MultifacetEval: Multifaceted Evaluation to Probe LLMs in Mastering Medical Knowledge

0
Sign in to get full access
Overview
• This paper, titled "MultifacetEval: Multifaceted Evaluation to Probe LLMs in Mastering Medical Knowledge", explores a comprehensive approach to evaluating how well large language models (LLMs) can handle medical knowledge and tasks.
• The researchers developed a multifaceted evaluation framework called MultifacetEval that assesses LLMs across various dimensions, including factual knowledge, reasoning, and interaction with doctors.
• This research builds on previous work on evaluating LLMs for medical applications, such as MedExpQA and Worse Than Random.
Plain English Explanation
The paper explores how well large language models, which are powerful AI systems trained on massive amounts of text, can handle medical knowledge and tasks. The researchers developed a comprehensive evaluation framework called MultifacetEval that looks at different aspects of the models' performance, such as their factual knowledge, reasoning abilities, and interactions with doctors.
This is important because as LLMs become more advanced, they are being considered for use in medical applications, like assisting doctors or answering patient questions. But it's crucial to thoroughly evaluate how well they can actually handle medical information and tasks before deploying them in real-world healthcare settings.
The MultifacetEval framework builds on previous research in this area, like the MedExpQA and Worse Than Random studies, which also looked at evaluating LLMs for medical applications.
Technical Explanation
The MultifacetEval framework comprises several evaluation tasks designed to probe LLMs' mastery of medical knowledge and skills. These tasks include:
- Factual Knowledge: Assessing the models' ability to recall and apply medical facts and concepts.
- Reasoning: Evaluating the models' capacity to draw logical inferences and make informed decisions based on medical information.
- Doctor-Patient Interaction: Analyzing how the models perform in simulated doctor-patient dialogues, including their ability to understand context, ask relevant questions, and provide appropriate responses.
The researchers tested several prominent LLMs, including GPT-3, PaLM, and Megatron-Turing NLG, on these evaluation tasks. By comparing the models' performance across the different facets, the researchers were able to gain a more comprehensive understanding of their strengths, weaknesses, and overall suitability for medical applications.
Critical Analysis
The MultifacetEval framework provides a valuable and thorough approach to evaluating LLMs in the medical domain. However, the paper also acknowledges some limitations and areas for further research:
- The evaluation tasks, while comprehensive, may not fully capture the complexity and nuance of real-world medical scenarios. Continued refinement and expansion of the evaluation tasks may be necessary.
- The paper focuses on a limited set of prominent LLMs, and it would be beneficial to extend the evaluation to a wider range of models, including those developed by different organizations and for specialized medical applications.
- While the paper highlights the models' performance gaps, it does not provide in-depth analysis of the specific underlying issues or potential solutions. Further research could delve deeper into the root causes of the models' shortcomings.
Additionally, some readers may raise questions about the generalizability of the findings, as the evaluation was conducted on a specific set of tasks and models. Ongoing monitoring and adaptation of the MultifacetEval framework will be crucial as the field of large language models continues to evolve.
Conclusion
The MultifacetEval framework represents a significant step forward in the evaluation of LLMs for medical applications. By assessing the models' performance across multiple facets, including factual knowledge, reasoning, and doctor-patient interaction, the researchers have provided valuable insights into the current capabilities and limitations of these powerful AI systems.
