical architecture of FL to fully harness computational resources at various levels. This framework integrates three pivotal modules: Biased Activation Value Dropout (BAVD) to mitigate overfitting and accelerate training; Adaptive Cluster-based Model Update (ACMU) to refine local models ensuring coherent global aggregation; and Prior Knowledge-assisted Classifier Fine-tuning (PKCF) to bolster classification and personalize models in accord with skewed local data with shared knowledge. Extensive experiments on diverse real-world datasets for image classification and semantic segmentation validate that MuPFL consistently outperforms state-of-the-art baselines, even under extreme non-i.i.d. and long-tail conditions, which enhances accuracy by as much as 7.39% and accelerates training by up to 80% at most, marking significant advancements in both efficiency and effectiveness.
5/13/2024

MultiConfederated Learning: Inclusive Non-IID Data handling with Decentralized Federated Learning
Michael Duchesne, Kaiwen Zhang, Chamseddine Talhi
0
0
Federated Learning (FL) has emerged as a prominent privacy-preserving technique for enabling use cases like confidential clinical machine learning. FL operates by aggregating models trained by remote devices which owns the data. Thus, FL enables the training of powerful global models using crowd-sourced data from a large number of learners, without compromising their privacy. However, the aggregating server is a single point of failure when generating the global model. Moreover, the performance of the model suffers when the data is not independent and identically distributed (non-IID data) on all remote devices. This leads to vastly different models being aggregated, which can reduce the performance by as much as 50% in certain scenarios. In this paper, we seek to address the aforementioned issues while retaining the benefits of FL. We propose MultiConfederated Learning: a decentralized FL framework which is designed to handle non-IID data. Unlike traditional FL, MultiConfederated Learning will maintain multiple models in parallel (instead of a single global model) to help with convergence when the data is non-IID. With the help of transfer learning, learners can converge to fewer models. In order to increase adaptability, learners are allowed to choose which updates to aggregate from their peers.
4/23/2024