As LLMs become increasingly prominent in various domains, including healthcare, the need for comprehensive and rigorous evaluation frameworks like MultifacetEval will only grow. The findings from this research can inform the development of more robust and reliable medical AI systems, ultimately contributing to improved patient care and outcomes.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MultifacetEval: Multifaceted Evaluation to Probe LLMs in Mastering Medical Knowledge
Yuxuan Zhou, Xien Liu, Chen Ning, Ji Wu
Large language models (LLMs) have excelled across domains, also delivering notable performance on the medical evaluation benchmarks, such as MedQA. However, there still exists a significant gap between the reported performance and the practical effectiveness in real-world medical scenarios. In this paper, we aim to explore the causes of this gap by employing a multifaceted examination schema to systematically probe the actual mastery of medical knowledge by current LLMs. Specifically, we develop a novel evaluation framework MultifacetEval to examine the degree and coverage of LLMs in encoding and mastering medical knowledge at multiple facets (comparison, rectification, discrimination, and verification) concurrently. Based on the MultifacetEval framework, we construct two multifaceted evaluation datasets: MultiDiseK (by producing questions from a clinical disease knowledge base) and MultiMedQA (by rephrasing each question from a medical benchmark MedQA into multifaceted questions). The experimental results on these multifaceted datasets demonstrate that the extent of current LLMs in mastering medical knowledge is far below their performance on existing medical benchmarks, suggesting that they lack depth, precision, and comprehensiveness in mastering medical knowledge. Consequently, current LLMs are not yet ready for application in real-world medical tasks. The codes and datasets are available at https://github.com/THUMLP/MultifacetEval.
Read more6/6/2024
🤿
0
MEDIC: Towards a Comprehensive Framework for Evaluating LLMs in Clinical Applications
Praveen K Kanithi, Cl'ement Christophe, Marco AF Pimentel, Tathagata Raha, Nada Saadi, Hamza Javed, Svetlana Maslenkova, Nasir Hayat, Ronnie Rajan, Shadab Khan
The rapid development of Large Language Models (LLMs) for healthcare applications has spurred calls for holistic evaluation beyond frequently-cited benchmarks like USMLE, to better reflect real-world performance. While real-world assessments are valuable indicators of utility, they often lag behind the pace of LLM evolution, likely rendering findings obsolete upon deployment. This temporal disconnect necessitates a comprehensive upfront evaluation that can guide model selection for specific clinical applications. We introduce MEDIC, a framework assessing LLMs across five critical dimensions of clinical competence: medical reasoning, ethics and bias, data and language understanding, in-context learning, and clinical safety. MEDIC features a novel cross-examination framework quantifying LLM performance across areas like coverage and hallucination detection, without requiring reference outputs. We apply MEDIC to evaluate LLMs on medical question-answering, safety, summarization, note generation, and other tasks. Our results show performance disparities across model sizes, baseline vs medically finetuned models, and have implications on model selection for applications requiring specific model strengths, such as low hallucination or lower cost of inference. MEDIC's multifaceted evaluation reveals these performance trade-offs, bridging the gap between theoretical capabilities and practical implementation in healthcare settings, ensuring that the most promising models are identified and adapted for diverse healthcare applications.
Read more9/12/2024
💬
0
Evaluating large language models in medical applications: a survey
Xiaolan Chen, Jiayang Xiang, Shanfu Lu, Yexin Liu, Mingguang He, Danli Shi
Large language models (LLMs) have emerged as powerful tools with transformative potential across numerous domains, including healthcare and medicine. In the medical domain, LLMs hold promise for tasks ranging from clinical decision support to patient education. However, evaluating the performance of LLMs in medical contexts presents unique challenges due to the complex and critical nature of medical information. This paper provides a comprehensive overview of the landscape of medical LLM evaluation, synthesizing insights from existing studies and highlighting evaluation data sources, task scenarios, and evaluation methods. Additionally, it identifies key challenges and opportunities in medical LLM evaluation, emphasizing the need for continued research and innovation to ensure the responsible integration of LLMs into clinical practice.
Read more5/14/2024
0
MedExpQA: Multilingual Benchmarking of Large Language Models for Medical Question Answering
I~nigo Alonso, Maite Oronoz, Rodrigo Agerri
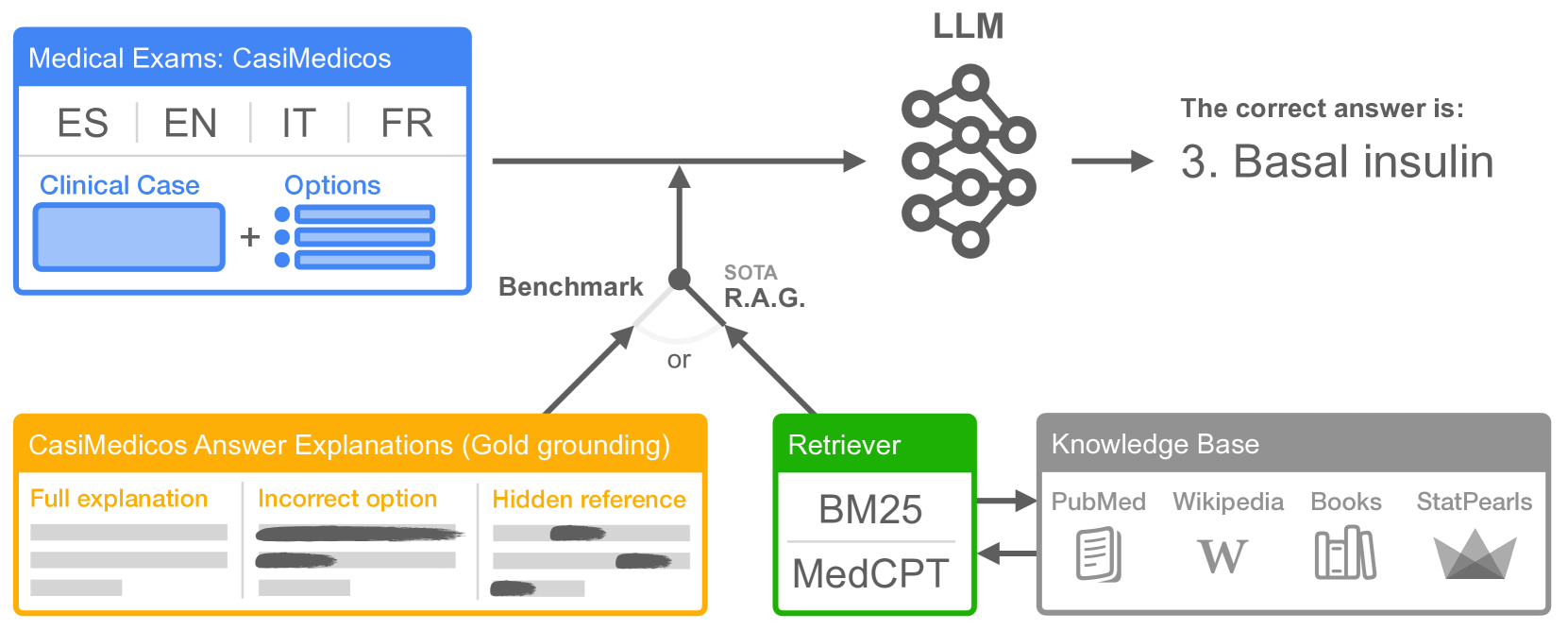
Large Language Models (LLMs) have the potential of facilitating the development of Artificial Intelligence technology to assist medical experts for interactive decision support, which has been demonstrated by their competitive performances in Medical QA. However, while impressive, the required quality bar for medical applications remains far from being achieved. Currently, LLMs remain challenged by outdated knowledge and by their tendency to generate hallucinated content. Furthermore, most benchmarks to assess medical knowledge lack reference gold explanations which means that it is not possible to evaluate the reasoning of LLMs predictions. Finally, the situation is particularly grim if we consider benchmarking LLMs for languages other than English which remains, as far as we know, a totally neglected topic. In order to address these shortcomings, in this paper we present MedExpQA, the first multilingual benchmark based on medical exams to evaluate LLMs in Medical Question Answering. To the best of our knowledge, MedExpQA includes for the first time reference gold explanations written by medical doctors which can be leveraged to establish various gold-based upper-bounds for comparison with LLMs performance. Comprehensive multilingual experimentation using both the gold reference explanations and Retrieval Augmented Generation (RAG) approaches show that performance of LLMs still has large room for improvement, especially for languages other than English. Furthermore, and despite using state-of-the-art RAG methods, our results also demonstrate the difficulty of obtaining and integrating readily available medical knowledge that may positively impact results on downstream evaluations for Medical Question Answering. So far the benchmark is available in four languages, but we hope that this work may encourage further development to other languages.
Read more7/30/2024